triton transformer
0.1.1
Implementasi Transformer, tetapi sepenuhnya di Triton. Saya benar-benar baru dalam kode jaringan saraf tingkat rendah, jadi repositori ini sebagian besar akan menjadi pengalaman belajar, dengan tujuan akhirnya menjadi transformator vanilla yang lebih cepat dan efisien untuk dilatih.
Norma lapisan ke depan
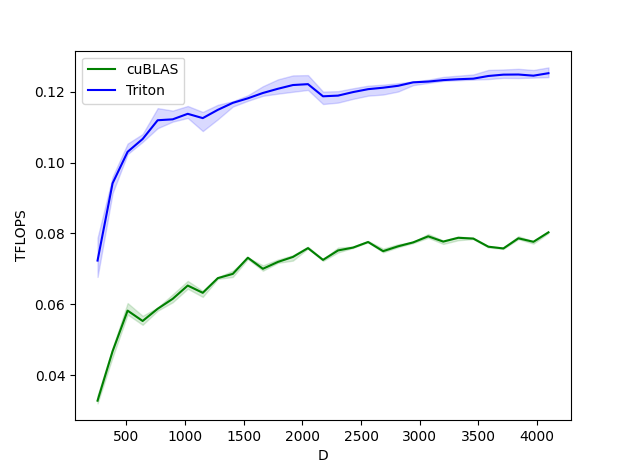
Layernorm maju dan mundur
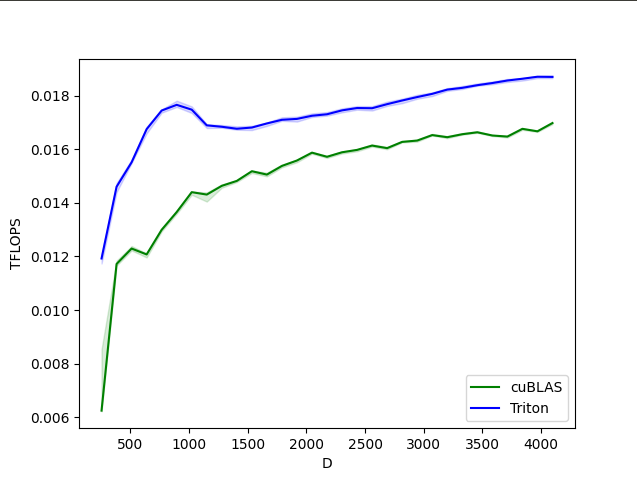
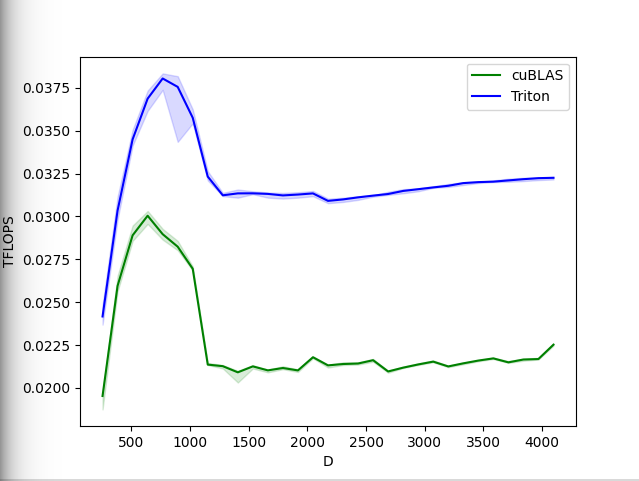
Softmax maju dan mundur
$ pip install triton-transformer import torch
from triton_transformer import Transformer
model = Transformer (
num_tokens = 256 , # vocab size
max_seq_len = 1024 , # maximum sequence length
dim = 512 , # dimension
depth = 6 , # depth
heads = 8 , # number of heads
dim_head = 64 , # dimension per head
causal = True , # autoregressive or not
attn_dropout = 0.1 , # attention dropout
ff_dropout = 0.1 , # feedforward dropout
use_triton = True # use this to turn on / off triton
). cuda ()
x = torch . randint ( 0 , 256 , ( 1 , 1024 )). cuda ()
logits = model ( x ) # (1, 1024, 256) Untuk melatih, cukup masukkan label dengan kata kunci labels di depan, dan kehilangan entropi silang akan dikembalikan untuk backprop.
mantan. BERT
import torch
from triton_transformer import Transformer
model = Transformer (
num_tokens = 20000 ,
max_seq_len = 512 ,
dim = 512 ,
depth = 12 ,
heads = 8 ,
dim_head = 64 ,
use_triton = True
). cuda ()
x = torch . randint ( 0 , 20000 , ( 1 , 512 )). cuda ()
labels = torch . randint ( 0 , 20000 , ( 1 , 512 )). cuda ()
mask = torch . ones ( 1 , 512 ). bool (). cuda ()
loss = model ( x , mask = mask , labels = labels )
loss . backward ()$ python train.py @article { Tillet2019TritonAI ,
title = { Triton: an intermediate language and compiler for tiled neural network computations } ,
author = { Philippe Tillet and H. Kung and D. Cox } ,
journal = { Proceedings of the 3rd ACM SIGPLAN International Workshop on Machine Learning and Programming Languages } ,
year = { 2019 }
} @misc { vaswani2017attention ,
title = { Attention Is All You Need } ,
author = { Ashish Vaswani and Noam Shazeer and Niki Parmar and Jakob Uszkoreit and Llion Jones and Aidan N. Gomez and Lukasz Kaiser and Illia Polosukhin } ,
year = { 2017 } ,
eprint = { 1706.03762 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CL }
} @misc { so2021primer ,
title = { Primer: Searching for Efficient Transformers for Language Modeling } ,
author = { David R. So and Wojciech Mańke and Hanxiao Liu and Zihang Dai and Noam Shazeer and Quoc V. Le } ,
year = { 2021 } ,
eprint = { 2109.08668 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.LG }
} @article { chowdhery2022PaLM ,
title = { PaLM: Scaling Language Modeling with Pathways } ,
author = { Chowdhery, Aakanksha et al } ,
year = { 2022 }
}

