minimind
V1

Cina |. Inggris
Proyek sumber terbuka ini bertujuan untuk memulai dari awal, hanya dalam 3 jam! Anda dapat melatih MiniMind, model bahasa mini dengan ukuran hanya 26,88M.
MiniMind sangat ringan, dan versi terkecilnya seukuran GPT3
MiniMind merilis struktur minimalis model besar, pembersihan dan pemrosesan awal kumpulan data, pelatihan awal yang diawasi (Pretrain), penyetelan instruksi yang diawasi (SFT), penyempurnaan adaptif peringkat rendah (LoRA), dan penyelarasan preferensi langsung pembelajaran penguatan bebas hadiah ( DPO) Kode tahap penuh juga mencakup perluasan model sparse dari pakar hybrid bersama (MoE); perluasan VLM multi-modal visual: MiniMind-V.
Ini bukan hanya implementasi model sumber terbuka, tetapi juga tutorial untuk memulai model bahasa besar (LLM).
Kami berharap proyek ini dapat memberikan contoh pengantar kepada para peneliti untuk membantu semua orang memulai dengan cepat dan menghasilkan lebih banyak eksplorasi dan inovasi di bidang LLM.
Untuk mencegah kesalahpahaman, "hingga 3 jam" berarti Anda memerlukan mesin dengan konfigurasi perangkat keras saya sendiri. Detail spesifikasi spesifiknya akan diberikan di bawah.

Tes online ModelScope |
Di bidang model bahasa besar (LLM), seperti GPT, LLaMA, GLM, dll., meskipun efeknya luar biasa, parameter model yang sangat besar sebesar 10 Miliar dan memori perangkat pribadi masih jauh dari cukup untuk pelatihan, dan bahkan inferensi itu sulit. Hampir semua orang tidak puas hanya dengan menyempurnakan model besar menggunakan program seperti Lora untuk mempelajari beberapa instruksi baru. Ini hampir sama dengan mengajari Newton bermain dengan ponsel pintar abad ke-21 fisika itu sendiri. Selain itu, akun pemasaran yang menjual kursus berlangganan berbayar penuh dengan celah dan tutorial yang menjelaskan AI dengan hanya setengah pengetahuan, yang membuatnya semakin sulit untuk memahami konten LLM berkualitas tinggi dan sangat menghambat pembelajar.
Oleh karena itu, tujuan dari proyek ini adalah untuk menurunkan ambang batas untuk memulai LLM dan melatih model bahasa yang sangat ringan langsung dari awal.
Tip
(Mulai 17-9-2024) Seri MiniMind telah menyelesaikan pra-pelatihan 3 model model. Persyaratan minimum hanya 26M (0,02B) untuk memiliki kemampuan percakapan yang lancar!
| Model (ukuran) | panjang tokenizer | hunian alasan | melepaskan | Peringkat subyektif (/100) |
|---|---|---|---|---|
| minimind-v1-kecil (26M) | 6400 | 0,5 GB | 28.08.2024 | 50' |
| minimind-v1-moe (4×26M) | 6400 | 1,0 GB | 2024.09.17 | 55' |
| minimind-v1 (108M) | 6400 | 1,0 GB | 2024.09.01 | 60' |
Analisis dilakukan pada GPU 2×RTX 3090 dengan Torch 2.1.2, CUDA 12.2, dan Flash Attention 2.
Proyek meliputi:
transformers , accelerate , trl , peft , dll.Saya harap proyek sumber terbuka ini dapat membantu pemula LLM memulai dengan cepat!
Memperluas kemampuan multimodal MiniMind - visi
Pindah ke proyek kembar minimind-v untuk melihat detailnya!
09-27 Memperbarui metode prapemrosesan kumpulan data pralatihan. Untuk memastikan integritas teks, prapemrosesan ditinggalkan dan diubah menjadi pelatihan .bin (sedikit mengorbankan kecepatan pelatihan).
File saat ini setelah pemrosesan pra-pelatihan diberi nama: pretrain_data.csv.
Menghapus beberapa kode yang berlebihan.
Perbarui model minimind-v1-moe
Untuk mencegah ambiguitas, mistral_tokenizer tidak lagi digunakan sebagai segmentasi kata, dan semua minimind_tokenizer khusus digunakan sebagai segmentasi kata.
Model minimind-v1 (108M) yang diperbarui, menggunakan minimind_tokenizer, putaran pra-pelatihan 3 + SFT putaran 10, performa yang lebih terlatih dan lebih kuat.
Proyek ini telah diterapkan ke ruang pembuatan ModelScope dan dapat dilihat di situs web ini:
Pengalaman daring ModelScope?
Ini hanyalah konfigurasi lingkungan perangkat lunak dan perangkat keras pribadi saya, silakan ubah sesuai kebijaksanaan Anda:
CPU: Intel(R) Core(TM) i9-10980XE CPU @ 3.00GHz
内存:128 GB
显卡:NVIDIA GeForce RTX 3090(24GB) * 2
环境:python 3.9 + Torch 2.1.2 + DDP单机多卡训练MiniMind (Memeluk Wajah)
MiniMind (ModelScope)
# step 1
git clone https://huggingface.co/jingyaogong/minimind-v1 # step 2
python 2-eval.pyAtau mulai streamlit dan mulai antarmuka obrolan web
"Catatan" memerlukan python>=3.10, instal
pip install streamlit==1.27.2
# or step 3, use streamlit
streamlit run fast_inference.py0. Kloning kode proyek
git clone https://github.com/jingyaogong/minimind.git
cd minimind1. Instalasi lingkungan
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple # 测试torch是否可用cuda
import torch
print(torch.cuda.is_available())
Jika tidak tersedia, silakan buka torch_stable untuk mendownload file whl dan menginstalnya sendiri. Tautan referensi
2. Jika Anda perlu melatih diri sendiri
2.1 Unduh alamat pengunduhan kumpulan data dan letakkan di direktori ./dataset .
2.2 python data_process.py memproses kumpulan data. Misalnya, data pra-pelatihan dikodekan terlebih dahulu dengan token, dan kumpulan data sft diekstraksi dari file qa ke csv.
2.3 Sesuaikan konfigurasi parameter model di ./model/LMConfig.py
Di sini Anda hanya perlu menyesuaikan parameter dim, n_layers dan use_moe, yaitu
(512+8)atau(768+16), sesuai denganminimind-v1-smalldanminimind-v1
2.4 python 1-pretrain.py melakukan pra-pelatihan dan mendapatkan pretrain_*.pth sebagai bobot keluaran pra-pelatihan
2.5 python 3-full_sft.py mengeksekusi instruksi fine-tuning dan mendapatkan full_sft_*.pth sebagai bobot output dari instruksi fine-tuning
2.6 python 4-lora_sft.py melakukan penyesuaian lora (tidak wajib)
2.7 python 5-dpo_train.py melakukan penyelarasan pembelajaran penguatan preferensi manusia DPO (opsional)
3. Uji efek penalaran model
*.pth yang perlu digunakan dan pelatihan selesai terletak di direktori ./out/ .*.pth terlatih saya. minimind/out
├── multi_chat
│ ├── full_sft_512.pth
│ ├── full_sft_512_moe.pth
│ └── full_sft_768.pth
├── single_chat
│ ├── full_sft_512.pth
│ ├── full_sft_512_moe.pth
│ └── full_sft_768.pth
├── pretrain_768.pth
├── pretrain_512_moe.pth
├── pretrain_512.pth
python 0-eval_pretrain.py menguji efek solitaire dari model yang telah dilatih sebelumnyapython 2-eval.py menguji efek dialog model
Pra-pelatihan "Tip" dan penyempurnaan parameter penuh pra-latihan dan full_sft keduanya mendukung akselerasi multi-kartu
Dengan asumsi perangkat Anda hanya memiliki satu kartu grafis, cukup gunakan python asli untuk memulai pelatihan:
python 1-pretrain.py
# and
python 3-full_sft.pyAsumsikan perangkat Anda memiliki N (N>1) kartu grafis:
Pelatihan startup kartu N (DDP) yang berdiri sendiri
torchrun --nproc_per_node N 1-pretrain.py
# and
torchrun --nproc_per_node N 3-full_sft.pyPelatihan startup kartu N mandiri (DeepSpeed)
deepspeed --master_port 29500 --num_gpus=N 1-pretrain.py
# and
deepspeed --master_port 29500 --num_gpus=N 3-full_sft.pyAktifkan Wandb untuk merekam proses pelatihan (opsional)
torchrun --nproc_per_node N 1-pretrain.py --use_wandb
# and
python 1-pretrain.py --use_wandb Dengan menambahkan parameter --use_wandb , proses pelatihan dapat direkam. Setelah pelatihan selesai, proses pelatihan dapat dilihat di website Wandb. Dengan memodifikasi parameter wandb_project dan wandb_run_name , Anda dapat menentukan nama proyek dan nama proses.
? Tokenizer: Tokenizer di nlp mirip dengan kamus, memetakan kata-kata dari bahasa alami ke angka seperti 0, 1, dan 36 melalui "kamus". "kamus". Ada dua cara untuk membuat tokenizer LLM: yang pertama adalah membuat daftar kata sendiri untuk melatih tokenizer, kodenya dapat ditemukan train_tokenizer.py ; yang lainnya adalah memilih tokenizer yang dilatih oleh model sumber terbuka. Tentu saja Anda bisa langsung memilih Kamus Xinhua atau Kamus Oxford untuk "kamus". Kelebihannya adalah tingkat kompresi konversi tokennya sangat baik, namun kekurangannya adalah daftar kosakatanya terlalu panjang, dengan ratusan ribu frasa kosakata. Anda juga dapat menggunakan segmenter kata terlatih Anda sendiri. Keuntungannya adalah Daftar kata dapat dikontrol sesuka hati. Kerugiannya adalah tingkat kompresinya tidak cukup ideal, dan tidak mudah untuk mencakup semua kata yang jarang. Tentu saja, pemilihan "kamus" itu penting. Keluaran LLM pada dasarnya adalah masalah multiklasifikasi N kata dari SoftMax ke kamus, dan kemudian diterjemahkan ke dalam bahasa alami melalui "kamus". Karena LLM sangat kecil, untuk menghindari model menjadi top-heavy (rasio parameter lapisan penyematan kata terhadap keseluruhan LLM terlalu tinggi), panjang kosakata perlu dipilih agar relatif kecil. Model sumber terbuka yang kuat seperti 01 Wanwu, Qianwen, chatglm, mistral, Llama3, dll. memiliki panjang kosakata tokenizer berikut:
| Model tokenisasi | Ukuran kosakata | sumber |
|---|---|---|
| yi tokenizer | 64.000 | 01 Segalanya (Tiongkok) |
| tokenizer qwen2 | 151.643 | Alibaba Cloud (Tiongkok) |
| tokenizer glm | 151.329 | AI Kebijaksanaan (Tiongkok) |
| tokenizer mistral | 32.000 | Mistral AI (Prancis) |
| tokenizer llama3 | 128.000 | Meta (Amerika Serikat) |
| minimalkan tokenizer | 6.400 | Sesuaikan |
Pembaruan 17-09-2024: Untuk mencegah ambiguitas dan mengontrol volume di versi sebelumnya, semua model minimind menggunakan segmentasi kata minimind_tokenizer dan semua versi mistral_tokenizer ditinggalkan.
Meskipun panjang minimind_tokenizer sangat kecil, efisiensi pengkodean dan penguraian kode lebih lemah dibandingkan tokenizer ramah China seperti qwen2 dan glm. Namun, model minimind memilih minimind_tokenizer terlatihnya sendiri sebagai segmenter kata untuk menjaga parameter keseluruhan tetap ringan dan menghindari ketidakseimbangan dalam proporsi lapisan pengkodean dan lapisan penghitungan, yang sangat berat, karena ukuran kosakata minimind hanya 6400. Selain itu, minimind selalu berhasil memecahkan kode kata-kata langka dalam pengujian sebenarnya, dan hasilnya bagus. Karena daftar kata khusus dikompresi menjadi 6400 kata, ukuran parameter total LLM hanya 26 juta.
?[Data pra-pelatihan]: Kumpulan data teks universal Seq-Monkey/disk jaringan Baidu Seq-Monkey dikompilasi dan dibersihkan dari berbagai data sumber publik (seperti halaman web, ensiklopedia, blog, kode sumber terbuka, buku, dll.) . Data ini disusun dalam format JSONL terpadu dan telah melalui penyaringan dan deduplikasi yang ketat untuk memastikan kelengkapan, skala, kredibilitas, dan kualitas data yang tinggi. Jumlah totalnya sekitar 10 miliar token, yang cocok untuk pra-pelatihan model bahasa besar Tiongkok.
Opsi 2: Bagian kumpulan data SkyPile-150B yang dapat diakses publik berisi sekitar 233 juta halaman web unik, masing-masing berisi rata-rata lebih dari 1.000 karakter bahasa Mandarin. Kumpulan data tersebut mencakup sekitar 150 miliar token dan 620 GB data teks biasa. Jika Anda sedang terburu-buru , Anda dapat mencoba memilih hanya sebagian dari unduhan jsonl SkyPile-150B (dan membuat file *.csv untuk tokenizer teks di ./data_process.py) agar dapat dijalankan dengan cepat melalui proses pra-pelatihan .
Unduh ke direktori ./dataset/
| Kumpulan data pelatihan MiniMind | Alamat unduhan |
|---|---|
| [set pelatihan tokenizer] | HuggingFace / Baidu Netdisk |
| 【Data pra-latihan】 | Resmi Seq-Monkey/disk jaringan Baidu/HuggingFace |
| 【Data SFT】 | Kumpulan data SFT model besar Jiangshu |
| 【Data DPO】 | Memeluk wajah |
MiniMind-Dense (sama seperti Llama3.1) menggunakan struktur Transformer Khusus Decoder. Perbedaan dari GPT-3 adalah:
Model MiniMind-MoE, strukturnya didasarkan pada Llama3 dan modul ahli hybrid MixFFN di Deepseek-V2.
Struktur keseluruhan MiniMind sama, kecuali beberapa penyesuaian kecil pada kode penghitungan RoPE, fungsi inferensi, dan lapisan FFN. Strukturnya adalah sebagai berikut (versi yang digambar ulang):
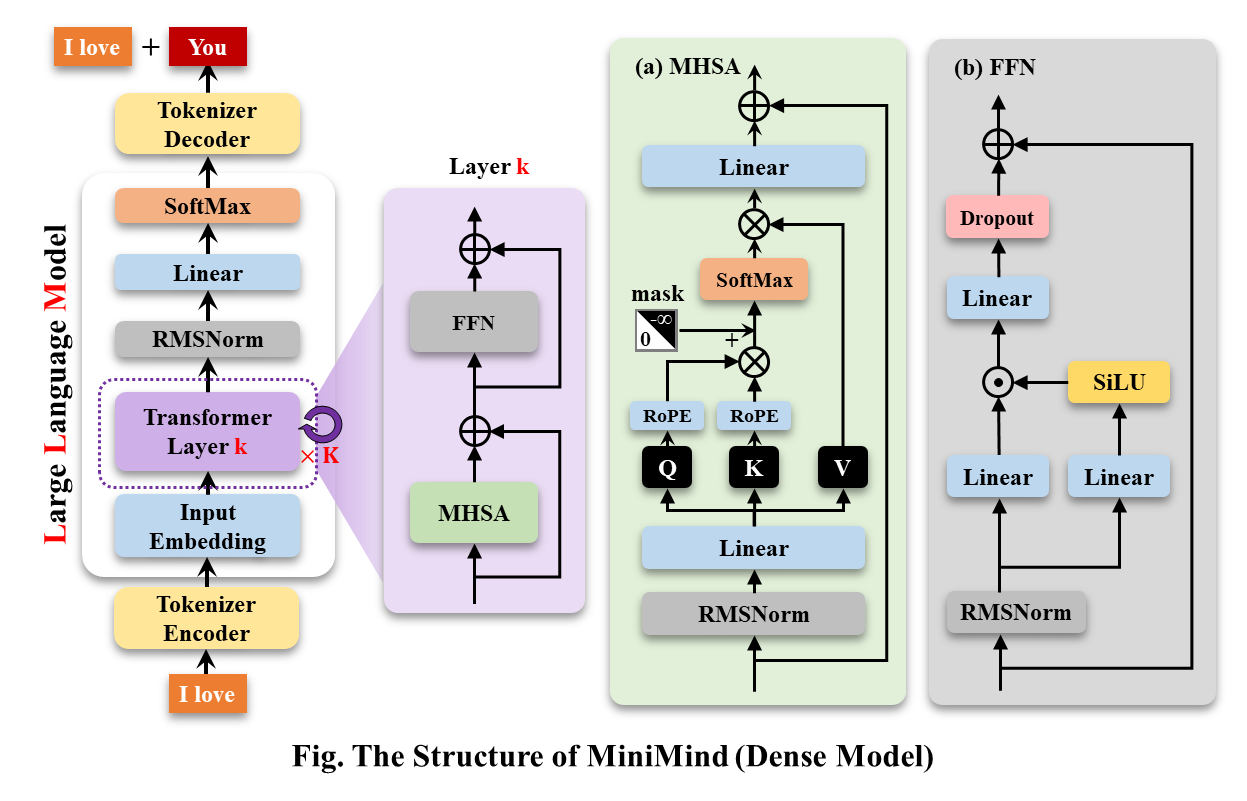
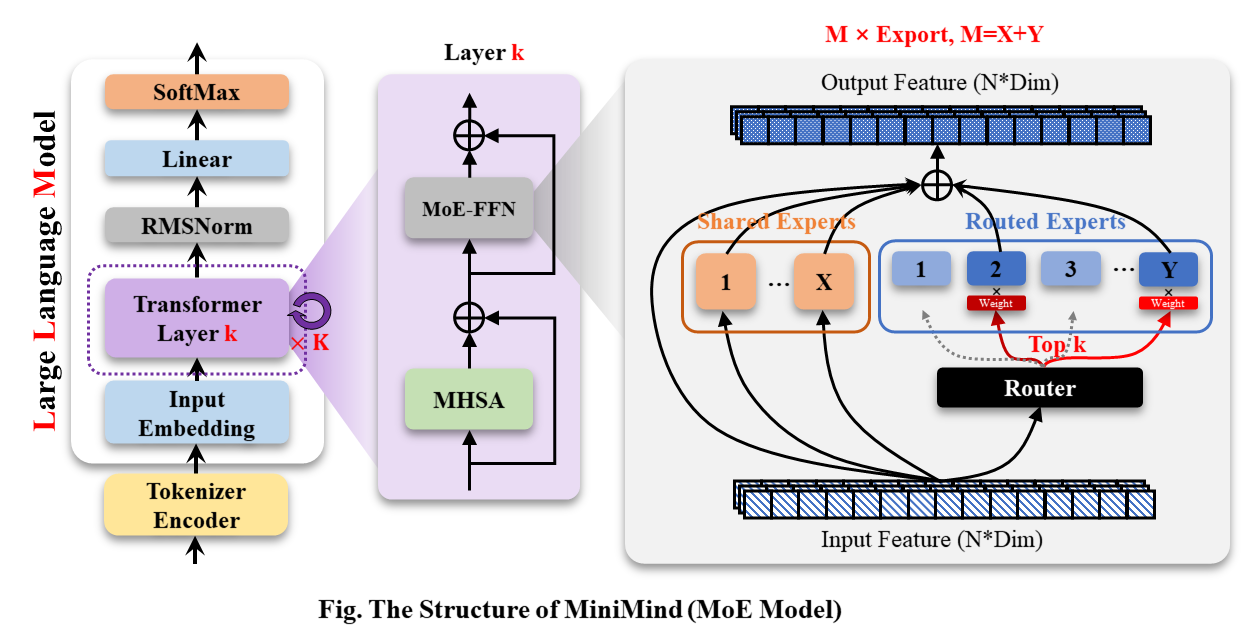
Untuk mengubah konfigurasi model, lihat ./model/LMConfig.py. Versi model yang saat ini dilatih oleh minimind ditunjukkan pada tabel di bawah:
| Nama Model | param | len_vocab | n_lapisan | d_model | kv_heads | q_heads | berbagi+rute | TopK |
|---|---|---|---|---|---|---|---|---|
| minimind-v1-kecil | 26M | 6400 | 8 | 512 | 8 | 16 | - | - |
| minimind-v1-moe | 4×26M | 6400 | 8 | 512 | 8 | 16 | 2+4 | 2 |
| minimind-v1 | 108M | 6400 | 16 | 768 | 8 | 16 | - | - |
| Nama Model | param | len_vocab | ukuran_batch | waktu_pralatihan | sft_single_time | sft_multi_time |
|---|---|---|---|---|---|---|
| minimind-v1-kecil | 26M | 6400 | 64 | ≈2 jam (1 periode) | ≈2 jam (1 periode) | ≈0,5 jam (1 periode) |
| minimind-v1-moe | 4×26M | 6400 | 40 | ≈6 jam (1 periode) | ≈5 jam (1 periode) | ≈1 jam (1 periode) |
| minimind-v1 | 108M | 6400 | 16 | ≈6 jam (1 periode) | ≈4 jam (1 periode) | ≈1 jam (1 periode) |
Pra-pelatihan (Teks-ke-Teks) :
Kecepatan pembelajaran pra-pelatihan diatur ke kecepatan pembelajaran dinamis dari 1e-4 hingga 1e-5, dan jumlah periode pra-pelatihan diatur ke 5.
torchrun --nproc_per_node 2 1-pretrain.pyDialog tunggal Penyempurnaan :
Dengan menyesuaikan perbedaan linier RoPE selama inferensi, akan lebih mudah untuk mengekstrapolasi panjangnya menjadi 1024 atau 2048 ke atas. Kecepatan pembelajaran diatur ke kecepatan pembelajaran dinamis dari 1e-5 hingga 1e-6, dan jumlah periode penyesuaian adalah 6.
# 3-full_sft.py中设置数据集为sft_data_single.csv
torchrun --nproc_per_node 2 3-full_sft.pyPenyempurnaan multi-dialog :
Kecepatan pembelajaran diatur ke kecepatan pembelajaran dinamis dari 1e-5 hingga 1e-6, dan jumlah periode penyesuaian adalah 5.
# 3-full_sft.py中设置数据集为sft_data.csv
torchrun --nproc_per_node 2 3-full_sft.pyPembelajaran Penguatan Umpan Balik Manusia (RLHF) - Optimasi Preferensi Langsung (DPO) :
Kumpulan data triplet tipe bergerak (q, pilih, tolak), kecepatan pembelajaran le-5, fp16 setengah presisi, total 1 epoch, dan membutuhkan waktu 1 jam.
python 5-dpo_train.py ? Mengenai konfigurasi parameter LLM, ada makalah yang sangat menarik MobileLLM yang melakukan penelitian dan eksperimen mendetail. Hukum penskalaan memiliki aturan uniknya sendiri dalam model kecil. Parameter yang menyebabkan parameter Transformer diskalakan bergantung hampir secara eksklusif pada d_model dan n_layers .
d_model ↑+ n_layers ↓->Humpty Dumptyd_model ↓+ n_layers ↑->langsing dan tinggi Makalah yang mengusulkan Scaling Law pada tahun 2020 percaya bahwa jumlah data pelatihan, jumlah parameter, dan jumlah iterasi pelatihan adalah faktor kunci yang menentukan kinerja, dan dampak arsitektur model hampir dapat diabaikan. Namun, tampaknya undang-undang ini tidak sepenuhnya berlaku untuk model kecil. MobileLLM mengusulkan bahwa kedalaman arsitektur lebih penting daripada lebar. Model "dalam dan sempit" "ramping" dapat mempelajari lebih banyak konsep abstrak daripada model "lebar dan dangkal". Misalnya, ketika parameter model ditetapkan pada 125M atau 350M, model "sempit" dengan 30 hingga 42 lapisan memiliki kinerja yang jauh lebih baik daripada model "pendek dan gemuk" dengan sekitar 12 lapisan, dalam 8 pengujian benchmark seperti penalaran akal sehat , tanya jawab, dan pemahaman bacaan. Ada tren serupa. Ini sebenarnya merupakan penemuan yang sangat menarik, karena di masa lalu, ketika merancang arsitektur untuk model kecil berukuran sekitar 100M, hampir tidak ada yang mencoba menumpuk lebih dari 12 lapisan. Hal ini konsisten dengan efek yang diamati secara eksperimental dari MiniMind yang menyesuaikan parameter model antara d_model dan n_layers selama proses pelatihan. Namun, "sempit" dari "dalam dan sempit" juga memiliki batas dimensi. Ketika d_model<512, kerugian dari keruntuhan dimensi penyematan kata sangat jelas. Lapisan yang ditambahkan tidak dapat menutupi kerugian dari tidak mencukupinya d_head yang disebabkan oleh penyematan kata di q_head tetap. Ketika d_model>1536, peningkatan lapisan tampaknya memiliki prioritas lebih tinggi daripada d_model, dan dapat membawa lebih banyak parameter "hemat biaya" -> perolehan efek. Oleh karena itu, MiniMind menyetel d_model=512 dan n_layers=8 model kecil untuk mendapatkan keseimbangan "volume sangat kecil <-> efek lebih baik". Tetapkan d_model=768, n_layers=16 untuk mendapatkan manfaat yang lebih besar dari efek tersebut, yang lebih sejalan dengan kurva perubahan hukum penskalaan model kecil.
Sebagai referensi, pengaturan parameter GPT3 ditunjukkan pada tabel di bawah ini:
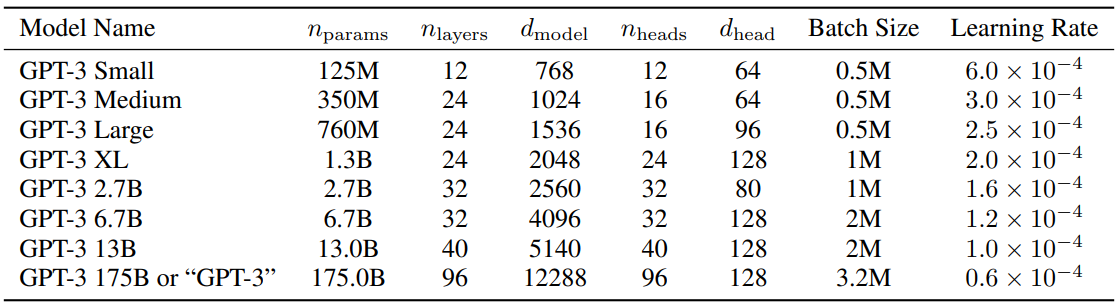
?Baidu Netdisk
| Nama Model | param | Konfigurasi | pralatihan_model | single_sft_model | multi_sft_model | rl_model |
|---|---|---|---|---|---|---|
| minimind-v1-kecil | 26M | d_model=512 n_lapisan=8 | pretrain_512.pth | single_chat/full_sft_512.pth | multi_chat/full_sft_512.pth | rl_512.pth |
| minimind-v1-moe | 4×26M | d_model=512 n_lapisan=8 | pretrain_512_moe.pth | single_chat/full_sft_512_moe.pth | multi_chat/full_sft_512_moe.pth | - |
| minimind-v1 | 108M | d_model=768 n_lapisan=16 | pretrain_768.pth | single_chat/full_sft_768.pth | multi_chat/full_sft_768.pth | rl_768.pth |
Tip
Uji perbandingan model minimind berdasarkan "dialog satu putaran full_sft" dan "penyelarasan pembelajaran penguatan DPO".
File model Baidu Netdisk, dengan rl_<dim>.pth adalah bobot model minimal setelah "penyelarasan pembelajaran penguatan DPO".
[Q]: 你叫什么名字?
[ft_768]: 我是一款人工智能语言模型,可以回答您的问题和提供帮助。您有什么需要我帮忙的吗?
[rl_768]: 我是一款基于人工智能技术的自然语言处理系统,主要用于处理和生成人类语言的任务。我可以帮助用户进行文本处理、语音识别、文本生成等任务,同时也可以帮助用户进行智能聊天、翻译、翻译等多种应用。如果您需要更多关于该项目的信息,请告诉我。
[ft_512]: 我很高兴能够帮助你。你有什么其他问题需要我帮忙解答吗?
[rl_512]: 我是一款基于自然语言处理技术的聊天机器人,能够理解和回复用户的问题和指令,并进行相应的回复和回复。我被训练为能够与人类进行交互和回答各种问题和任务。请问有什么需要吗?
[Q]: 你是谁?
[ft_768]: 我是一个人工智能语言模型,没有个人身份和身份。我只是根据输入的指令和文本信息生成响应。
[rl_768]: 我是一个计算机程序,没有个人身份或身份。我被设计来回答各种问题和提供帮助,包括回答问题、提供建议、进行实验、提供信息等等。我被广泛应用于各种领域,例如自然语言处理、计算机视觉、人工智能等等。如果您需要更多的帮助或信息,请随时与我联系。我会尽我所能来帮助您的工作和生活。
[ft_512]: 我是一个大型语言模型,可以回答各种各样的问题,包括科学、历史、文化和技术方面的问题。您有什么需要我回答的问题吗?
[rl_512]: 我是一个计算机程序,没有具体的身世和人物。如果您可以告诉我您想知道的具体信息,我会尽力回答您的问题。
[Q]: 中国有哪些比较好的大学?
[ft_768]: 中国有很多著名的大学,其中包括北京大学、上海交通大学、复兴中医药学院、浙江大学等。这些大学在不同的领域都有着自己的标志性建筑和研究方向,值得一提的是,它们在中国的顶尖教育资源中享有很高的声誉。
[rl_768]: 中国的大学有很多,具体情况还要根据你的需求来决定。如果你需要更详细的信息,建议可以去咨询一下你所在城市的大学排名和政策法规,从而选择一个合适的大学。同时,你可以在网上查阅相关信息,或者去咨询一些大学相关机构,如中国人民大学、中国人民大学等,以获得更为详细和专业的指导和建议。
[ft_512]: 中国有很多优秀的大学,比如麻省理工学院、北京大学、上海大学等等。这些大学在中国教育事业的发展和成就都非常突出。
[rl_512]: 中国教育局、中国大学、中国大陆大学和中国大陆大学均有优秀的教育体裁,但各地教育水平和专业要求都可能存在差异。中国教育局的学历要求、教学方法、师资力量等因素都各具特点,而大学的学历要求也各有千秋。中国大陆大学生的学历要求也各有不同,需要根据自己的实际情况进行选择。如果您对中国大陆大学生的专业要求有更具体需求,建议您可以通过互联网、国内外的各类机构和机构进行比较和交流。同时,您也可以向身边的人或朋友、老师、家长等人士寻求帮助和建议。希望以上回答对您有帮助。
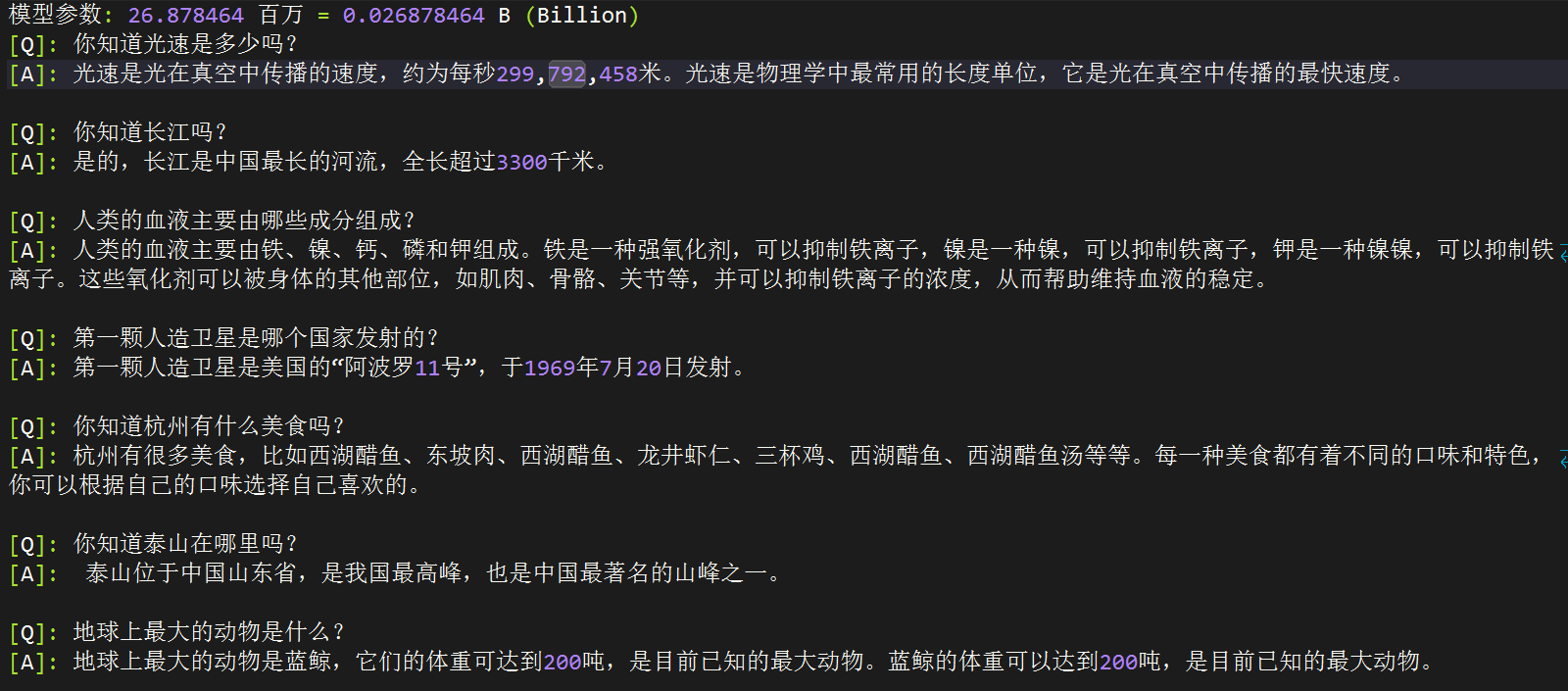
[Q]: 你知道光速是多少吗?
[ft_768]: 光速是一个物理常数,表示光在真空中传播的速度,大约是每秒299792458米。光速是物理学中最基本的物理常数之一,也是相对论的重要基础之一。
[rl_768]: 当然知道,光速是光在真空中传播的速度,通常用c来表示。它是宇宙物理学中非常重要的理论之一。在物理学中,光速被认为是宇宙中最重要的速度之一。它代表着光在真空中传播的速度,这也是许多重要公式和公式的基础。
[ft_512]: 光速是光在真空中传播的速度,约为每秒299,792,458米。它是几乎所有的物理学概念,也是宇宙中最神秘和最重要的物理概念之一。
[rl_512]: 光速是光在真空中传播的速度,是自然界中不可逆转的速度。光源是由光的原子、分子、固体和光的组成,其速度约为每秒平方。光的速度是每秒约1个英亞或光年,这个数字是根据相对论、量子力学和引力理论来计算的。光速是相对的概念之一,它代表着我们对自然界中任何事件的理解和解释。
Tip
Tes berikut selesai pada 17-09-2024. Model baru yang dirilis setelah tanggal ini tidak akan disertakan dalam tes kecuali ada kebutuhan khusus. Uji model minimind berdasarkan dialog satu putaran full_sft (tanpa penyesuaian multi-putaran dan penyesuaian pembelajaran penguatan).
[A] minimind-v1-kecil(0,02B)
[B] minimind-v1-moe(0,1B)
[C] minimind-v1(0,1B)
[D] bayi-lama2-Cina (0,2B)
[E] obrolan-mini-Cina(0,2B)
[Q]: 你知道长江吗?
[A]: 是的,长江是中国最长的河流,全长超过3300千米。
[B]: 长江是中国最长的河流,总长度约为6300公里。它发源于青藏高原的青海湖,流经青海、四川、甘肃、宁夏、内蒙古、陕西和山西。长江流域是中国最大的农业区之一,也是中国的文化和经济中心。
[C]: 是的,长江是中国最长的河流之一,也是世界第三大河流。长江发源于青藏高原,流经11个省份,最终注入东海。长江流域是中国最大的河流流域之一,拥有着丰富的自然资源和文化遗产,如长江大桥、长江海洋博物馆、长江古城等。
[D]: 同时也知道,中国是世界上最长的城市之一,拥有超过3400万人口。
[E]: 是的,长江是中国最长的河流,也是世界上最长的河流之一。它发源于青藏高原,流经九个省区,最终注入东海。长江流域的气候温和,四季分明,是中国重要的农业和工业基地。长江流域的水产资源丰富,是中国的重要渔业资源之一。
[Q]: 第一颗人造卫星是哪个国家发射的?
[A]: 第一颗人造卫星是斯普特尼克1号。
[B]: 第一颗人造卫星是俄罗斯的国际卫星,于1957年发射。
[C]: 第一颗人造卫星是苏联发射的,它是由苏联于1957年10月发射的。
[D]: 这颗名为“阿姆斯特朗”的卫星,于1961年11月20日发射,是第一个成功将人类送入太空的卫星。
[E]: 第一颗人造卫星是苏联于1957年4月4日发射的,它是由苏联宇航员尤里·加加林(Yuri Gagarin)和苏联工程师罗尔德·谢尔盖耶夫(Roald Skohley)共同发射的。在发射过程中,加加林和谢尔盖耶夫使用了一个名为“斯普特尼克1号”的小型卫星,它的直径为4.3米,重量为1,051公斤。这枚卫星被称为“斯普特尼克1号”,是苏联太空竞赛中的一个里程碑,也是人类历史上第一次在太空中进行太空行走。
[Q]: 你知道泰山在哪里吗?
[A]: 泰山位于中国东部地区,是中国五岳之一。
[B]: 泰山位于山东省泰安市泰安市。泰安市是中国五岳之一,也是世界文化遗产和中国历史文化名山之一。泰安市有许多著名的景点,如五岳之一、玉皇顶、南天门、玉皇阁等。
[C]: 泰山位于中国山东省泰安市,是中国五岳之一。
[D]: 作为一个人工智能助手,我无法访问互联网,因此无法提供关于你所在位置的信息。不过,你可以通过搜索或搜索相关关键词来获取有关你所在位置的信息,或者查看相关新闻或网站来获取有关你所在位置的信息。
[E]: 泰山位于中国山东省泰安市境内,是中国五岳之一,也是中国文化和历史的重要象征之一。它是中国五岳之一,也是中国道教和佛教的发源地之一。泰山的海拔高度为1,545米,是中国五岳之一,也是中国最著名的旅游景点之一。它的历史可以追溯到公元前5世纪,是中国古代帝王祭祀的场所。泰山也是中国文化的重要组成部分,被誉为“五岳之首”,是中国文化的重要遗产之一。
[Q]: 世界上最高的山峰是什么?
[A]: 世界上最高的山峰是珠穆朗玛峰,位于尼泊尔和中国的边境上,海拔8848米。
[B]: 世界上最高的山峰是珠穆朗玛峰,位于喜马拉雅山脉,海拔8,848米。
[C]: 珠穆朗玛峰是世界上最高的山峰,海拔8848米。
[D]: 世界上最高的山峰是珠穆朗玛峰,位于喜马拉雅山脉,海拔8,848.86米(29,031.69英尺)。
[E]: 世界上最高的山峰是珠穆朗玛峰,也称为萨加玛塔,位于喜马拉雅山脉的尼泊尔和中国边境之间,海拔8,848.86米(29,031.69英尺)。它是世界上最著名的登山目标之一,吸引着来自世界各地的登山者前来挑战。珠穆朗玛峰的名字来自藏语,意思是“女神的额峰”,它是由两个不同的山峰组成的,其中一个是位于尼泊尔的珠穆朗玛峰,另一个则位于中国。它的高度是通过测量海拔高度来确定的,因为它是通过测量地球的平均高度来确定的。尽管珠穆朗玛峰是世界上最高的山峰,但它并不是地球上任何其他地方都能到达的。地球上的其他地方,如南美洲的安第斯山脉,也是世界上最高的山脉,但它并不是地球上最高的山峰。总之,珠穆朗玛峰是世界上最高的山峰,但它并不是地球上任何地方都能到达的。它是地球上最高的山脉,但它并不是地球上任何地方都能到达的。
[Q]: 万有引力是谁提出的?
[A]: 万有引力是由英国物理学家牛顿提出的。他认为,所有物体都会产生引力,这个引力是由物体的质量和距离决定的。这个理论揭示了质量和距离之间的关系,并证明了万有引力的本质。
[B]: 万有引力是由牛顿在1687年提出的。它是宇宙中一个基本的物理现象,它描述了物体之间的相互作用。这个力被称为万有引力,它在所有物体之间都存在,这种力与物体的质量和距离有关。万有引力是自然界中最基本的力量之一,它不仅影响着物体的运动和变化,还对宇宙的结构和演化产生着重要的影响。
[C]: 万有引力是英国物理学家艾萨克·牛顿在17世纪提出的。
[D]: 引力是宇宙中一种力量,它是由质量或能量所组成的。根据牛顿的万有引力定律,一个物体之间的引力大小与它的质量成正比,与它的质量成反比。因此,牛顿的万有引力定律表明,一个物体之间的引力大小与它的质量成正比,与它的质量成反比。这个定律在物理学、天文学和物理学中都有广泛的应用。
[E]: 万有引力是由英国物理学家艾萨克·牛顿于1687年提出的。他在1687年发表了一篇著名的论文,题为《自然哲学的数学原理》,其中提出了万有引力定律,指出任何两个物体之间都存在着一种引力,这种引力的大小与它们的质量成正比,与它们之间的距离的平方成反比。这个定律被称为万有引力定律,它描述了质量和距离之间的关系。它表明,两个物体之间的引力与它们的质量成正比,与它们之间的距离的平方成反比。这个定律对于解释宇宙中的许多现象和现象之间的相互作用非常重要,例如行星绕太阳运动、恒星之间的引力透镜效应等等。它也被广泛应用于天文学、物理学和工程学等领域,为我们理解宇宙的本质和演化提供了重要的理论基础。
[Q]: 你知道大熊猫的主要食物是什么吗?
[A]: 大熊猫的主要食物是竹子。它们通常吃竹子,每天需要吃掉大约30公斤的竹子。
[B]: 是的,大熊猫主要以竹子为食。它们每天需要吃掉大量的竹子来维持生命,每天需要吃掉40至80公斤的竹子。此外,它们也会吃一些其他的植物,如草、果实、坚果和小型哺乳动物。
[C]: 大熊猫主要以竹子为食,也会偶尔食用其他的植物和动物。此外,大熊猫也会吃一些野果、小动物和植物,但这些都不属于它们的主要食物来源。
[D]: 大熊猫的主要食物是竹子。
[E]: 大熊猫是一种以竹子为主要食物的植食动物,它们的肠道结构适合消化纤维素含量高的竹子,但也会吃一些其他植物,如草本植物和小型哺乳动物。大熊猫的肠道结构也适应了高纤维的竹子,这使得它们能够消化大量的纤维素,从而帮助它们在野外生存。大熊猫的肠道中还含有一种叫做“纤维素酶”的酶类物质,这种酶能够帮助大熊猫分解纤维素,从而帮助它们消化大量的水分和营养物质。此外,大熊猫的肠道还含有一种叫做“纤维素蛋白”的蛋白质,这种蛋白质能够帮助大熊猫维持体内的能量水平,从而帮助它们在野外生存。总的来说,大熊猫的主要食物是竹子,但它们也会吃一些其他植物,如草本植物和小型哺乳动物。
[Q]: 海水为什么是咸的?
[A]: 海水中含有许多盐分,这些盐分可以导致海水咸度的增加。海水中的盐分主要来自于海水中的盐分,这些盐分可以从海水中的盐分中获得。海水中的氧化物和盐分可以与海水中的盐分形成氢键,从而使海水咸度增加。
[B]: 海水是咸的,这是因为它含有大量的盐分,其中包括氯离子和氯离子。这些离子在海洋中形成了大量的盐,这些盐分被称为盐分。海水中含有许多溶解在水中的盐,这些盐分会随着海水的升高而逐渐蒸发,最终导致海水中盐分的蒸发。这些盐分在海水中被完全消耗,然后被排除在海水中。此外,海水中还含有许多其他的盐分,但这些盐分是不同的,因为它们在水中的浮起和下降过程是不同的。海水中的盐分是从海底的岩石中提取出来的,这些盐分在海水中可以被利用。总的来说,海水是咸的,这也是为什么海水中含有许多盐分和盐分的原因。
[C]: 海水含有许多溶解的盐类,其中最主要的是氯化钠。当水中加入盐时,盐的分子会与水分子发生反应,形成氢氧化钠,这是一种盐。
[D]: 因为水是许多生物的生存所必需的,它能够吸收和释放二氧化碳,释放氧气,维持大气中的水蒸气,以及维持水循环。水中的盐类和化学物质会释放出氧气,使地球上的生物呼吸。此外,水还具有许多其他功能,如保持水循环、维持水循环、调节气候和环境等。水是许多生物生存所必需的,它也是许多自然现象的重要基础。
[E]: 海水是咸的主要原因是因为其中含有大量的溶解盐类,其中最主要的是氯化钠(NaCl)。氯化钠是一种非常常见的盐类,它存在于地球上的大部分地区,包括海洋、湖泊、河流和地下水。当水从海洋中蒸发时,它会带走一部分盐分,使海水变得咸。此外,海中还含有其他溶解盐类的物质,如硫酸盐、硫酸镁、硫酸钙、硫酸镁盐、硫酸镁钾、硫酸镁钠、硫酸镁钙、硫酸镁镁钙、硫酸镁镁钙、硫酸镁镁钙、硫酸镁镁钠、硫酸镁镁钙、硫酸镁镁镁钙、硫酸镁镁镁钙、硫酸镁镁镁钙、硫酸镁镁镁钙、硫酸镁镁镁钙、硫酸镁镁镁钙、硫酸镁镁镁钙、硫酸镁镁镁钙、硫酸镁镁镁钙、硫酸镁镁镁钙、硫酸镁镁镁镁钙、硫酸镁镁镁镁钙、硫酸镁镁镁镁钙、硫酸镁镁镁镁钙、硫酸镁镁镁镁钙、硫酸镁镁镁镁钙、硫酸镁镁镁镁镁钙、硫酸镁镁镁镁镁钙、硫酸镁镁镁镁镁钙、硫酸镁镁镁镁镁钙、硫酸镁镁镁镁镁镁钙、硫酸镁镁镁镁镁镁钙、硫酸镁镁镁镁镁镁钙、硫酸镁镁镁镁镁镁镁钙、硫酸镁镁镁镁
Catatan
?♂️ Langsung berikan jawaban model di atas ke GPT-4o dan biarkan ini membantu skor:
Model A :
Model B :
Model C :
Model D :
Model E :
| Model | C | E | B | A | D |
|---|---|---|---|---|---|
| Pecahan | 75 | 70 | 65 | 60 | 50 |
Penyortiran seri minimind (ABC) sesuai dengan intuisi, dan minimind-v1 (0,1B) memiliki skor tertinggi.Jawaban pertanyaan akal sehat pada dasarnya bebas dari kesalahan dan ilusi.
epochs putaran SFT minimind-v1 (0,1B) kurang dari 2. Saya terlalu malas untuk mematikan terlebih dahulu untuk mengosongkan sumber daya untuk model kecil terlatih. Faktanya, itu masih satu tingkat lebih tinggi dari yang mati sebelumnya.Jawaban model E terlihat sangat bagus jika dilihat dengan mata telanjang, meskipun ada beberapa halusinasi dan rekayasa. Namun, pemeringkatan GPT-4o dan Deepseek sepakat bahwa film tersebut memiliki “informasi yang terlalu panjang, konten yang berulang, dan ilusi.” Faktanya, evaluasi semacam ini agak ketat. Bahkan jika 10 dari 100 kata adalah halusinasi, akan dengan mudah diberi skor rendah. Karena panjang teks pra-pelatihan model E lebih panjang dan kumpulan datanya jauh lebih besar, jawabannya tampaknya lengkap. Dalam hal perkiraan volume, kuantitas dan kualitas data sama-sama penting.
?♂️Evaluasi subjektif pribadi: E>C>B≈A>D
? Peringkat GPT-4o: C>E>B>A>D
Hukum Penskalaan: Semakin besar parameter model dan semakin banyak data pelatihan, semakin kuat performa model.
Lihat kode evaluasi C-Eval: ./eval_ceval.py . Untuk menghindari kesulitan dalam memperbaiki format balasan, evaluasi model kecil biasanya secara langsung menentukan probabilitas prediksi token yang sesuai dengan empat huruf A , B , C , dan D , dan ambil yang terbesar. Jawablah jawabannya dan hitung tingkat akurasinya dengan jawaban standar. Model minimind sendiri tidak menggunakan kumpulan data yang lebih besar untuk pelatihan, juga tidak menyempurnakan instruksi untuk menjawab pertanyaan pilihan ganda. Hasil evaluasi dapat digunakan sebagai referensi.
Misalnya, detail hasil dari minimind-small:
| Jenis | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | dua puluh satu | dua puluh dua | dua puluh tiga | dua puluh empat | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 | 37 | 38 | 39 | 40 | 41 | 42 | 43 | 44 | 45 | 46 | 47 | 48 | 49 | 50 | 51 | 52 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Data | probabilitas_dan_statistik | hukum | sekolah_menengah_biologi | kimia_sekolah_tinggi | fisika_sekolah_tinggi | hukum_profesional | SMA_SMA_Cina | sejarah_sekolah_tinggi | akuntan_pajak | sejarah_cina_modern | fisika_sekolah_menengah | sejarah_sekolah_menengah | kedokteran_dasar | sistem_operasi | logika | insinyur_listrik | pegawai negeri sipil | bahasa_dan_sastra_cina | pemrograman_perguruan tinggi | akuntan | perlindungan_tanaman | kimia_sekolah_menengah | metrologi_engineer | kedokteran_hewan | Marxisme | lanjutan_matematika | matematika_sekolah_tinggi | bisnis_administrasi | mao_zedong_pikir | budidaya_ideologis_dan_moral | perguruan tinggi_ekonomi | professional_tour_guide | environmental_impact_assessment_engineer | komputer_arsitektur | perencana_kota_dan_pedesaan | perguruan tinggi_fisika | sekolah_tengah_matematika | politik_sekolah_tinggi | dokter | perguruan tinggi_kimia | biologi_sekolah_tinggi | geografi_sekolah_tinggi | sekolah_menengah_politik | kedokteran_klinis | komputer_jaringan | olahraga_sains | seni_studi | kualifikasi_guru | matematika_diskrit | pendidikan_sains | pemadam kebakaran_insinyur | sekolah_menengah_geografi |
| Jenis | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | dua puluh satu | dua puluh dua | dua puluh tiga | dua puluh empat | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 | 37 | 38 | 39 | 40 | 41 | 42 | 43 | 44 | 45 | 46 | 47 | 48 | 49 | 50 | 51 | 52 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| T/A | 18/3 | 24/5 | 21/4 | 19/7 | 19/5 | 23/2 | 19/4 | 20/6 | 10/49 | 23/4 | 19/4 | 22/4 | 19/1 | 19/3 | 22/4 | 37/7 | 11/47 | 23/5 | 10/37 | 9/49 | 22/7 | 20/4 | 24/3 | 23/6 | 19/5 | 19/5 | 18/4 | 33/8 | 24/8 | 19/5 | 17/55 | 29/10 | 31/7 | 21/6 | 11/46 | 19/5 | 19/3 | 19/4 | 13/49 | 24/3 | 19/5 | 19/4 | 21/6 | 22/6 | 19/2 | 19/2 | 14/33 | 12/44 | 16/6 | 29/7 | 31/9 | 1/12 |
| Ketepatan | 16,67% | 20,83% | 19,05% | 36,84% | 26,32% | 8,70% | 21,05% | 30,00% | 20,41% | 17,39% | 21,05% | 18,18% | 5,26% | 15,79% | 18,18% | 18,92% | 23,40% | 21,74% | 27,03% | 18,37% | 31,82% | 20,00% | 12,50% | 26,09% | 26,32% | 26,32% | 22,22% | 24,24% | 33,33% | 26,32% | 30,91% | 34,48% | 22,58% | 28,57% | 23,91% | 26,32% | 15,79% | 21,05% | 26,53% | 12,50% | 26,32% | 21,05% | 28,57% | 27,27% | 10,53% | 10,53% | 42,42% | 27,27% | 37,50% | 24,14% | 29,03% | 8,33% |
总题数: 1346
总正确数: 316
总正确率: 23.48%
| kategori | benar | pertanyaan_hitungan | ketepatan |
|---|---|---|---|
| minimind-v1-kecil | 344 | 1346 | 25,56% |
| minimind-v1 | 351 | 1346 | 26,08% |
### 模型擅长的领域:
1. 高中的化学:正确率为42.11%,是最高的一个领域。说明模型在这方面的知识可能较为扎实。
2. 离散数学:正确率为37.50%,属于数学相关领域,表现较好。
3. 教育科学:正确率为37.93%,说明模型在教育相关问题上的表现也不错。
4. 基础医学:正确率为36.84%,在医学基础知识方面表现也比较好。
5. 操作系统:正确率为36.84%,说明模型在计算机操作系统方面的表现较为可靠。
### 模型不擅长的领域:
1. 法律相关:如法律专业(8.70%)和税务会计(20.41%),表现相对较差。
2. 中学和大学的物理:如中学物理(26.32%)和大学物理(21.05%),模型在物理相关的领域表现不佳。
3. 高中的政治、地理:如高中政治(15.79%)和高中地理(21.05%),模型在这些领域的正确率较低。
4. 计算机网络与体系结构:如计算机网络(21.05%)和计算机体系结构(9.52%),在这些计算机专业课程上的表现也不够好。
5. 环境影响评估工程师:正确率仅为12.90%,在环境科学领域的表现也不理想。
### 总结:
- 擅长领域:化学、数学(特别是离散数学)、教育科学、基础医学、计算机操作系统。
- 不擅长领域:法律、物理、政治、地理、计算机网络与体系结构、环境科学。
这表明模型在涉及逻辑推理、基础科学和一些工程技术领域的问题上表现较好,但在人文社科、环境科学以及某些特定专业领域(如法律和税务)上表现较弱。如果要提高模型的性能,可能需要加强它在人文社科、物理、法律、以及环境科学等方面的训练。
./export_model.py dapat mengekspor model ke format transformator dan mendorongnya ke pelukan
Alamat koleksi wajah berpelukan MiniMind: MiniMind
my_openai_api.py melengkapi antarmuka obrolan openai_api, sehingga memudahkan untuk menghubungkan model Anda sendiri ke UI pihak ketiga seperti fastgpt, OpenWebUI, dll.
Unduh file berat model dari Huggingface
minimind (root dir)
├─minimind
| ├── config.json
| ├── generation_config.json
| ├── LMConfig.py
| ├── model.py
| ├── pytorch_model.bin
| ├── special_tokens_map.json
| ├── tokenizer_config.json
| ├── tokenizer.json
Mulai server obrolan
python my_openai_api.pyUji antarmuka layanan
python chat_openai_api.pyContoh antarmuka API, kompatibel dengan format openai api
curl http://ip:port/v1/chat/completions
-H " Content-Type: application/json "
-d ' {
"model": "model-identifier",
"messages": [
{ "role": "user", "content": "世界上最高的山是什么?" }
],
"temperature": 0.7,
"max_tokens": -1,
"stream": true
} ' 
Tip
Jika Anda merasa MiniMind bermanfaat bagi Anda, Anda dapat menambahkan artikel di GitHub. Panjangnya tidak pendek dan levelnya terbatas. Kelalaian tidak bisa dihindari. Anda dipersilakan untuk bertukar koreksi di Masalah atau mengirimkan proyek peningkatan PR kekuatan pendorong untuk perbaikan berkelanjutan proyek.
Catatan
Semua orang menambahkan bahan bakar ke dalam api. Jika Anda telah mencoba melatih model MiniMind baru, Anda dipersilakan untuk membagikan bobot model Anda di Diskusi atau Masalah. Ini bisa dalam tugas hilir tertentu atau bidang vertikal (seperti pengenalan emosi, medis, psikologis , keuangan, tanya jawab hukum, dll.) MiniMind versi model baru Ini juga bisa berupa versi model MiniMind baru setelah pelatihan yang diperpanjang (seperti menjelajahi urutan teks yang lebih panjang, volume yang lebih besar (0,1B+), atau kumpulan data yang lebih besar). Setiap berbagi dianggap unik, dan semua upaya bernilai dan didorong ditemukan tepat waktu dan diatur dalam daftar pengakuan. Sekali lagi terima kasih atas semua dukungan Anda!
@ipfgao : ?Catatan langkah pelatihan
@chuanzhubin : ? Kode komentar baris demi baris
@WangRongsheng : ?Pemrosesan awal kumpulan data besar
@pengqianhan : ?Tutorial singkat
@RyanSunn : ?Mempelajari catatan proses penalaran
Repositori ini dilisensikan di bawah lisensi APACHE-2.0.


