make a video pytorch
0.4.0
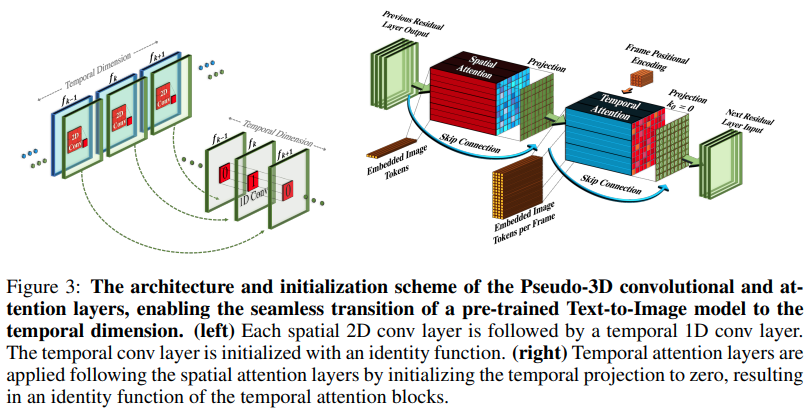
Implementasi Make-A-Video, generator teks ke video SOTA baru dari Meta AI, di Pytorch. Mereka menggabungkan konvolusi pseudo-3d (konvolusi aksial) dan perhatian temporal dan menunjukkan fusi temporal yang jauh lebih baik.
Konvolusi pseudo-3d bukanlah konsep baru. Ini telah dieksplorasi sebelumnya dalam konteks lain, misalnya untuk prediksi kontak protein sebagai "jaringan sisa hibrid dimensional".
Inti dari makalah ini adalah, mengambil model teks-ke-gambar SOTA (di sini mereka menggunakan DALL-E2, tetapi poin pembelajaran yang sama akan dengan mudah diterapkan pada Imagen), membuat beberapa modifikasi kecil untuk perhatian sepanjang waktu dan cara lain untuk menghemat biaya komputasi, lakukan interpolasi bingkai dengan benar, dapatkan model video yang bagus.
Penjelasan AI Coffee Break
Stability.ai atas sponsor yang murah hati untuk mengerjakan penelitian kecerdasan buatan yang mutakhir
Jonathan Ho yang telah mewujudkan revolusi dalam kecerdasan buatan generatif melalui makalahnya yang penting
Alex untuk einops, sebuah abstraksi yang sangat jenius. Tidak ada kata lain untuk itu.
$ pip install make-a-video-pytorchMelewati fitur video
import torch
from make_a_video_pytorch import PseudoConv3d , SpatioTemporalAttention
conv = PseudoConv3d (
dim = 256 ,
kernel_size = 3
)
attn = SpatioTemporalAttention (
dim = 256 ,
dim_head = 64 ,
heads = 8
)
video = torch . randn ( 1 , 256 , 8 , 16 , 16 ) # (batch, features, frames, height, width)
conv_out = conv ( video ) # (1, 256, 8, 16, 16)
attn_out = attn ( video ) # (1, 256, 8, 16, 16)Melewati gambar (jika seseorang melakukan pra-latihan pada gambar terlebih dahulu), konvolusi temporal dan perhatian akan dilewati secara otomatis. Dengan kata lain, Anda dapat menggunakan ini secara langsung di Unet 2d Anda dan kemudian memindahkannya ke Unet 3d setelah fase pelatihan selesai. Modul temporal diinisialisasi ke identitas keluaran seperti yang dilakukan makalah.
import torch
from make_a_video_pytorch import PseudoConv3d , SpatioTemporalAttention
conv = PseudoConv3d (
dim = 256 ,
kernel_size = 3
)
attn = SpatioTemporalAttention (
dim = 256 ,
dim_head = 64 ,
heads = 8
)
images = torch . randn ( 1 , 256 , 16 , 16 ) # (batch, features, height, width)
conv_out = conv ( images ) # (1, 256, 16, 16)
attn_out = attn ( images ) # (1, 256, 16, 16)Anda juga dapat mengontrol kedua modul sehingga ketika fitur 3 dimensi dimasukkan, modul hanya melakukan pelatihan secara spasial
import torch
from make_a_video_pytorch import PseudoConv3d , SpatioTemporalAttention
conv = PseudoConv3d (
dim = 256 ,
kernel_size = 3
)
attn = SpatioTemporalAttention (
dim = 256 ,
dim_head = 64 ,
heads = 8
)
video = torch . randn ( 1 , 256 , 8 , 16 , 16 ) # (batch, features, frames, height, width)
# below it will not train across time
conv_out = conv ( video , enable_time = False ) # (1, 256, 8, 16, 16)
attn_out = attn ( video , enable_time = False ) # (1, 256, 8, 16, 16) SpaceTimeUnet penuh yang tidak mengikuti pelatihan gambar atau video, dan meskipun video diteruskan, waktu dapat diabaikan
import torch
from make_a_video_pytorch import SpaceTimeUnet
unet = SpaceTimeUnet (
dim = 64 ,
channels = 3 ,
dim_mult = ( 1 , 2 , 4 , 8 ),
resnet_block_depths = ( 1 , 1 , 1 , 2 ),
temporal_compression = ( False , False , False , True ),
self_attns = ( False , False , False , True ),
condition_on_timestep = False ,
attn_pos_bias = False ,
flash_attn = True
). cuda ()
# train on images
images = torch . randn ( 1 , 3 , 128 , 128 ). cuda ()
images_out = unet ( images )
assert images . shape == images_out . shape
# then train on videos
video = torch . randn ( 1 , 3 , 16 , 128 , 128 ). cuda ()
video_out = unet ( video )
assert video_out . shape == video . shape
# or even treat your videos as images
video_as_images_out = unet ( video , enable_time = False )berikan perhatian pada penelitian penyematan posisi terbaik yang ditawarkan
menambah perhatian
tambahkan perhatian kilat
pastikan dalle2-pytorch dapat menerima SpaceTimeUnet untuk pelatihan
@misc { Singer2022 ,
author = { Uriel Singer } ,
url = { https://makeavideo.studio/Make-A-Video.pdf }
} @inproceedings { rogozhnikov2022einops ,
title = { Einops: Clear and Reliable Tensor Manipulations with Einstein-like Notation } ,
author = { Alex Rogozhnikov } ,
booktitle = { International Conference on Learning Representations } ,
year = { 2022 } ,
url = { https://openreview.net/forum?id=oapKSVM2bcj }
} @article { Dong2021AttentionIN ,
title = { Attention is Not All You Need: Pure Attention Loses Rank Doubly Exponentially with Depth } ,
author = { Yihe Dong and Jean-Baptiste Cordonnier and Andreas Loukas } ,
journal = { ArXiv } ,
year = { 2021 } ,
volume = { abs/2103.03404 }
} @article { Zhang2021TokenST ,
title = { Token Shift Transformer for Video Classification } ,
author = { Hao Zhang and Y. Hao and Chong-Wah Ngo } ,
journal = { Proceedings of the 29th ACM International Conference on Multimedia } ,
year = { 2021 }
} @inproceedings { shleifer2022normformer ,
title = { NormFormer: Improved Transformer Pretraining with Extra Normalization } ,
author = { Sam Shleifer and Myle Ott } ,
booktitle = { Submitted to The Tenth International Conference on Learning Representations } ,
year = { 2022 } ,
url = { https://openreview.net/forum?id=GMYWzWztDx5 } ,
} @inproceedings { dao2022flashattention ,
title = { Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness } ,
author = { Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher } ,
booktitle = { Advances in Neural Information Processing Systems } ,
year = { 2022 }
}

