PaLM rlhf pytorch
0.3.9
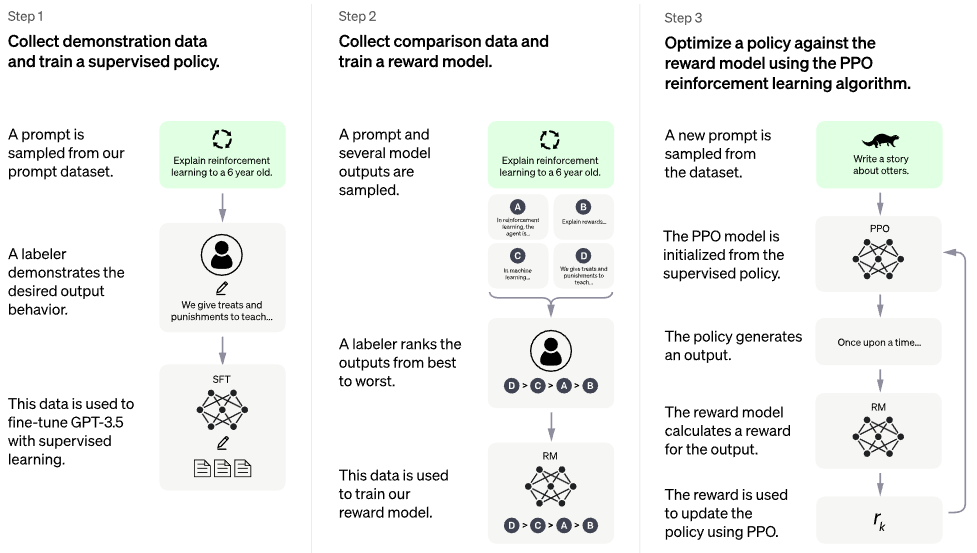
posting blog chatgpt resmi
Implementasi RLHF (Reinforcement Learning with Human Feedback) di atas arsitektur PaLM. Mungkin saya akan menambahkan fungsi pengambilan juga, ala RETRO
Jika Anda tertarik untuk mereplikasi sesuatu seperti ChatGPT secara terbuka, silakan pertimbangkan untuk bergabung dengan Laion
Penerus potensial: Optimasi Preferensi Langsung - semua kode dalam repo ini menjadi ~ kerugian entropi silang biner, <5 loc. Begitu banyak untuk model Reward dan PPO
Tidak ada model yang terlatih. Ini hanyalah kapal dan peta keseluruhannya. Kita masih membutuhkan jutaan dolar komputasi + data untuk mencapai titik yang tepat dalam ruang parameter dimensi tinggi. Meski begitu, Anda memerlukan pelaut profesional (seperti Robin Rombach dari Stable Diffusion yang terkenal) untuk benar-benar memandu kapal melewati masa-masa sulit hingga saat itu.
CarperAI telah mengerjakan kerangka kerja RLHF untuk model bahasa besar selama berbulan-bulan sebelum rilis ChatGPT.
Yannic Kilcher juga sedang mengerjakan implementasi open source
AI Coffeebreak dengan Letitia | Emporium Kode | Emporium Kode Bagian 2
Stability.ai atas sponsor yang murah hati untuk mengerjakan penelitian kecerdasan buatan yang mutakhir
? Hugging Face dan CarperAI karena menulis postingan blog Illustrating Reinforcement Learning from Human Feedback (RLHF), dan CarperAI juga untuk perpustakaan akselerasi mereka
@kisseternity dan @taynoel84 untuk peninjauan kode dan menemukan bug
Enrico untuk mengintegrasikan Flash Attention dari Pytorch 2.0
$ pip install palm-rlhf-pytorch Latih PaLM pertama, seperti transformator autoregresif lainnya
import torch
from palm_rlhf_pytorch import PaLM
palm = PaLM (
num_tokens = 20000 ,
dim = 512 ,
depth = 12 ,
flash_attn = True # https://arxiv.org/abs/2205.14135
). cuda ()
seq = torch . randint ( 0 , 20000 , ( 1 , 2048 )). cuda ()
loss = palm ( seq , return_loss = True )
loss . backward ()
# after much training, you can now generate sequences
generated = palm . generate ( 2048 ) # (1, 2048) Kemudian latih model penghargaan Anda, dengan masukan manusia yang dikurasi. Dalam makalah aslinya, mereka tidak bisa mendapatkan model hadiah untuk disempurnakan dari transformator yang telah dilatih sebelumnya tanpa overfitting, namun saya tetap memberikan opsi untuk menyempurnakan dengan LoRA , karena ini masih merupakan penelitian terbuka.
import torch
from palm_rlhf_pytorch import PaLM , RewardModel
palm = PaLM (
num_tokens = 20000 ,
dim = 512 ,
depth = 12 ,
causal = False
)
reward_model = RewardModel (
palm ,
num_binned_output = 5 # say rating from 1 to 5
). cuda ()
# mock data
seq = torch . randint ( 0 , 20000 , ( 1 , 1024 )). cuda ()
prompt_mask = torch . zeros ( 1 , 1024 ). bool (). cuda () # which part of the sequence is prompt, which part is response
labels = torch . randint ( 0 , 5 , ( 1 ,)). cuda ()
# train
loss = reward_model ( seq , prompt_mask = prompt_mask , labels = labels )
loss . backward ()
# after much training
reward = reward_model ( seq , prompt_mask = prompt_mask ) Kemudian Anda akan meneruskan transformator dan model hadiah Anda ke RLHFTrainer
import torch
from palm_rlhf_pytorch import PaLM , RewardModel , RLHFTrainer
# load your pretrained palm
palm = PaLM (
num_tokens = 20000 ,
dim = 512 ,
depth = 12
). cuda ()
palm . load ( './path/to/pretrained/palm.pt' )
# load your pretrained reward model
reward_model = RewardModel (
palm ,
num_binned_output = 5
). cuda ()
reward_model . load ( './path/to/pretrained/reward_model.pt' )
# ready your list of prompts for reinforcement learning
prompts = torch . randint ( 0 , 256 , ( 50000 , 512 )). cuda () # 50k prompts
# pass it all to the trainer and train
trainer = RLHFTrainer (
palm = palm ,
reward_model = reward_model ,
prompt_token_ids = prompts
)
trainer . train ( num_episodes = 50000 )
# then, if it succeeded...
# generate say 10 samples and use the reward model to return the best one
answer = trainer . generate ( 2048 , prompt = prompts [ 0 ], num_samples = 10 ) # (<= 2048,) trafo basis klon dengan lora terpisah untuk kritik
juga memungkinkan penyempurnaan berbasis non-LoRA
ulangi normalisasi untuk dapat memiliki versi yang disamarkan, tidak yakin apakah ada orang yang akan menggunakan hadiah/nilai per token, tetapi praktik yang baik untuk diterapkan
lengkapi dengan perhatian terbaik
tambahkan akselerasi Hugging Face dan uji instrumentasi tongkat sihir
mencari literatur untuk mengetahui SOTA terbaru untuk PPO, dengan asumsi bidang RL masih mengalami kemajuan.
uji sistem menggunakan jaringan sentimen terlatih sebagai model penghargaan
tulis memori dalam PPO ke memmapped file numpy
dapatkan pengambilan sampel dengan perintah panjang variabel yang berfungsi, meskipun tidak diperlukan karena hambatannya adalah umpan balik manusia
memungkinkan untuk menyempurnakan lapisan N kedua dari belakang hanya pada aktor atau kritikus, dengan asumsi jika sudah dilatih sebelumnya
menggabungkan beberapa poin pembelajaran dari Sparrow, mengingat video Letitia
antarmuka web sederhana dengan Django + htmx untuk mengumpulkan umpan balik manusia
pertimbangkan RLAIF
@article { Stiennon2020LearningTS ,
title = { Learning to summarize from human feedback } ,
author = { Nisan Stiennon and Long Ouyang and Jeff Wu and Daniel M. Ziegler and Ryan J. Lowe and Chelsea Voss and Alec Radford and Dario Amodei and Paul Christiano } ,
journal = { ArXiv } ,
year = { 2020 } ,
volume = { abs/2009.01325 }
} @inproceedings { Chowdhery2022PaLMSL ,
title = { PaLM: Scaling Language Modeling with Pathways } ,
author = {Aakanksha Chowdhery and Sharan Narang and Jacob Devlin and Maarten Bosma and Gaurav Mishra and Adam Roberts and Paul Barham and Hyung Won Chung and Charles Sutton and Sebastian Gehrmann and Parker Schuh and Kensen Shi and Sasha Tsvyashchenko and Joshua Maynez and Abhishek Rao and Parker Barnes and Yi Tay and Noam M. Shazeer and Vinodkumar Prabhakaran and Emily Reif and Nan Du and Benton C. Hutchinson and Reiner Pope and James Bradbury and Jacob Austin and Michael Isard and Guy Gur-Ari and Pengcheng Yin and Toju Duke and Anselm Levskaya and Sanjay Ghemawat and Sunipa Dev and Henryk Michalewski and Xavier Garc{'i}a and Vedant Misra and Kevin Robinson and Liam Fedus and Denny Zhou and Daphne Ippolito and David Luan and Hyeontaek Lim and Barret Zoph and Alexander Spiridonov and Ryan Sepassi and David Dohan and Shivani Agrawal and Mark Omernick and Andrew M. Dai and Thanumalayan Sankaranarayana Pillai and Marie Pellat and Aitor Lewkowycz and Erica Oliveira Moreira and Rewon Child and Oleksandr Polozov and Katherine Lee and Zongwei Zhou and Xuezhi Wang and Brennan Saeta and Mark Diaz and Orhan Firat and Michele Catasta and Jason Wei and Kathleen S. Meier-Hellstern and Douglas Eck and Jeff Dean and Slav Petrov and Noah Fiedel},
year = { 2022 }
} @article { Hu2021LoRALA ,
title = { LoRA: Low-Rank Adaptation of Large Language Models } ,
author = { Edward J. Hu and Yelong Shen and Phillip Wallis and Zeyuan Allen-Zhu and Yuanzhi Li and Shean Wang and Weizhu Chen } ,
journal = { ArXiv } ,
year = { 2021 } ,
volume = { abs/2106.09685 }
} @inproceedings { Sun2022ALT ,
title = { A Length-Extrapolatable Transformer } ,
author = { Yutao Sun and Li Dong and Barun Patra and Shuming Ma and Shaohan Huang and Alon Benhaim and Vishrav Chaudhary and Xia Song and Furu Wei } ,
year = { 2022 }
} @misc { gilmer2023intriguing
title = { Intriguing Properties of Transformer Training Instabilities } ,
author = { Justin Gilmer, Andrea Schioppa, and Jeremy Cohen } ,
year = { 2023 } ,
status = { to be published - one attention stabilization technique is circulating within Google Brain, being used by multiple teams }
} @inproceedings { dao2022flashattention ,
title = { Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness } ,
author = { Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher } ,
booktitle = { Advances in Neural Information Processing Systems } ,
year = { 2022 }
} @misc { Rubin2024 ,
author = { Ohad Rubin } ,
url = { https://medium.com/ @ ohadrubin/exploring-weight-decay-in-layer-normalization-challenges-and-a-reparameterization-solution-ad4d12c24950 }
} @inproceedings { Yuan2024FreePR ,
title = { Free Process Rewards without Process Labels } ,
author = { Lifan Yuan and Wendi Li and Huayu Chen and Ganqu Cui and Ning Ding and Kaiyan Zhang and Bowen Zhou and Zhiyuan Liu and Hao Peng } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:274445748 }
}

