imagen pytorch
2.1.0
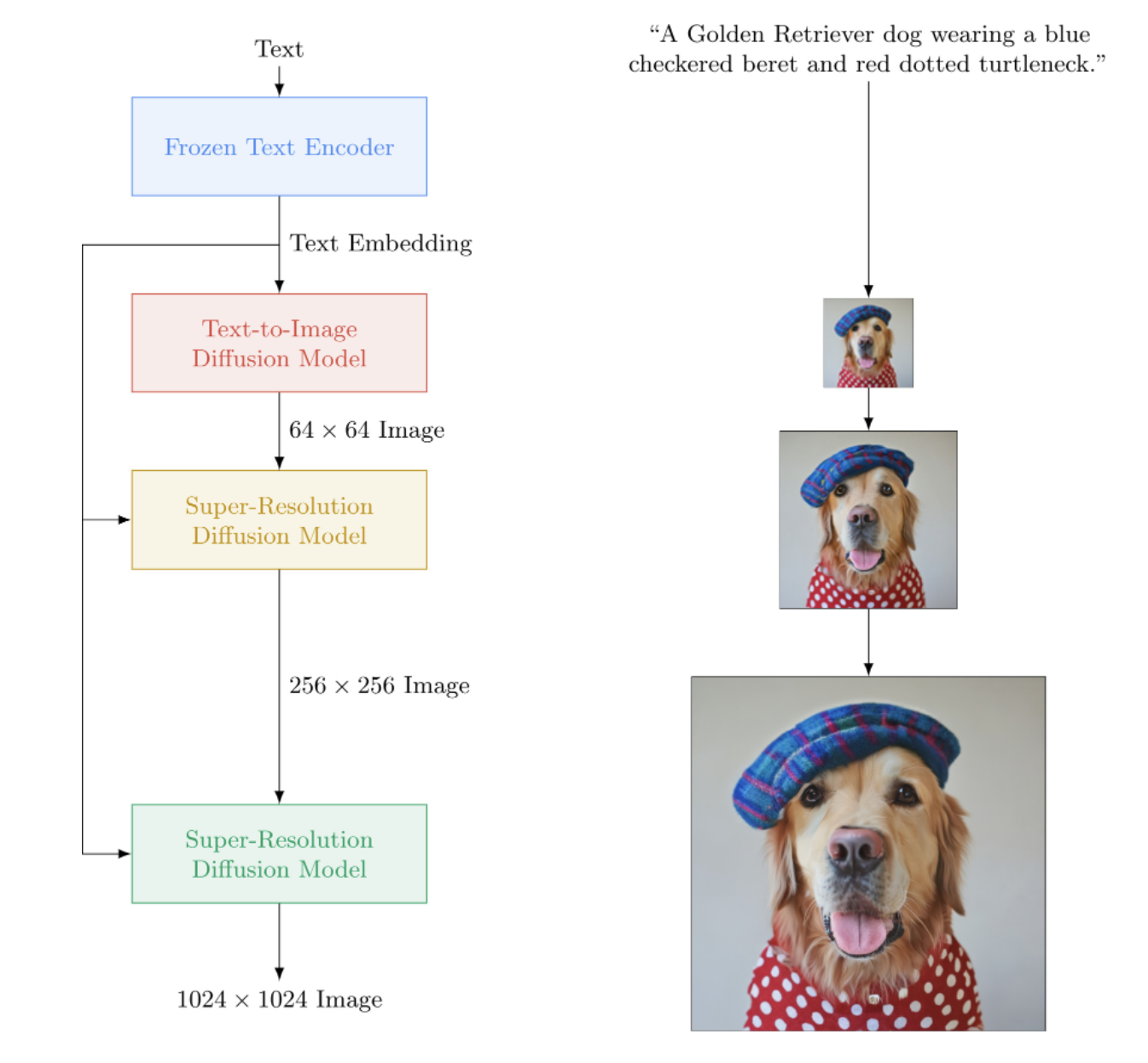
Implementasi Imagen, Jaringan Neural Text-to-Image Google yang mengalahkan DALL-E2, di Pytorch. Ini adalah SOTA baru untuk sintesis teks-ke-gambar.
Secara arsitektur, ini sebenarnya jauh lebih sederhana daripada DALL-E2. Ini terdiri dari DDPM berjenjang yang dikondisikan pada penyematan teks dari model T5 besar yang telah dilatih sebelumnya (jaringan perhatian). Ini juga berisi kliping dinamis untuk panduan bebas pengklasifikasi yang lebih baik, pengondisian tingkat kebisingan, dan desain unet yang hemat memori.
Tampaknya CLIP atau jaringan sebelumnya tidak diperlukan. Dan penelitian terus berlanjut.
Rehat Kopi AI dengan Letitia | Perakitan AI | Yannic Kilcher
Silakan bergabung jika Anda tertarik membantu replikasi bersama komunitas LAION
StabilityAI atas sponsor yang murah hati, serta sponsor saya yang lain di luar sana
? Huggingface untuk perpustakaan transformator mereka yang menakjubkan. Bagian encoder teks cukup banyak ditangani karena mereka
Jonathan Ho yang telah mewujudkan revolusi dalam kecerdasan buatan generatif melalui makalahnya yang penting
Sylvain dan Zachary untuk perpustakaan Accelerate, yang digunakan repositori ini untuk pelatihan terdistribusi
Alex untuk einops, alat yang sangat diperlukan untuk manipulasi tensor
Jorge Gomes atas bantuannya dengan kode pemuatan T5 dan saran tentang versi T5 yang benar
Katherine Crowson, atas kodenya yang indah, yang membantu saya memahami difusi gaussian versi waktu berkelanjutan
Marunine dan Netruk44, untuk meninjau kode, berbagi hasil eksperimen, dan membantu proses debug
Marunine yang telah memberikan solusi potensial untuk masalah perubahan warna pada u-nets yang hemat memori. Terima kasih kepada Jacob karena telah berbagi perbandingan eksperimental antara basis dan unet yang hemat memori
Marunine karena menemukan banyak bug, menyelesaikan masalah pengubahan ukuran dengan benar, dan karena membagikan konfigurasi dan hasil eksperimentalnya
MalumaDev karena mengusulkan penggunaan pixel shuffle upsampler untuk memperbaiki artefak papan centang
Valentin untuk menunjukkan koneksi lewati yang tidak mencukupi di unet, serta metode khusus pengondisian perhatian di base-unet di lampiran
BIGJUN untuk menangkap bug besar dengan pengondisian tingkat kebisingan difusi gaussian waktu berkelanjutan pada waktu inferensi
Bingbing untuk mengidentifikasi bug dengan pengambilan sampel dan urutan normalisasi dan noise dengan gambar pengkondisian resolusi rendah
Kay karena telah menyumbangkan pelatihan perintah satu baris Imagen!
Hadrien Reynaud yang telah menguji teks-ke-video pada kumpulan data medis, membagikan hasilnya, dan mengidentifikasi masalah!
$ pip install imagen-pytorch import torch
from imagen_pytorch import Unet , Imagen
# unet for imagen
unet1 = Unet (
dim = 32 ,
cond_dim = 512 ,
dim_mults = ( 1 , 2 , 4 , 8 ),
num_resnet_blocks = 3 ,
layer_attns = ( False , True , True , True ),
layer_cross_attns = ( False , True , True , True )
)
unet2 = Unet (
dim = 32 ,
cond_dim = 512 ,
dim_mults = ( 1 , 2 , 4 , 8 ),
num_resnet_blocks = ( 2 , 4 , 8 , 8 ),
layer_attns = ( False , False , False , True ),
layer_cross_attns = ( False , False , False , True )
)
# imagen, which contains the unets above (base unet and super resoluting ones)
imagen = Imagen (
unets = ( unet1 , unet2 ),
image_sizes = ( 64 , 256 ),
timesteps = 1000 ,
cond_drop_prob = 0.1
). cuda ()
# mock images (get a lot of this) and text encodings from large T5
text_embeds = torch . randn ( 4 , 256 , 768 ). cuda ()
images = torch . randn ( 4 , 3 , 256 , 256 ). cuda ()
# feed images into imagen, training each unet in the cascade
for i in ( 1 , 2 ):
loss = imagen ( images , text_embeds = text_embeds , unet_number = i )
loss . backward ()
# do the above for many many many many steps
# now you can sample an image based on the text embeddings from the cascading ddpm
images = imagen . sample ( texts = [
'a whale breaching from afar' ,
'young girl blowing out candles on her birthday cake' ,
'fireworks with blue and green sparkles'
], cond_scale = 3. )
images . shape # (3, 3, 256, 256)Untuk pelatihan yang lebih sederhana, Anda dapat langsung menyediakan string teks alih-alih melakukan pengkodean teks terlebih dahulu. (Meskipun untuk tujuan penskalaan, Anda pasti ingin menghitung terlebih dahulu penyematan teks + topeng)
Jumlah keterangan teks harus sesuai dengan ukuran kumpulan gambar jika Anda menggunakan cara ini.
# mock images and text (get a lot of this)
texts = [
'a child screaming at finding a worm within a half-eaten apple' ,
'lizard running across the desert on two feet' ,
'waking up to a psychedelic landscape' ,
'seashells sparkling in the shallow waters'
]
images = torch . randn ( 4 , 3 , 256 , 256 ). cuda ()
# feed images into imagen, training each unet in the cascade
for i in ( 1 , 2 ):
loss = imagen ( images , texts = texts , unet_number = i )
loss . backward () Dengan kelas wrapper ImagenTrainer , rata-rata pergerakan eksponensial untuk semua U-net di DDPM berjenjang akan ditangani secara otomatis saat memanggil update
import torch
from imagen_pytorch import Unet , Imagen , ImagenTrainer
# unet for imagen
unet1 = Unet (
dim = 32 ,
cond_dim = 512 ,
dim_mults = ( 1 , 2 , 4 , 8 ),
num_resnet_blocks = 3 ,
layer_attns = ( False , True , True , True ),
)
unet2 = Unet (
dim = 32 ,
cond_dim = 512 ,
dim_mults = ( 1 , 2 , 4 , 8 ),
num_resnet_blocks = ( 2 , 4 , 8 , 8 ),
layer_attns = ( False , False , False , True ),
layer_cross_attns = ( False , False , False , True )
)
# imagen, which contains the unets above (base unet and super resoluting ones)
imagen = Imagen (
unets = ( unet1 , unet2 ),
text_encoder_name = 't5-large' ,
image_sizes = ( 64 , 256 ),
timesteps = 1000 ,
cond_drop_prob = 0.1
). cuda ()
# wrap imagen with the trainer class
trainer = ImagenTrainer ( imagen )
# mock images (get a lot of this) and text encodings from large T5
text_embeds = torch . randn ( 64 , 256 , 1024 ). cuda ()
images = torch . randn ( 64 , 3 , 256 , 256 ). cuda ()
# feed images into imagen, training each unet in the cascade
loss = trainer (
images ,
text_embeds = text_embeds ,
unet_number = 1 , # training on unet number 1 in this example, but you will have to also save checkpoints and then reload and continue training on unet number 2
max_batch_size = 4 # auto divide the batch of 64 up into batch size of 4 and accumulate gradients, so it all fits in memory
)
trainer . update ( unet_number = 1 )
# do the above for many many many many steps
# now you can sample an image based on the text embeddings from the cascading ddpm
images = trainer . sample ( texts = [
'a puppy looking anxiously at a giant donut on the table' ,
'the milky way galaxy in the style of monet'
], cond_scale = 3. )
images . shape # (2, 3, 256, 256)Anda juga dapat melatih Imagen tanpa teks (pembuatan gambar tanpa syarat) sebagai berikut
import torch
from imagen_pytorch import Unet , Imagen , SRUnet256 , ImagenTrainer
# unets for unconditional imagen
unet1 = Unet (
dim = 32 ,
dim_mults = ( 1 , 2 , 4 ),
num_resnet_blocks = 3 ,
layer_attns = ( False , True , True ),
layer_cross_attns = False ,
use_linear_attn = True
)
unet2 = SRUnet256 (
dim = 32 ,
dim_mults = ( 1 , 2 , 4 ),
num_resnet_blocks = ( 2 , 4 , 8 ),
layer_attns = ( False , False , True ),
layer_cross_attns = False
)
# imagen, which contains the unets above (base unet and super resoluting ones)
imagen = Imagen (
condition_on_text = False , # this must be set to False for unconditional Imagen
unets = ( unet1 , unet2 ),
image_sizes = ( 64 , 128 ),
timesteps = 1000
)
trainer = ImagenTrainer ( imagen ). cuda ()
# now get a ton of images and feed it through the Imagen trainer
training_images = torch . randn ( 4 , 3 , 256 , 256 ). cuda ()
# train each unet separately
# in this example, only training on unet number 1
loss = trainer ( training_images , unet_number = 1 )
trainer . update ( unet_number = 1 )
# do the above for many many many many steps
# now you can sample images unconditionally from the cascading unet(s)
images = trainer . sample ( batch_size = 16 ) # (16, 3, 128, 128)Atau latih hanya unet yang sangat tegas
import torch
from imagen_pytorch import Unet , NullUnet , Imagen
# unet for imagen
unet1 = NullUnet () # add a placeholder "null" unet for the base unet
unet2 = Unet (
dim = 32 ,
cond_dim = 512 ,
dim_mults = ( 1 , 2 , 4 , 8 ),
num_resnet_blocks = ( 2 , 4 , 8 , 8 ),
layer_attns = ( False , False , False , True ),
layer_cross_attns = ( False , False , False , True )
)
# imagen, which contains the unets above (base unet and super resoluting ones)
imagen = Imagen (
unets = ( unet1 , unet2 ),
image_sizes = ( 64 , 256 ),
timesteps = 250 ,
cond_drop_prob = 0.1
). cuda ()
# mock images (get a lot of this) and text encodings from large T5
text_embeds = torch . randn ( 4 , 256 , 768 ). cuda ()
images = torch . randn ( 4 , 3 , 256 , 256 ). cuda ()
# feed images into imagen, training each unet in the cascade
loss = imagen ( images , text_embeds = text_embeds , unet_number = 2 )
loss . backward ()
# do the above for many many many many steps
# now you can sample an image based on the text embeddings as well as low resolution images
lowres_images = torch . randn ( 3 , 3 , 64 , 64 ). cuda () # starting un-resoluted images
images = imagen . sample (
texts = [
'a whale breaching from afar' ,
'young girl blowing out candles on her birthday cake' ,
'fireworks with blue and green sparkles'
],
start_at_unet_number = 2 , # start at unet number 2
start_image_or_video = lowres_images , # pass in low resolution images to be resoluted
cond_scale = 3. )
images . shape # (3, 3, 256, 256) Kapan saja Anda dapat menyimpan dan memuat pelatih dan semua status terkait dengan metode save dan load . Disarankan agar Anda menggunakan metode ini daripada menyimpan secara manual dengan panggilan state_dict , karena ada beberapa manajemen memori perangkat yang dilakukan di bawah tenda dalam pelatih.
mantan.
trainer . save ( './path/to/checkpoint.pt' )
trainer . load ( './path/to/checkpoint.pt' )
trainer . steps # (2,) step number for each of the unets, in this case 2 Anda juga dapat mengandalkan ImagenTrainer untuk melatih instance DataLoader secara otomatis. Anda hanya perlu membuat DataLoader untuk mengembalikan images (untuk kasus tanpa syarat), atau ('images', 'text_embeds') untuk pembuatan dengan panduan teks.
mantan. pelatihan tanpa syarat
from imagen_pytorch import Unet , Imagen , ImagenTrainer
from imagen_pytorch . data import Dataset
# unets for unconditional imagen
unet = Unet (
dim = 32 ,
dim_mults = ( 1 , 2 , 4 , 8 ),
num_resnet_blocks = 1 ,
layer_attns = ( False , False , False , True ),
layer_cross_attns = False
)
# imagen, which contains the unet above
imagen = Imagen (
condition_on_text = False , # this must be set to False for unconditional Imagen
unets = unet ,
image_sizes = 128 ,
timesteps = 1000
)
trainer = ImagenTrainer (
imagen = imagen ,
split_valid_from_train = True # whether to split the validation dataset from the training
). cuda ()
# instantiate your dataloader, which returns the necessary inputs to the DDPM as tuple in the order of images, text embeddings, then text masks. in this case, only images is returned as it is unconditional training
dataset = Dataset ( '/path/to/training/images' , image_size = 128 )
trainer . add_train_dataset ( dataset , batch_size = 16 )
# working training loop
for i in range ( 200000 ):
loss = trainer . train_step ( unet_number = 1 , max_batch_size = 4 )
print ( f'loss: { loss } ' )
if not ( i % 50 ):
valid_loss = trainer . valid_step ( unet_number = 1 , max_batch_size = 4 )
print ( f'valid loss: { valid_loss } ' )
if not ( i % 100 ) and trainer . is_main : # is_main makes sure this can run in distributed
images = trainer . sample ( batch_size = 1 , return_pil_images = True ) # returns List[Image]
images [ 0 ]. save ( f'./sample- { i // 100 } .png' )Terima kasih kepada? Percepat, Anda dapat melakukan pelatihan multi GPU dengan mudah hanya dengan dua langkah.
Pertama, Anda perlu menjalankan accelerate config di direktori yang sama dengan skrip pelatihan Anda (misalnya bernama train.py )
$ accelerate config Selanjutnya, alih-alih memanggil python train.py seperti yang Anda lakukan untuk GPU tunggal, Anda akan menggunakan CLI akselerasi juga
$ accelerate launch train.pyItu saja!
Imagen juga dapat digunakan melalui CLI secara langsung.
mantan.
$ imagen configatau
$ imagen config --path ./configs/config.jsonDalam konfigurasi Anda dapat mengubah pengaturan untuk pelatih, kumpulan data, dan konfigurasi imagen.
Parameter konfigurasi Imagen dapat ditemukan di sini
Parameter konfigurasi Elucidated Imagen dapat ditemukan di sini
Parameter konfigurasi Imagen Trainer dapat ditemukan di sini
Untuk parameter dataset, semua parameter dataloader dapat digunakan.
Perintah ini memungkinkan Anda untuk melatih atau melanjutkan pelatihan model Anda
mantan.
$ imagen trainatau
$ imagen train --unet 2 --epoches 10Anda dapat meneruskan argumen berikut ke perintah pelatihan.
--config tentukan file konfigurasi yang akan digunakan untuk pelatihan [default: ./imagen_config.json]--unet indeks unet yang akan dilatih [default: 1]--epoches berapa banyak epoch yang harus dilatih [default: 50]Berhati-hatilah saat mengambil sampel di pos pemeriksaan Anda, seharusnya sudah melatih semua unet untuk mendapatkan hasil yang dapat digunakan.
mantan.
$ imagen sample --model ./path/to/model/checkpoint.pt " a squirrel raiding the birdfeeder "
# image is saved to ./a_squirrel_raiding_the_birdfeeder.pngAnda dapat meneruskan argumen berikut ke perintah sampel.
--model tentukan file model yang akan digunakan untuk pengambilan sampel--cond_scale pengkondisian skala (panduan bebas pengklasifikasi) di decoder--load_ema memuat versi EMA unets jika tersedia Untuk menggunakan pos pemeriksaan tersimpan dengan fitur ini, Anda harus membuat instance Imagen Anda menggunakan kelas konfigurasi, ImagenConfig dan ElucidatedImagenConfig atau membuat pos pemeriksaan melalui CLI secara langsung
Untuk pelatihan yang tepat, Anda mungkin ingin menyiapkan pelatihan berbasis konfigurasi.
mantan.
import torch
from imagen_pytorch import ImagenConfig , ElucidatedImagenConfig , ImagenTrainer
# in this example, using elucidated imagen
imagen = ElucidatedImagenConfig (
unets = [
dict ( dim = 32 , dim_mults = ( 1 , 2 , 4 , 8 )),
dict ( dim = 32 , dim_mults = ( 1 , 2 , 4 , 8 ))
],
image_sizes = ( 64 , 128 ),
cond_drop_prob = 0.5 ,
num_sample_steps = 32
). create ()
trainer = ImagenTrainer ( imagen )
# do your training ...
# then save it
trainer . save ( './checkpoint.pt' )
# you should see a message informing you that ./checkpoint.pt is commandable from the terminalSeharusnya sesederhana itu
Anda juga dapat meneruskan file pos pemeriksaan ini, dan siapa pun dapat terus menyempurnakan data mereka sendiri
from imagen_pytorch import load_imagen_from_checkpoint , ImagenTrainer
imagen = load_imagen_from_checkpoint ( './checkpoint.pt' )
trainer = ImagenTrainer ( imagen )
# continue training / fine-tuning Inpainting mengikuti formulasi yang ditetapkan oleh makalah Repaint baru-baru ini. Cukup teruskan inpaint_images dan inpaint_masks ke fungsi sample di Imagen atau ElucidatedImagen
inpaint_images = torch . randn ( 4 , 3 , 512 , 512 ). cuda () # (batch, channels, height, width)
inpaint_masks = torch . ones (( 4 , 512 , 512 )). bool (). cuda () # (batch, height, width)
inpainted_images = trainer . sample ( texts = [
'a whale breaching from afar' ,
'young girl blowing out candles on her birthday cake' ,
'fireworks with blue and green sparkles' ,
'dust motes swirling in the morning sunshine on the windowsill'
], inpaint_images = inpaint_images , inpaint_masks = inpaint_masks , cond_scale = 5. )
inpainted_images # (4, 3, 512, 512) Untuk video, kirimkan juga video Anda ke kata kunci inpaint_videos di .sample . Masker inpainting bisa sama di semua bingkai (batch, height, width) atau berbeda (batch, frames, height, width)
inpaint_videos = torch . randn ( 4 , 3 , 8 , 512 , 512 ). cuda () # (batch, channels, frames, height, width)
inpaint_masks = torch . ones (( 4 , 8 , 512 , 512 )). bool (). cuda () # (batch, frames, height, width)
inpainted_videos = trainer . sample ( texts = [
'a whale breaching from afar' ,
'young girl blowing out candles on her birthday cake' ,
'fireworks with blue and green sparkles' ,
'dust motes swirling in the morning sunshine on the windowsill'
], inpaint_videos = inpaint_videos , inpaint_masks = inpaint_masks , cond_scale = 5. )
inpainted_videos # (4, 3, 8, 512, 512) Tero Karras dari StyleGAN yang terkenal telah menulis makalah baru dengan hasil yang telah dikuatkan oleh sejumlah peneliti independen serta pada mesin saya sendiri. Saya telah memutuskan untuk membuat versi Imagen , ElucidatedImagen , sehingga seseorang dapat menggunakan DDPM baru yang telah dijelaskan untuk pembuatan cascading yang dipandu teks.
Cukup impor ElucidatedImagen , lalu buat instans instance seperti yang Anda lakukan sebelumnya. Hyperparameter berbeda dari hyperparameter biasa untuk difusi gaussian waktu diskrit dan kontinu, dan dapat diindividualisasikan untuk setiap unet dalam kaskade.
Mantan.
from imagen_pytorch import ElucidatedImagen
# instantiate your unets ...
imagen = ElucidatedImagen (
unets = ( unet1 , unet2 ),
image_sizes = ( 64 , 128 ),
cond_drop_prob = 0.1 ,
num_sample_steps = ( 64 , 32 ), # number of sample steps - 64 for base unet, 32 for upsampler (just an example, have no clue what the optimal values are)
sigma_min = 0.002 , # min noise level
sigma_max = ( 80 , 160 ), # max noise level, @crowsonkb recommends double the max noise level for upsampler
sigma_data = 0.5 , # standard deviation of data distribution
rho = 7 , # controls the sampling schedule
P_mean = - 1.2 , # mean of log-normal distribution from which noise is drawn for training
P_std = 1.2 , # standard deviation of log-normal distribution from which noise is drawn for training
S_churn = 80 , # parameters for stochastic sampling - depends on dataset, Table 5 in apper
S_tmin = 0.05 ,
S_tmax = 50 ,
S_noise = 1.003 ,
). cuda ()
# rest is the same as above Repositori ini juga akan mulai mengumpulkan penelitian baru seputar sintesis video yang dipandu teks. Sebagai permulaan, ini akan mengadopsi arsitektur 3d unet yang dijelaskan oleh Jonathan Ho dalam Video Diffusion Models
Pembaruan: diverifikasi berfungsi oleh Hadrien Reynaud!
Mantan.
import torch
from imagen_pytorch import Unet3D , ElucidatedImagen , ImagenTrainer
unet1 = Unet3D ( dim = 64 , dim_mults = ( 1 , 2 , 4 , 8 )). cuda ()
unet2 = Unet3D ( dim = 64 , dim_mults = ( 1 , 2 , 4 , 8 )). cuda ()
# elucidated imagen, which contains the unets above (base unet and super resoluting ones)
imagen = ElucidatedImagen (
unets = ( unet1 , unet2 ),
image_sizes = ( 16 , 32 ),
random_crop_sizes = ( None , 16 ),
temporal_downsample_factor = ( 2 , 1 ), # in this example, the first unet would receive the video temporally downsampled by 2x
num_sample_steps = 10 ,
cond_drop_prob = 0.1 ,
sigma_min = 0.002 , # min noise level
sigma_max = ( 80 , 160 ), # max noise level, double the max noise level for upsampler
sigma_data = 0.5 , # standard deviation of data distribution
rho = 7 , # controls the sampling schedule
P_mean = - 1.2 , # mean of log-normal distribution from which noise is drawn for training
P_std = 1.2 , # standard deviation of log-normal distribution from which noise is drawn for training
S_churn = 80 , # parameters for stochastic sampling - depends on dataset, Table 5 in apper
S_tmin = 0.05 ,
S_tmax = 50 ,
S_noise = 1.003 ,
). cuda ()
# mock videos (get a lot of this) and text encodings from large T5
texts = [
'a whale breaching from afar' ,
'young girl blowing out candles on her birthday cake' ,
'fireworks with blue and green sparkles' ,
'dust motes swirling in the morning sunshine on the windowsill'
]
videos = torch . randn ( 4 , 3 , 10 , 32 , 32 ). cuda () # (batch, channels, time / video frames, height, width)
# feed images into imagen, training each unet in the cascade
# for this example, only training unet 1
trainer = ImagenTrainer ( imagen )
# you can also ignore time when training on video initially, shown to improve results in video-ddpm paper. eventually will make the 3d unet trainable with either images or video. research shows it is essential (with current data regimes) to train first on text-to-image. probably won't be true in another decade. all big data becomes small data
trainer ( videos , texts = texts , unet_number = 1 , ignore_time = False )
trainer . update ( unet_number = 1 )
videos = trainer . sample ( texts = texts , video_frames = 20 ) # extrapolating to 20 frames from training on 10 frames
videos . shape # (4, 3, 20, 32, 32) Anda juga dapat melatih pasangan teks - gambar terlebih dahulu. Unet3D akan secara otomatis mengonversinya menjadi video berbingkai tunggal dan belajar tanpa komponen temporal (dengan menyetel secara otomatis ignore_time = True ), baik itu konvolusi 1 hari atau perhatian kausal sepanjang waktu.
Ini adalah pendekatan yang saat ini diambil oleh semua laboratorium kecerdasan buatan (Brain, MetaAI, Bytedance)
Imagen menggunakan algoritma yang disebut Classifier Free Guidance. Saat mengambil sampel, Anda menerapkan skala pada pengondisian (dalam hal ini teks) yang lebih besar dari 1.0 .
Peneliti Netruk44 telah melaporkan 5-10 adalah optimal, namun jika lebih besar dari 10 maka tidak optimal.
trainer . sample ( texts = [
'a cloud in the shape of a roman gladiator'
], cond_scale = 5. ) # <-- cond_scale is the conditioning scale, needs to be greater than 1.0 to be better than averageTidak untuk saat ini, namun kemungkinan besar seseorang akan dilatih dan dijadikan sumber terbuka dalam tahun ini, atau bahkan lebih cepat. Jika Anda ingin berpartisipasi, Anda dapat bergabung dengan komunitas pelatih jaringan saraf tiruan di Laion (link perselisihan ada di Readme di atas) dan mulai berkolaborasi.
Alasan lainnya mengapa Anda harus mulai melatih model Anda sendiri, mulai hari ini! Hal terakhir yang kita butuhkan adalah teknologi ini berada di tangan segelintir orang elit. Mudah-mudahan repositori ini mengurangi pekerjaan hanya untuk menemukan komputasi yang diperlukan, dan menambah kumpulan data pilihan Anda sendiri.
Apa pun! Ini berlisensi MIT. Dengan kata lain, Anda dapat dengan bebas menyalin / menempel untuk penelitian Anda sendiri, di-remix untuk modalitas apa pun yang Anda pikirkan. Latihlah model-model luar biasa untuk mendapatkan keuntungan, untuk sains, atau sekadar untuk memuaskan kesenangan pribadi Anda saat menyaksikan sesuatu yang ilahi terungkap di depan Anda.
Sintesis ekokardiogram [Kode]
Sintesis matriks kontak SOTA Hi-C [Kode]
Pembuatan denah lantai
Slide Histopatologi Resolusi Ultra Tinggi
Gambar Laparoskopi Sintetis
Merancang MetaMaterial
Difusi audio dari Flavio Schneider
Gambar Mini dari Ryan O. | Tulisan MajelisAI
gunakan transformator pelukan untuk penyematan teks kecil T5
tambahkan ambang batas dinamis
tambahkan juga DALLE2 ambang batas dinamis dan repositori difusi video
izinkan seseorang untuk menyetel T5-besar (dan mungkin metode pabrik kecil untuk menggunakan transformator pelukan)
tambahkan tingkat kebisingan rendah dengan kodesemu di lampiran, dan cari tahu sapuan apa yang mereka lakukan pada waktu inferensi
port atas beberapa kode pelatihan dari DALLE2
harus dapat menggunakan jadwal kebisingan yang berbeda per unet (kosinus digunakan untuk basis, tetapi linier untuk SR)
cukup buat satu unet yang dapat dikonfigurasi master
blok resnet lengkap (terinspirasi biggan? tetapi dengan groupnorm) - perhatian diri lengkap
blok penyematan pengkondisian lengkap (dan membuatnya sepenuhnya dapat dikonfigurasi, apakah itu perhatian, film, dll)
pertimbangkan untuk menggunakan perception-resampler dari https://github.com/lucidrains/flamingo-pytorch sebagai pengganti pengumpulan perhatian
tambahkan opsi pengumpulan perhatian, selain perhatian silang dan film
tambahkan jadwal peluruhan kosinus opsional dengan pemanasan, untuk setiap unet, ke pelatih
beralih ke langkah waktu berkelanjutan alih-alih diskrit, karena tampaknya itulah yang mereka gunakan untuk semua tahapan - pertama-tama cari tahu kasus jadwal kebisingan linier dari makalah variasi ddpm https://openreview.net/forum?id=2LdBqxc1Yv
cari tahu log(snr) untuk jadwal kebisingan alpha cosinus.
menekan peringatan transformator karena hanya T5encoder yang digunakan
izinkan pengaturan untuk menggunakan perhatian linier pada lapisan di mana perhatian penuh tidak dapat digunakan
paksa unets dalam kasus waktu berkelanjutan untuk menggunakan kondisi non-fouriered (cukup lewati log(snr) melalui MLP dengan norma lapisan opsional), karena itulah yang saya kerjakan secara lokal
menghilangkan varians yang dipelajari
tambahkan pembobotan kerugian p2 untuk waktu terus menerus
pastikan cascading ddpm dapat dilatih tanpa kondisi teks, dan pastikan difusi gaussian waktu kontinu dan diskrit berfungsi
gunakan konversi mendalam primer pada proyeksi qkv dalam perhatian linier (atau gunakan pergeseran token sebelum proyeksi) - gunakan juga dropout baru yang diusulkan oleh bayesformer, karena tampaknya berfungsi dengan baik dengan perhatian linier
jelajahi lewati eksitasi lapisan di dekoder unet
mempercepat integrasi
membangun alat CLI dan pembuatan gambar satu baris
menghilangkan masalah apa pun yang muncul dari akselerasi
tambahkan kemampuan inpainting menggunakan resampler dari kertas repaint https://arxiv.org/abs/2201.09865
membangun sistem pos pemeriksaan sederhana, didukung oleh sebuah folder
tambahkan lewati koneksi dari keluaran semua blok upsample, yang digunakan dalam kertas kuadrat unet dan beberapa karya unet sebelumnya
tambahkan fsspec, direkomendasikan oleh Romain @ rom1504, untuk persistensi titik pemeriksaan agnostik sistem file cloud/lokal
uji persistensi di gcs dengan https://github.com/fsspec/gcsfs
meluas ke pembuatan video, menggunakan perhatian waktu aksial seperti pada makalah video ddpm Ho
memungkinkan gambar yang dijelaskan untuk digeneralisasikan ke bentuk apa pun
memungkinkan gambar digeneralisasikan ke bentuk apa pun
tambahkan bias posisi dinamis untuk jenis ekstrapolasi panjang terbaik sepanjang waktu video
pindahkan bingkai video ke fungsi sampel, karena kita akan mencoba ekstrapolasi waktu
bias perhatian terhadap kunci/nilai nol harus menjadi skalar dimensi kepala yang dipelajari
tambahkan pengkondisian mandiri dari kertas difusi bit, yang sudah diberi kode di ddpm-pytorch
tambahkan v-parameterisasi (https://arxiv.org/abs/2202.00512) dari kertas video imagen, satu-satunya yang baru
menggabungkan semua pembelajaran dari pembuatan video (https://makeavideo.studio/)
membangun alat CLI untuk pelatihan, melanjutkan pelatihan dari file konfigurasi
memungkinkan interpolasi temporal pada tahapan tertentu
pastikan interpolasi temporal berfungsi dengan inpainting
pastikan seseorang dapat menyesuaikan semua mode interpolasi (beberapa peneliti menemukan hasil yang lebih baik dengan trilinear)
imagen-video : memungkinkan pengondisian pada frame video sebelumnya (dan mungkin di masa mendatang). mengabaikan waktu tidak diperbolehkan dalam skenario itu
pastikan untuk secara otomatis menangani penurunan/peningkatan temporal untuk mengondisikan bingkai video, tetapi izinkan opsi untuk mematikannya
pastikan inpainting berfungsi dengan video
pastikan topeng inpainting untuk video dapat disesuaikan per bingkai
tambahkan perhatian kilat
baca ulang cogvideo dan cari tahu bagaimana pengondisian frame rate dapat digunakan
mendatangkan keahlian perhatian untuk lapisan perhatian diri di unet3d
pertimbangkan untuk membawa perhatian konvolusional 3d NUWA
pertimbangkan kenangan transformator-xl di blok perhatian temporal
pertimbangkan pendekatan yang mempersepsikan untuk memperhatikan waktu lampau
frame dropout selama perhatian untuk mencapai efek pengaturan serta mempersingkat waktu pelatihan
selidiki klaim frank wood https://github.com/lucidrains/flexible-diffusion-modeling-videos-pytorch dan tambahkan teknik pengambilan sampel hierarki, atau beri tahu orang-orang tentang kekurangannya
menawarkan mnist bergerak yang menantang (dengan objek pengalih perhatian) sebagai garis dasar satu baris yang dapat dilatih bagi peneliti untuk bercabang dari teks ke video
pra-pengkodean teks ke embeddings yang dipetakan
dapat membuat iterator pemuat data berdasarkan gaya zaman lama, juga mengonfigurasi pengacakan, dll
dapat juga meneruskan argumen (daripada mengharuskan penerusan semua argumen kata kunci pada model)
membawa blok reversibel dari revnets untuk 3d unet, untuk mengurangi beban memori
tambahkan kemampuan untuk hanya melatih jaringan resolusi super
baca dpm-solver lihat apakah ini berlaku untuk difusi gaussian waktu berkelanjutan
memungkinkan pengkondisian bingkai video dengan waktu absolut yang berubah-ubah (hitung RPE selama perhatian sementara)
mengakomodasi penyempurnaan booth impian
tambahkan inversi tekstual
pembersihan pengkondisian diri untuk diekstraksi pada instantiasi imagen
pastikan dreambooth akhirnya berfungsi dengan imagen-video
tambahkan pengkondisian framerate untuk difusi video
pastikan seseorang dapat secara bersamaan mengkondisikan frame video sebagai prompt, serta beberapa pengondisian gambar di semua frame
menguji dan menambahkan teknik distilasi dari model konsistensi
@inproceedings { Saharia2022PhotorealisticTD ,
title = { Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding } ,
author = { Chitwan Saharia and William Chan and Saurabh Saxena and Lala Li and Jay Whang and Emily L. Denton and Seyed Kamyar Seyed Ghasemipour and Burcu Karagol Ayan and Seyedeh Sara Mahdavi and Raphael Gontijo Lopes and Tim Salimans and Jonathan Ho and David Fleet and Mohammad Norouzi } ,
year = { 2022 }
} @article { Alayrac2022Flamingo ,
title = { Flamingo: a Visual Language Model for Few-Shot Learning } ,
author = { Jean-Baptiste Alayrac et al } ,
year = { 2022 }
} @inproceedings { Sankararaman2022BayesFormerTW ,
title = { BayesFormer: Transformer with Uncertainty Estimation } ,
author = { Karthik Abinav Sankararaman and Sinong Wang and Han Fang } ,
year = { 2022 }
} @article { So2021PrimerSF ,
title = { Primer: Searching for Efficient Transformers for Language Modeling } ,
author = { David R. So and Wojciech Ma'nke and Hanxiao Liu and Zihang Dai and Noam M. Shazeer and Quoc V. Le } ,
journal = { ArXiv } ,
year = { 2021 } ,
volume = { abs/2109.08668 }
} @misc { cao2020global ,
title = { Global Context Networks } ,
author = { Yue Cao and Jiarui Xu and Stephen Lin and Fangyun Wei and Han Hu } ,
year = { 2020 } ,
eprint = { 2012.13375 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @article { Karras2022ElucidatingTD ,
title = { Elucidating the Design Space of Diffusion-Based Generative Models } ,
author = { Tero Karras and Miika Aittala and Timo Aila and Samuli Laine } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2206.00364 }
} @inproceedings { NEURIPS2020_4c5bcfec ,
author = { Ho, Jonathan and Jain, Ajay and Abbeel, Pieter } ,
booktitle = { Advances in Neural Information Processing Systems } ,
editor = { H. Larochelle and M. Ranzato and R. Hadsell and M.F. Balcan and H. Lin } ,
pages = { 6840--6851 } ,
publisher = { Curran Associates, Inc. } ,
title = { Denoising Diffusion Probabilistic Models } ,
url = { https://proceedings.neurips.cc/paper/2020/file/4c5bcfec8584af0d967f1ab10179ca4b-Paper.pdf } ,
volume = { 33 } ,
year = { 2020 }
} @article { Lugmayr2022RePaintIU ,
title = { RePaint: Inpainting using Denoising Diffusion Probabilistic Models } ,
author = { Andreas Lugmayr and Martin Danelljan and Andr{'e}s Romero and Fisher Yu and Radu Timofte and Luc Van Gool } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2201.09865 }
} @misc { ho2022video ,
title = { Video Diffusion Models } ,
author = { Jonathan Ho and Tim Salimans and Alexey Gritsenko and William Chan and Mohammad Norouzi and David J. Fleet } ,
year = { 2022 } ,
eprint = { 2204.03458 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @inproceedings { rogozhnikov2022einops ,
title = { Einops: Clear and Reliable Tensor Manipulations with Einstein-like Notation } ,
author = { Alex Rogozhnikov } ,
booktitle = { International Conference on Learning Representations } ,
year = { 2022 } ,
url = { https://openreview.net/forum?id=oapKSVM2bcj }
} @misc { chen2022analog ,
title = { Analog Bits: Generating Discrete Data using Diffusion Models with Self-Conditioning } ,
author = { Ting Chen and Ruixiang Zhang and Geoffrey Hinton } ,
year = { 2022 } ,
eprint = { 2208.04202 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { Singer2022 ,
author = { Uriel Singer } ,
url = { https://makeavideo.studio/Make-A-Video.pdf }
} @article { Sunkara2022NoMS ,
title = { No More Strided Convolutions or Pooling: A New CNN Building Block for Low-Resolution Images and Small Objects } ,
author = { Raja Sunkara and Tie Luo } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2208.03641 }
} @article { Salimans2022ProgressiveDF ,
title = { Progressive Distillation for Fast Sampling of Diffusion Models } ,
author = { Tim Salimans and Jonathan Ho } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2202.00512 }
} @article { Ho2022ImagenVH ,
title = { Imagen Video: High Definition Video Generation with Diffusion Models } ,
author = { Jonathan Ho and William Chan and Chitwan Saharia and Jay Whang and Ruiqi Gao and Alexey A. Gritsenko and Diederik P. Kingma and Ben Poole and Mohammad Norouzi and David J. Fleet and Tim Salimans } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2210.02303 }
} @misc { gilmer2023intriguing
title = { Intriguing Properties of Transformer Training Instabilities } ,
author = { Justin Gilmer, Andrea Schioppa, and Jeremy Cohen } ,
year = { 2023 } ,
status = { to be published - one attention stabilization technique is circulating within Google Brain, being used by multiple teams }
} @inproceedings { Hang2023EfficientDT ,
title = { Efficient Diffusion Training via Min-SNR Weighting Strategy } ,
author = { Tiankai Hang and Shuyang Gu and Chen Li and Jianmin Bao and Dong Chen and Han Hu and Xin Geng and Baining Guo } ,
year = { 2023 }
} @article { Zhang2021TokenST ,
title = { Token Shift Transformer for Video Classification } ,
author = { Hao Zhang and Y. Hao and Chong-Wah Ngo } ,
journal = { Proceedings of the 29th ACM International Conference on Multimedia } ,
year = { 2021 }
} @inproceedings { anonymous2022normformer ,
title = { NormFormer: Improved Transformer Pretraining with Extra Normalization } ,
author = { Anonymous } ,
booktitle = { Submitted to The Tenth International Conference on Learning Representations } ,
year = { 2022 } ,
url = { https://openreview.net/forum?id=GMYWzWztDx5 } ,
note = { under review }
} @inproceedings { Sadat2024EliminatingOA ,
title = { Eliminating Oversaturation and Artifacts of High Guidance Scales in Diffusion Models } ,
author = { Seyedmorteza Sadat and Otmar Hilliges and Romann M. Weber } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:273098845 }
}

