e2 tts pytorch
1.7.1
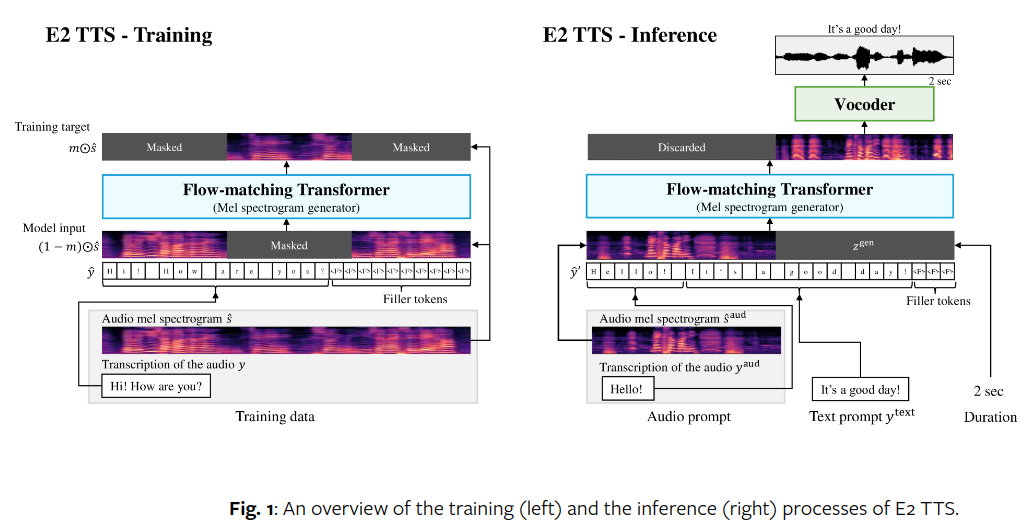
Implementasi E2-TTS, TTS Zero-Shot Non-Autoregresif yang Sangat Mudah dan Memalukan, di Pytorch
Repositori berbeda dari kertas karena menggunakan trafo multistream untuk teks dan audio, dengan pengkondisian dilakukan setiap blok trafo dengan cara E2.
Ini juga mencakup improvisasi yang dibuktikan oleh Manmay, di mana teks hanya diinterpolasi sepanjang audio untuk pengkondisian. Anda dapat mencobanya dengan mengatur interpolated_text = True pada E2TTS
Manmay karena telah menyumbangkan kode pelatihan ujung ke ujung yang berfungsi!
Lucas Newman atas kontribusi kode, masukan yang bermanfaat, dan berbagi rangkaian eksperimen positif pertama!
Jing karena telah membagikan hasil positif kedua dengan kumpulan data multibahasa (Inggris + Mandarin)!
Coice dan Manmay karena melaporkan keberhasilan ketiga dan keempat. Rekayasa penyelarasan perpisahan
$ pip install e2-tts-pytorch import torch
from e2_tts_pytorch import (
E2TTS ,
DurationPredictor
)
duration_predictor = DurationPredictor (
transformer = dict (
dim = 512 ,
depth = 8 ,
)
)
mel = torch . randn ( 2 , 1024 , 100 )
text = [ 'Hello' , 'Goodbye' ]
loss = duration_predictor ( mel , text = text )
loss . backward ()
e2tts = E2TTS (
duration_predictor = duration_predictor ,
transformer = dict (
dim = 512 ,
depth = 8
),
)
out = e2tts ( mel , text = text )
out . loss . backward ()
sampled = e2tts . sample ( mel [:, : 5 ], text = text ) @inproceedings { Eskimez2024E2TE ,
title = { E2 TTS: Embarrassingly Easy Fully Non-Autoregressive Zero-Shot TTS } ,
author = { Sefik Emre Eskimez and Xiaofei Wang and Manthan Thakker and Canrun Li and Chung-Hsien Tsai and Zhen Xiao and Hemin Yang and Zirun Zhu and Min Tang and Xu Tan and Yanqing Liu and Sheng Zhao and Naoyuki Kanda } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:270738197 }
} @inproceedings { Darcet2023VisionTN ,
title = { Vision Transformers Need Registers } ,
author = { Timoth'ee Darcet and Maxime Oquab and Julien Mairal and Piotr Bojanowski } ,
year = { 2023 } ,
url = { https://api.semanticscholar.org/CorpusID:263134283 }
} @article { Bao2022AllAW ,
title = { All are Worth Words: A ViT Backbone for Diffusion Models } ,
author = { Fan Bao and Shen Nie and Kaiwen Xue and Yue Cao and Chongxuan Li and Hang Su and Jun Zhu } ,
journal = { 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) } ,
year = { 2022 } ,
pages = { 22669-22679 } ,
url = { https://api.semanticscholar.org/CorpusID:253581703 }
} @article { Burtsev2021MultiStreamT ,
title = { Multi-Stream Transformers } ,
author = { Mikhail S. Burtsev and Anna Rumshisky } ,
journal = { ArXiv } ,
year = { 2021 } ,
volume = { abs/2107.10342 } ,
url = { https://api.semanticscholar.org/CorpusID:236171087 }
} @inproceedings { Sadat2024EliminatingOA ,
title = { Eliminating Oversaturation and Artifacts of High Guidance Scales in Diffusion Models } ,
author = { Seyedmorteza Sadat and Otmar Hilliges and Romann M. Weber } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:273098845 }
} @article { Gulati2020ConformerCT ,
title = { Conformer: Convolution-augmented Transformer for Speech Recognition } ,
author = { Anmol Gulati and James Qin and Chung-Cheng Chiu and Niki Parmar and Yu Zhang and Jiahui Yu and Wei Han and Shibo Wang and Zhengdong Zhang and Yonghui Wu and Ruoming Pang } ,
journal = { ArXiv } ,
year = { 2020 } ,
volume = { abs/2005.08100 } ,
url = { https://api.semanticscholar.org/CorpusID:218674528 }
} @article { Yang2024ConsistencyFM ,
title = { Consistency Flow Matching: Defining Straight Flows with Velocity Consistency } ,
author = { Ling Yang and Zixiang Zhang and Zhilong Zhang and Xingchao Liu and Minkai Xu and Wentao Zhang and Chenlin Meng and Stefano Ermon and Bin Cui } ,
journal = { ArXiv } ,
year = { 2024 } ,
volume = { abs/2407.02398 } ,
url = { https://api.semanticscholar.org/CorpusID:270878436 }
} @article { Li2024SwitchEA ,
title = { Switch EMA: A Free Lunch for Better Flatness and Sharpness } ,
author = { Siyuan Li and Zicheng Liu and Juanxi Tian and Ge Wang and Zedong Wang and Weiyang Jin and Di Wu and Cheng Tan and Tao Lin and Yang Liu and Baigui Sun and Stan Z. Li } ,
journal = { ArXiv } ,
year = { 2024 } ,
volume = { abs/2402.09240 } ,
url = { https://api.semanticscholar.org/CorpusID:267657558 }
} @inproceedings { Zhou2024ValueRL ,
title = { Value Residual Learning For Alleviating Attention Concentration In Transformers } ,
author = { Zhanchao Zhou and Tianyi Wu and Zhiyun Jiang and Zhenzhong Lan } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:273532030 }
} @inproceedings { Duvvuri2024LASERAW ,
title = { LASER: Attention with Exponential Transformation } ,
author = { Sai Surya Duvvuri and Inderjit S. Dhillon } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:273849947 }
} @article { Zhu2024HyperConnections ,
title = { Hyper-Connections } ,
author = { Defa Zhu and Hongzhi Huang and Zihao Huang and Yutao Zeng and Yunyao Mao and Banggu Wu and Qiyang Min and Xun Zhou } ,
journal = { ArXiv } ,
year = { 2024 } ,
volume = { abs/2409.19606 } ,
url = { https://api.semanticscholar.org/CorpusID:272987528 }
}

