igel
v1.0.0
Alat pembelajaran mesin menyenangkan yang memungkinkan Anda melatih/menyesuaikan, menguji, dan menggunakan model tanpa menulis kode
Catatan
Saya juga sedang mengerjakan aplikasi desktop GUI untuk igel berdasarkan permintaan orang. Anda dapat menemukannya di Igel-UI.
Daftar isi
Tujuan dari proyek ini adalah untuk menyediakan pembelajaran mesin untuk semua orang , baik pengguna teknis maupun non-teknis.
Terkadang saya memerlukan alat yang dapat saya gunakan untuk membuat prototipe pembelajaran mesin dengan cepat. Baik untuk membuat bukti konsep, membuat draf model cepat untuk membuktikan suatu hal, atau menggunakan ML otomatis. Saya sering terjebak dalam menulis kode boilerplate dan terlalu memikirkan harus mulai dari mana. Oleh karena itu, saya memutuskan untuk membuat alat ini.
igel dibangun di atas kerangka ML lainnya. Ini memberikan cara sederhana untuk menggunakan pembelajaran mesin tanpa menulis satu baris kode pun . Igel sangat dapat disesuaikan , tetapi hanya jika Anda mau. Igel tidak memaksa Anda untuk menyesuaikan apa pun. Selain nilai default, igel dapat menggunakan fitur ml otomatis untuk menemukan model yang dapat berfungsi baik dengan data Anda.
Yang Anda perlukan hanyalah file yaml (atau json ), tempat Anda perlu menjelaskan apa yang ingin Anda lakukan. Itu saja!
Igel mendukung regresi, klasifikasi dan pengelompokan. Igel mendukung fitur ml otomatis seperti ImageClassification dan TextClassification
Igel mendukung jenis kumpulan data yang paling banyak digunakan di bidang ilmu data. Misalnya, kumpulan data masukan Anda dapat berupa file csv, txt, excel sheet, json, atau bahkan html yang ingin Anda ambil. Jika Anda menggunakan fitur ml otomatis, Anda bahkan dapat memasukkan data mentah ke igel dan igel akan mencari cara untuk mengatasinya. Lebih lanjut tentang ini nanti di contoh.
$ pip install -U igel Model yang didukung Igel:
+--------------------+----------------------------+-------------------------+
| regression | classification | clustering |
+--------------------+----------------------------+-------------------------+
| LinearRegression | LogisticRegression | KMeans |
| Lasso | Ridge | AffinityPropagation |
| LassoLars | DecisionTree | Birch |
| BayesianRegression | ExtraTree | AgglomerativeClustering |
| HuberRegression | RandomForest | FeatureAgglomeration |
| Ridge | ExtraTrees | DBSCAN |
| PoissonRegression | SVM | MiniBatchKMeans |
| ARDRegression | LinearSVM | SpectralBiclustering |
| TweedieRegression | NuSVM | SpectralCoclustering |
| TheilSenRegression | NearestNeighbor | SpectralClustering |
| GammaRegression | NeuralNetwork | MeanShift |
| RANSACRegression | PassiveAgressiveClassifier | OPTICS |
| DecisionTree | Perceptron | KMedoids |
| ExtraTree | BernoulliRBM | ---- |
| RandomForest | BoltzmannMachine | ---- |
| ExtraTrees | CalibratedClassifier | ---- |
| SVM | Adaboost | ---- |
| LinearSVM | Bagging | ---- |
| NuSVM | GradientBoosting | ---- |
| NearestNeighbor | BernoulliNaiveBayes | ---- |
| NeuralNetwork | CategoricalNaiveBayes | ---- |
| ElasticNet | ComplementNaiveBayes | ---- |
| BernoulliRBM | GaussianNaiveBayes | ---- |
| BoltzmannMachine | MultinomialNaiveBayes | ---- |
| Adaboost | ---- | ---- |
| Bagging | ---- | ---- |
| GradientBoosting | ---- | ---- |
+--------------------+----------------------------+-------------------------+Untuk ML otomatis:
Perintah bantuan sangat berguna untuk memeriksa perintah yang didukung dan argumen/opsi yang sesuai
$ igel --helpAnda juga dapat menjalankan bantuan pada sub-perintah, misalnya:
$ igel fit --helpIgel sangat dapat disesuaikan. Jika Anda tahu apa yang Anda inginkan dan ingin mengonfigurasi model Anda secara manual, periksa bagian berikutnya, yang akan memandu Anda tentang cara menulis file konfigurasi yaml atau json. Setelah itu, Anda tinggal memberi tahu igel, apa yang harus dilakukan dan di mana menemukan data dan file konfigurasi Anda. Berikut ini contohnya:
$ igel fit --data_path ' path_to_your_csv_dataset.csv ' --yaml_path ' path_to_your_yaml_file.yaml 'Namun, Anda juga dapat menggunakan fitur auto-ml dan membiarkan igel melakukan segalanya untuk Anda. Contoh yang bagus untuk ini adalah klasifikasi gambar. Bayangkan Anda sudah memiliki kumpulan data gambar mentah yang disimpan dalam folder bernama gambar
Yang harus Anda lakukan adalah menjalankan:
$ igel auto-train --data_path ' path_to_your_images_folder ' --task ImageClassificationItu saja! Igel akan membaca gambar dari direktori, memproses kumpulan data (mengonversi ke matriks, mengubah skala, membagi, dll...) dan mulai melatih/mengoptimalkan model yang berfungsi baik pada data Anda. Seperti yang Anda lihat, ini cukup mudah, Anda hanya perlu menyediakan jalur ke data Anda dan tugas yang ingin Anda lakukan.
Catatan
Fitur ini mahal secara komputasi karena igel akan mencoba banyak model berbeda dan membandingkan kinerjanya untuk menemukan model yang 'terbaik'.
Anda dapat menjalankan perintah bantuan untuk mendapatkan instruksi. Anda juga dapat menjalankan bantuan pada sub-perintah!
$ igel --helpLangkah pertama adalah menyediakan file yaml (Anda juga bisa menggunakan json jika mau)
Anda dapat melakukan ini secara manual dengan membuat file .yaml (disebut igel.yaml menurut konvensi tetapi Anda dapat memberi nama jika diinginkan) dan mengeditnya sendiri. Namun, jika Anda malas (dan mungkin memang demikian, seperti saya :D), Anda dapat menggunakan perintah igel init untuk memulai dengan cepat, yang akan membuat file konfigurasi dasar untuk Anda dengan cepat.
"""
igel init --help
Example:
If I want to use neural networks to classify whether someone is sick or not using the indian-diabetes dataset,
then I would use this command to initialize a yaml file n.b. you may need to rename outcome column in .csv to sick:
$ igel init -type " classification " -model " NeuralNetwork " -target " sick "
"""
$ igel initSetelah menjalankan perintah, file igel.yaml akan dibuat untuk Anda di direktori kerja saat ini. Anda dapat memeriksanya dan memodifikasinya jika Anda mau, jika tidak, Anda juga dapat membuat semuanya dari awal.
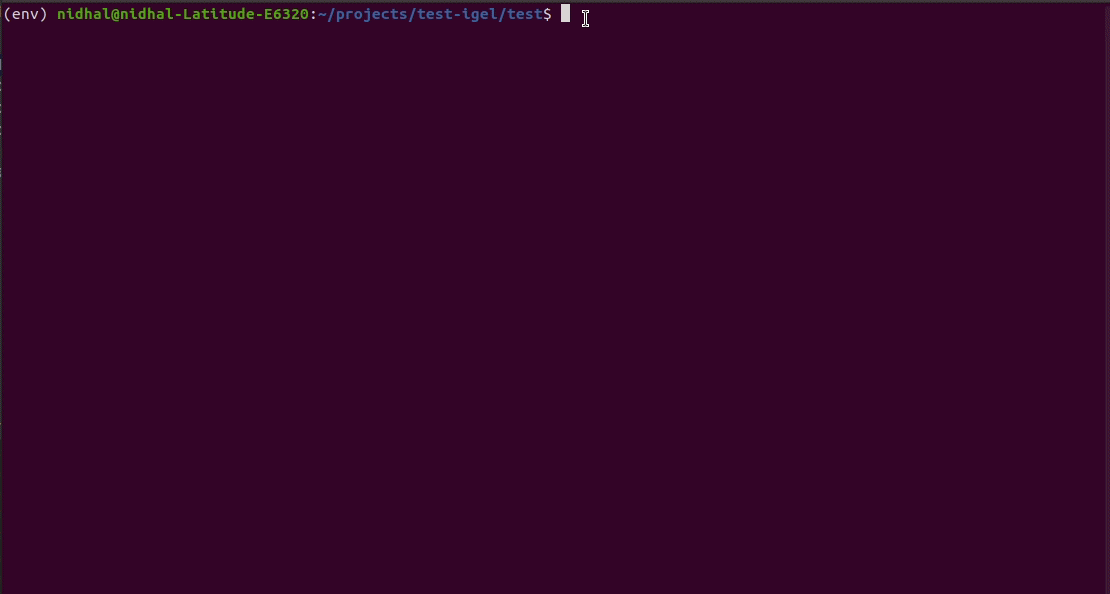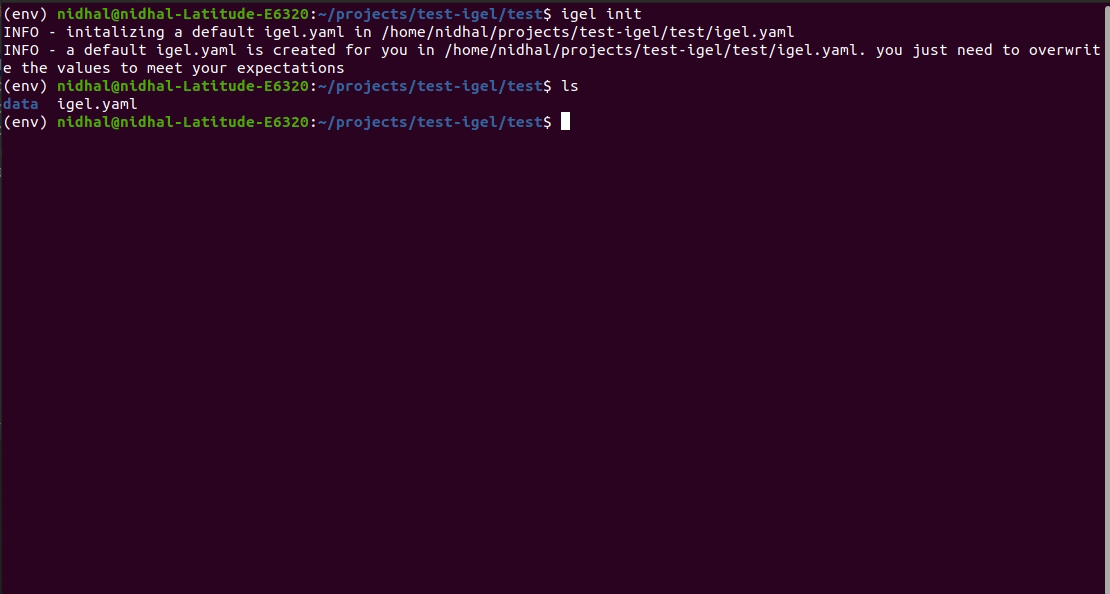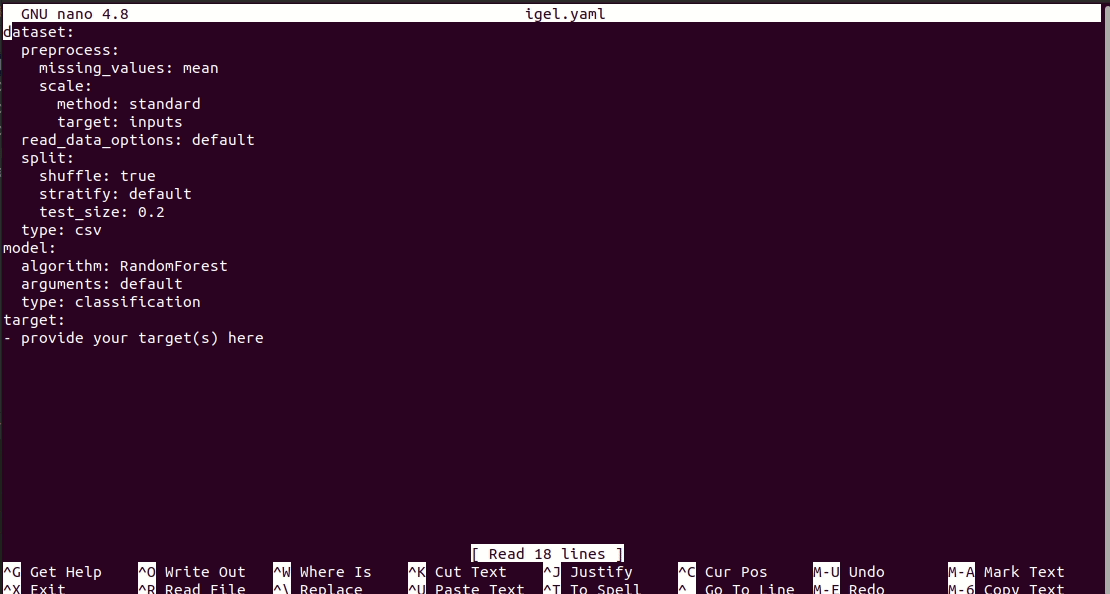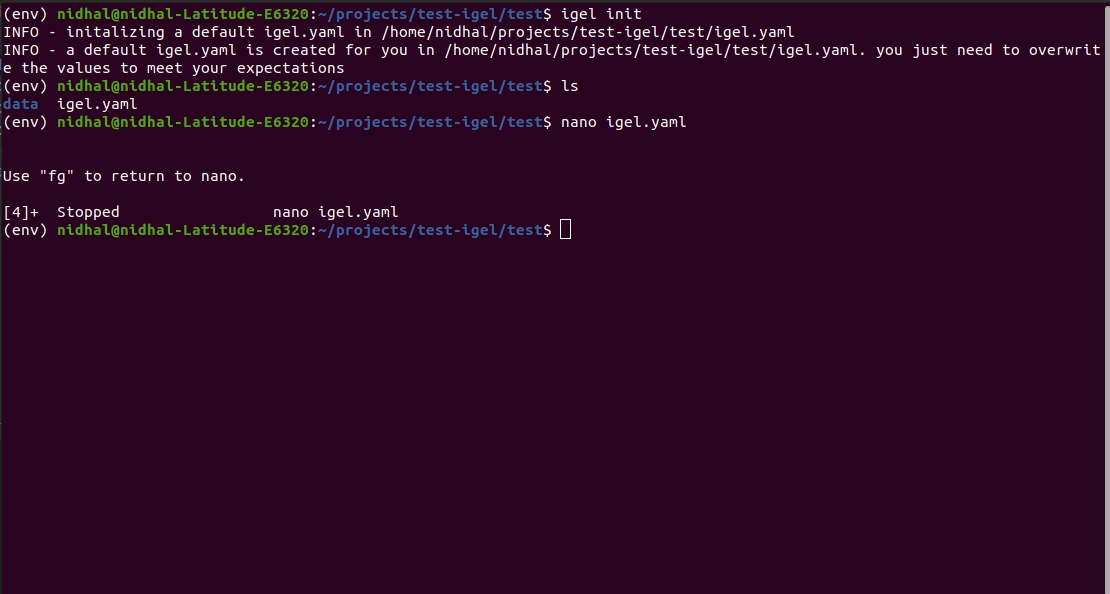
# model definition
model :
# in the type field, you can write the type of problem you want to solve. Whether regression, classification or clustering
# Then, provide the algorithm you want to use on the data. Here I'm using the random forest algorithm
type : classification
algorithm : RandomForest # make sure you write the name of the algorithm in pascal case
arguments :
n_estimators : 100 # here, I set the number of estimators (or trees) to 100
max_depth : 30 # set the max_depth of the tree
# target you want to predict
# Here, as an example, I'm using the famous indians-diabetes dataset, where I want to predict whether someone have diabetes or not.
# Depending on your data, you need to provide the target(s) you want to predict here
target :
- sickPada contoh di atas, saya menggunakan hutan acak untuk mengklasifikasikan apakah seseorang menderita diabetes atau tidak, bergantung pada beberapa fitur dalam kumpulan data. Saya menggunakan diabetes India yang terkenal dalam contoh ini kumpulan data diabetes India)
Perhatikan bahwa saya meneruskan n_estimators dan max_depth sebagai argumen tambahan pada model. Jika Anda tidak memberikan argumen maka default akan digunakan. Anda tidak perlu menghafal argumen setiap model. Anda selalu dapat menjalankan igel models di terminal Anda, yang akan membawa Anda ke mode interaktif, di mana Anda akan diminta memasukkan model yang ingin Anda gunakan dan jenis masalah yang ingin Anda selesaikan. Igel kemudian akan menampilkan informasi tentang model dan tautan yang dapat Anda ikuti untuk melihat daftar argumen yang tersedia dan cara menggunakannya.
Jalankan perintah ini di terminal untuk menyesuaikan/melatih model, tempat Anda menyediakan jalur ke kumpulan data dan jalur ke file yaml
$ igel fit --data_path ' path_to_your_csv_dataset.csv ' --yaml_path ' path_to_your_yaml_file.yaml '
# or shorter
$ igel fit -dp ' path_to_your_csv_dataset.csv ' -yml ' path_to_your_yaml_file.yaml '
"""
That's it. Your "trained" model can be now found in the model_results folder
(automatically created for you in your current working directory).
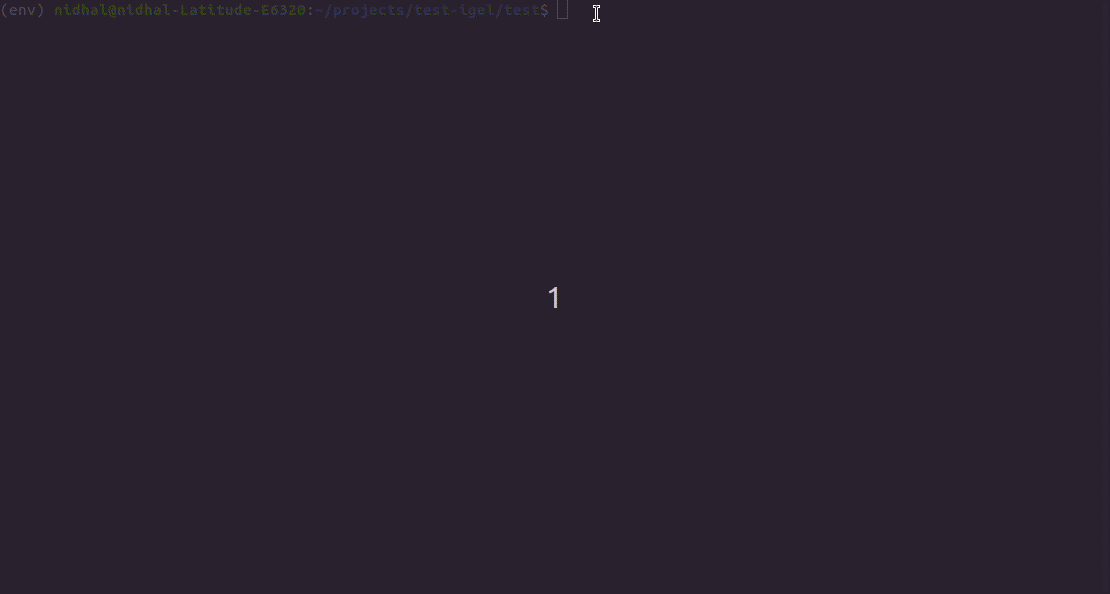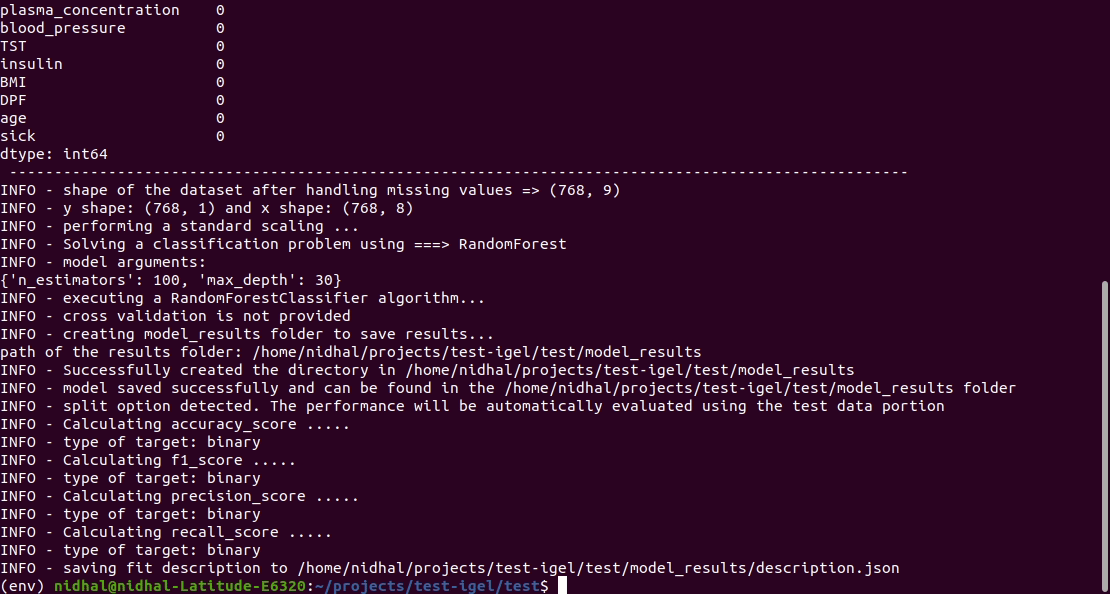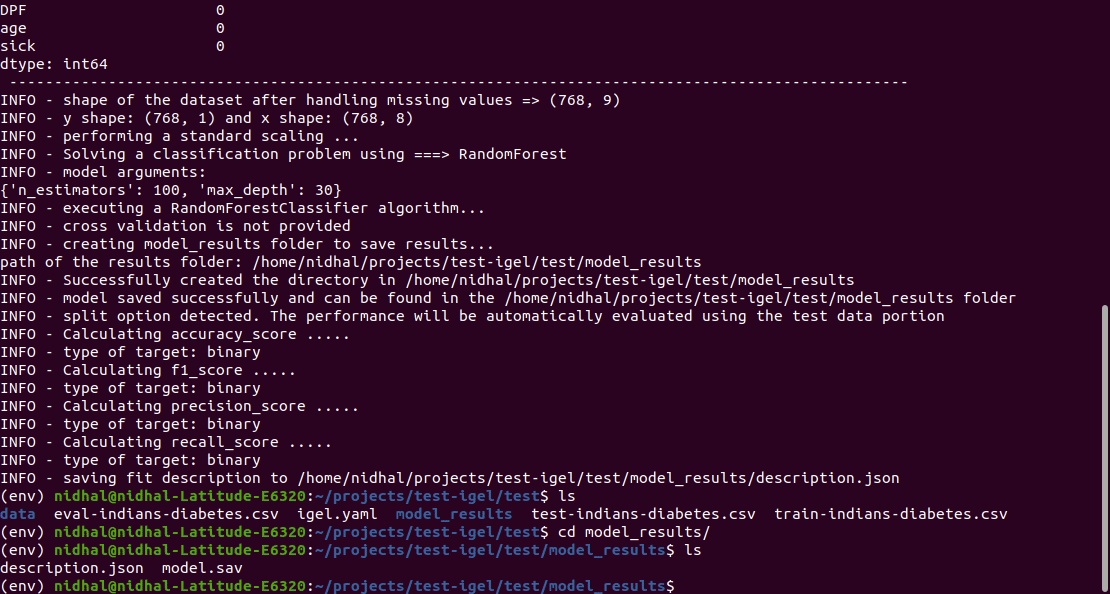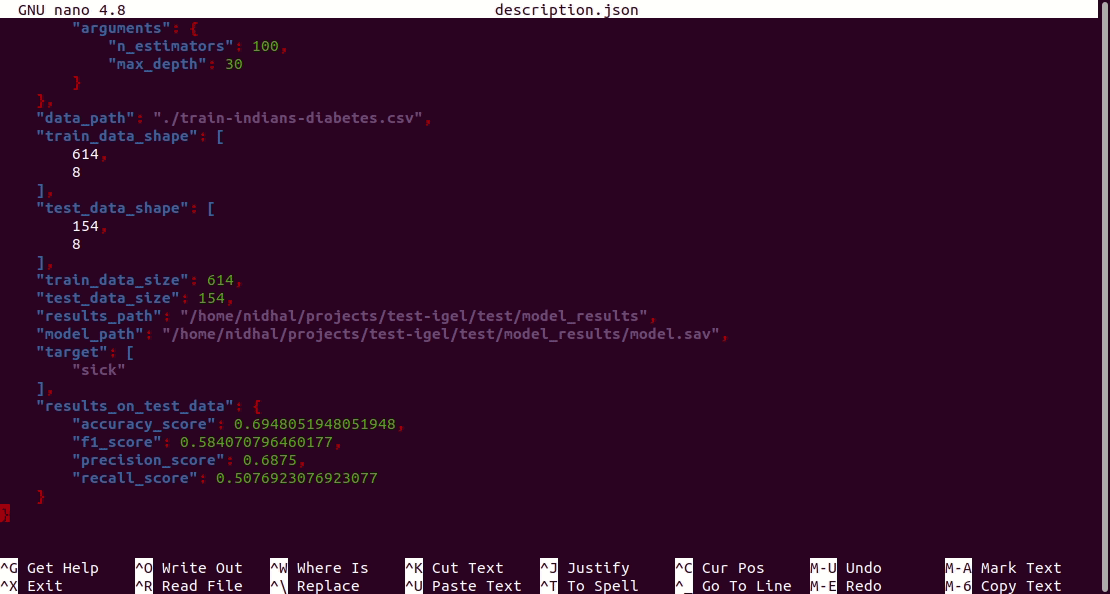
Furthermore, a description can be found in the description.json file inside the model_results folder.
"""
Anda kemudian dapat mengevaluasi model yang dilatih/dipasang sebelumnya:
$ igel evaluate -dp ' path_to_your_evaluation_dataset.csv '
"""
This will automatically generate an evaluation.json file in the current directory, where all evaluation results are stored
"""
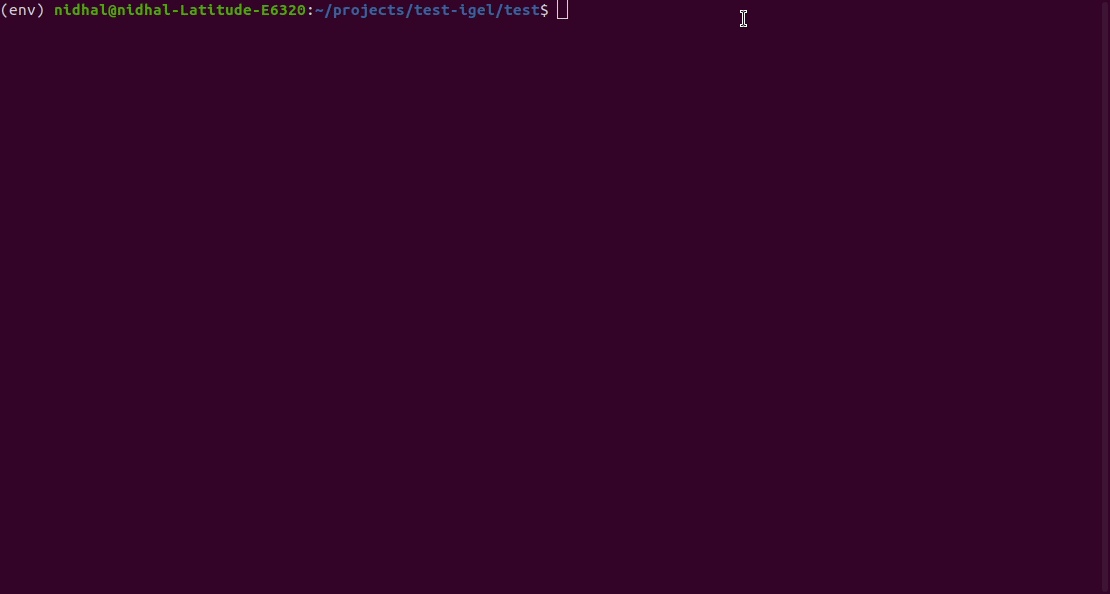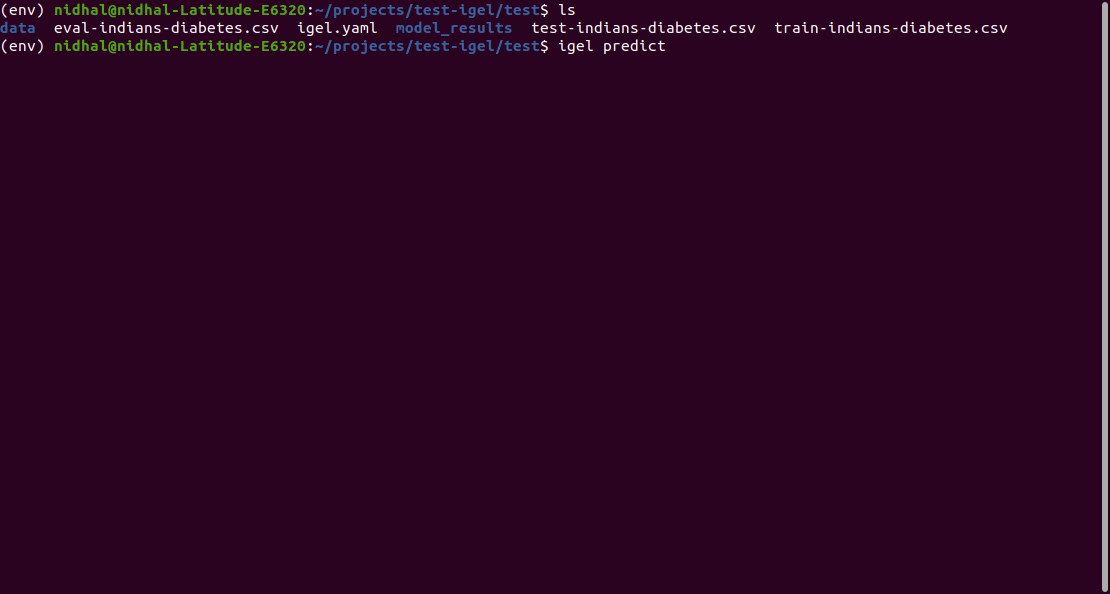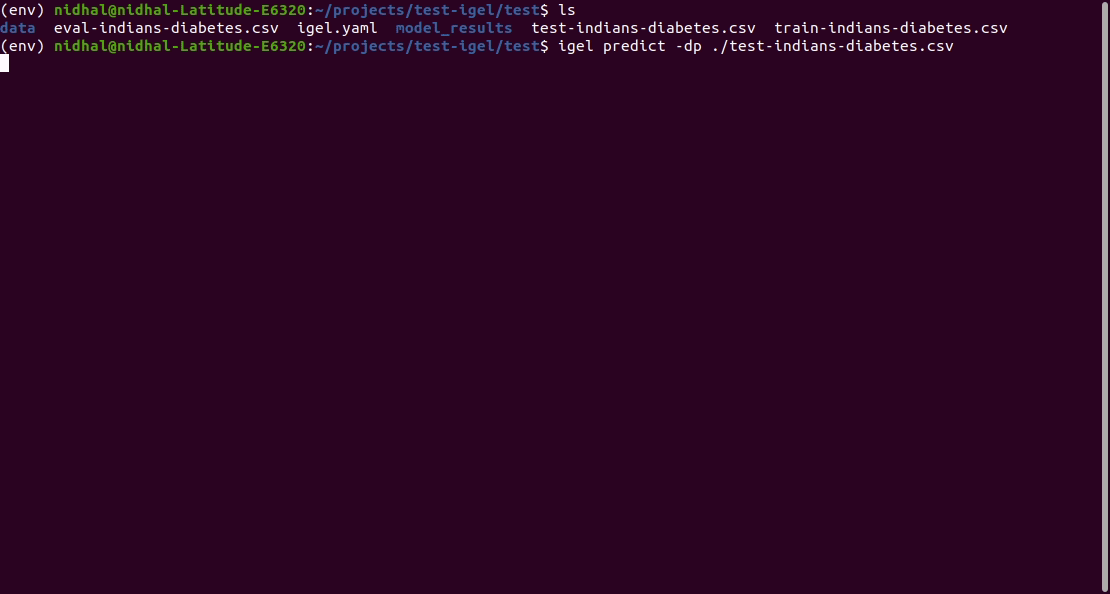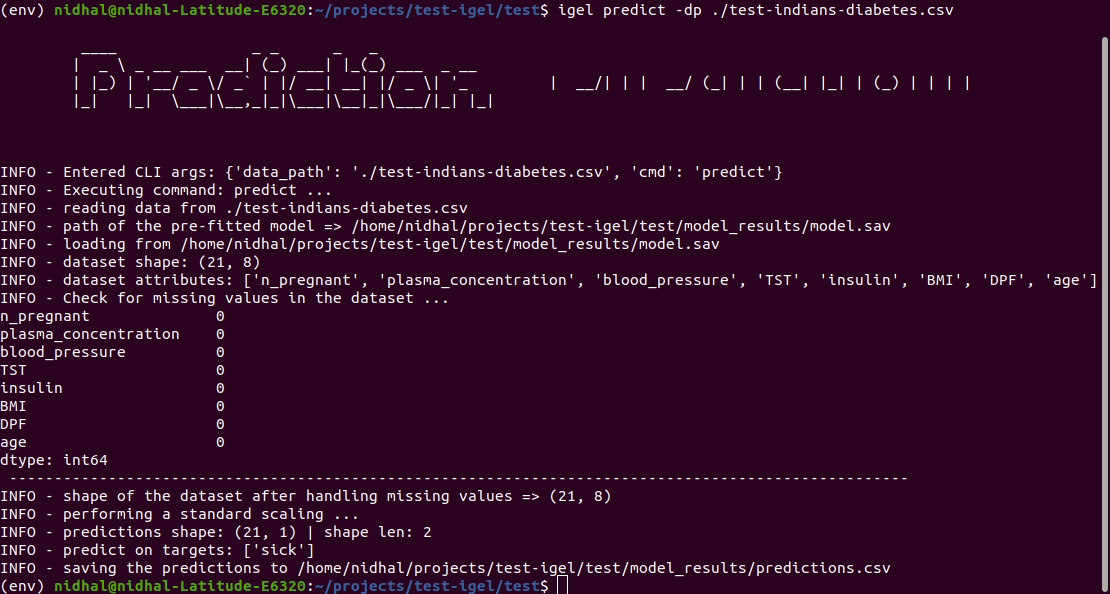
Terakhir, Anda dapat menggunakan model terlatih/yang telah dipasang sebelumnya untuk membuat prediksi jika Anda puas dengan hasil evaluasinya:
$ igel predict -dp ' path_to_your_test_dataset.csv '
"""
This will generate a predictions.csv file in your current directory, where all predictions are stored in a csv file
"""
Anda dapat menggabungkan fase melatih, mengevaluasi, dan memprediksi menggunakan satu perintah yang disebut eksperimen:
$ igel experiment -DP " path_to_train_data path_to_eval_data path_to_test_data " -yml " path_to_yaml_file "
"""
This will run fit using train_data, evaluate using eval_data and further generate predictions using the test_data
"""
Anda dapat mengekspor model sklearn terlatih/yang telah dipasang sebelumnya ke ONNX:
$ igel export -dp " path_to_pre-fitted_sklearn_model "
"""
This will convert the sklearn model into ONNX
""" from igel import Igel
Igel ( cmd = "fit" , data_path = "path_to_your_dataset" , yaml_path = "path_to_your_yaml_file" )
"""
check the examples folder for more
"""Langkah selanjutnya adalah menggunakan model Anda dalam produksi. Igel membantu Anda dalam tugas ini juga dengan memberikan perintah servis. Menjalankan perintah serve akan memberitahu igel untuk melayani model Anda. Tepatnya, igel akan secara otomatis membangun server REST dan menyajikan model Anda pada host dan port tertentu, yang dapat Anda konfigurasikan dengan meneruskannya sebagai opsi cli.
Cara termudah adalah dengan menjalankan:
$ igel serve --model_results_dir " path_to_model_results_directory "Perhatikan bahwa igel memerlukan opsi --model_results_dir atau segera -res_dir cli untuk memuat model dan memulai server. Secara default, igel akan melayani model Anda di localhost:8000 , namun, Anda dapat dengan mudah menggantinya dengan menyediakan opsi host dan port cli.
$ igel serve --model_results_dir " path_to_model_results_directory " --host " 127.0.0.1 " --port 8000Igel menggunakan FastAPI untuk membuat server REST, yang merupakan kerangka kerja modern berkinerja tinggi dan uvicorn untuk menjalankannya.
Contoh ini dilakukan menggunakan model terlatih (dibuat dengan menjalankan igel init --target klasifikasi tipe sakit) dan kumpulan data Diabetes India di bawah contoh/data. Header kolom dalam CSV asli adalah 'preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi' dan 'age'.
KERITING:
$ curl -X POST localhost:8080/predict --header " Content-Type:application/json " -d ' {"preg": 1, "plas": 180, "pres": 50, "skin": 12, "test": 1, "mass": 456, "pedi": 0.442, "age": 50} '
Outputs: {"prediction":[[0.0]]}$ curl -X POST localhost:8080/predict --header " Content-Type:application/json " -d ' {"preg": [1, 6, 10], "plas":[192, 52, 180], "pres": [40, 30, 50], "skin": [25, 35, 12], "test": [0, 1, 1], "mass": [456, 123, 155], "pedi": [0.442, 0.22, 0.19], "age": [50, 40, 29]} '
Outputs: {"prediction":[[1.0],[0.0],[0.0]]}Peringatan/Batasan:
Contoh penggunaan Klien Python:
from python_client import IgelClient
# the client allows additional args with defaults:
# scheme="http", endpoint="predict", missing_values="mean"
client = IgelClient ( host = 'localhost' , port = 8080 )
# you can post other types of files compatible with what Igel data reading allows
client . post ( "my_batch_file_for_predicting.csv" )
Outputs : < Response 200 > : { "prediction" :[[ 1.0 ],[ 0.0 ],[ 0.0 ]]}Tujuan utama igel adalah memberi Anda cara untuk melatih/menyesuaikan, mengevaluasi, dan menggunakan model tanpa menulis kode. Sebaliknya, yang Anda butuhkan hanyalah memberikan/menjelaskan apa yang ingin Anda lakukan dalam file yaml sederhana.
Pada dasarnya, Anda memberikan deskripsi atau konfigurasi dalam file yaml sebagai pasangan nilai kunci. Berikut ini ikhtisar semua konfigurasi yang didukung (untuk saat ini):
# dataset operations
dataset :
type : csv # [str] -> type of your dataset
read_data_options : # options you want to supply for reading your data (See the detailed overview about this in the next section)
sep : # [str] -> Delimiter to use.
delimiter : # [str] -> Alias for sep.
header : # [int, list of int] -> Row number(s) to use as the column names, and the start of the data.
names : # [list] -> List of column names to use
index_col : # [int, str, list of int, list of str, False] -> Column(s) to use as the row labels of the DataFrame,
usecols : # [list, callable] -> Return a subset of the columns
squeeze : # [bool] -> If the parsed data only contains one column then return a Series.
prefix : # [str] -> Prefix to add to column numbers when no header, e.g. ‘X’ for X0, X1, …
mangle_dupe_cols : # [bool] -> Duplicate columns will be specified as ‘X’, ‘X.1’, …’X.N’, rather than ‘X’…’X’. Passing in False will cause data to be overwritten if there are duplicate names in the columns.
dtype : # [Type name, dict maping column name to type] -> Data type for data or columns
engine : # [str] -> Parser engine to use. The C engine is faster while the python engine is currently more feature-complete.
converters : # [dict] -> Dict of functions for converting values in certain columns. Keys can either be integers or column labels.
true_values : # [list] -> Values to consider as True.
false_values : # [list] -> Values to consider as False.
skipinitialspace : # [bool] -> Skip spaces after delimiter.
skiprows : # [list-like] -> Line numbers to skip (0-indexed) or number of lines to skip (int) at the start of the file.
skipfooter : # [int] -> Number of lines at bottom of file to skip
nrows : # [int] -> Number of rows of file to read. Useful for reading pieces of large files.
na_values : # [scalar, str, list, dict] -> Additional strings to recognize as NA/NaN.
keep_default_na : # [bool] -> Whether or not to include the default NaN values when parsing the data.
na_filter : # [bool] -> Detect missing value markers (empty strings and the value of na_values). In data without any NAs, passing na_filter=False can improve the performance of reading a large file.
verbose : # [bool] -> Indicate number of NA values placed in non-numeric columns.
skip_blank_lines : # [bool] -> If True, skip over blank lines rather than interpreting as NaN values.
parse_dates : # [bool, list of int, list of str, list of lists, dict] -> try parsing the dates
infer_datetime_format : # [bool] -> If True and parse_dates is enabled, pandas will attempt to infer the format of the datetime strings in the columns, and if it can be inferred, switch to a faster method of parsing them.
keep_date_col : # [bool] -> If True and parse_dates specifies combining multiple columns then keep the original columns.
dayfirst : # [bool] -> DD/MM format dates, international and European format.
cache_dates : # [bool] -> If True, use a cache of unique, converted dates to apply the datetime conversion.
thousands : # [str] -> the thousands operator
decimal : # [str] -> Character to recognize as decimal point (e.g. use ‘,’ for European data).
lineterminator : # [str] -> Character to break file into lines.
escapechar : # [str] -> One-character string used to escape other characters.
comment : # [str] -> Indicates remainder of line should not be parsed. If found at the beginning of a line, the line will be ignored altogether. This parameter must be a single character.
encoding : # [str] -> Encoding to use for UTF when reading/writing (ex. ‘utf-8’).
dialect : # [str, csv.Dialect] -> If provided, this parameter will override values (default or not) for the following parameters: delimiter, doublequote, escapechar, skipinitialspace, quotechar, and quoting
delim_whitespace : # [bool] -> Specifies whether or not whitespace (e.g. ' ' or ' ') will be used as the sep
low_memory : # [bool] -> Internally process the file in chunks, resulting in lower memory use while parsing, but possibly mixed type inference.
memory_map : # [bool] -> If a filepath is provided for filepath_or_buffer, map the file object directly onto memory and access the data directly from there. Using this option can improve performance because there is no longer any I/O overhead.
random_numbers : # random numbers options in case you wanted to generate the same random numbers on each run
generate_reproducible : # [bool] -> set this to true to generate reproducible results
seed : # [int] -> the seed number is optional. A seed will be set up for you if you didn't provide any
split : # split options
test_size : 0.2 # [float] -> 0.2 means 20% for the test data, so 80% are automatically for training
shuffle : true # [bool] -> whether to shuffle the data before/while splitting
stratify : None # [list, None] -> If not None, data is split in a stratified fashion, using this as the class labels.
preprocess : # preprocessing options
missing_values : mean # [str] -> other possible values: [drop, median, most_frequent, constant] check the docs for more
encoding :
type : oneHotEncoding # [str] -> other possible values: [labelEncoding]
scale : # scaling options
method : standard # [str] -> standardization will scale values to have a 0 mean and 1 standard deviation | you can also try minmax
target : inputs # [str] -> scale inputs. | other possible values: [outputs, all] # if you choose all then all values in the dataset will be scaled
# model definition
model :
type : classification # [str] -> type of the problem you want to solve. | possible values: [regression, classification, clustering]
algorithm : NeuralNetwork # [str (notice the pascal case)] -> which algorithm you want to use. | type igel algorithms in the Terminal to know more
arguments : # model arguments: you can check the available arguments for each model by running igel help in your terminal
use_cv_estimator : false # [bool] -> if this is true, the CV class of the specific model will be used if it is supported
cross_validate :
cv : # [int] -> number of kfold (default 5)
n_jobs : # [signed int] -> The number of CPUs to use to do the computation (default None)
verbose : # [int] -> The verbosity level. (default 0)
hyperparameter_search :
method : grid_search # method you want to use: grid_search and random_search are supported
parameter_grid : # put your parameters grid here that you want to use, an example is provided below
param1 : [val1, val2]
param2 : [val1, val2]
arguments : # additional arguments you want to provide for the hyperparameter search
cv : 5 # number of folds
refit : true # whether to refit the model after the search
return_train_score : false # whether to return the train score
verbose : 0 # verbosity level
# target you want to predict
target : # list of strings: basically put here the column(s), you want to predict that exist in your csv dataset
- put the target you want to predict here
- you can assign many target if you are making a multioutput prediction Catatan
igel menggunakan panda di bawah tenda untuk membaca & mengurai data. Oleh karena itu, Anda juga dapat menemukan parameter opsional data ini di dokumentasi resmi pandas.
Ikhtisar mendetail tentang konfigurasi yang dapat Anda berikan dalam file yaml (atau json) diberikan di bawah ini. Perhatikan bahwa Anda tentu tidak memerlukan semua nilai konfigurasi untuk kumpulan data. Itu opsional. Umumnya, igel akan mengetahui cara membaca dataset Anda.
Namun, Anda dapat membantu dengan memberikan kolom tambahan menggunakan bagian read_data_options ini. Misalnya, salah satu nilai yang berguna menurut saya adalah "sep", yang menentukan bagaimana kolom Anda di kumpulan data csv dipisahkan. Umumnya, kumpulan data csv dipisahkan dengan koma, yang juga merupakan nilai default di sini. Namun, ini mungkin dipisahkan dengan titik koma dalam kasus Anda.
Oleh karena itu, Anda dapat menyediakan ini di read_data_options. Cukup tambahkan sep: ";" di bawah read_data_options.
| Parameter | Jenis | Penjelasan |
|---|---|---|
| September | str, bawaan ',' | Pembatas untuk digunakan. Jika sep adalah None, mesin C tidak dapat mendeteksi pemisah secara otomatis, namun mesin parsing Python bisa, artinya mesin parsing akan digunakan dan secara otomatis mendeteksi pemisah dengan alat sniffer bawaan Python, csv.Sniffer. Selain itu, pemisah yang lebih panjang dari 1 karakter dan berbeda dari 's+' akan ditafsirkan sebagai ekspresi reguler dan juga akan memaksa penggunaan mesin parsing Python. Perhatikan bahwa pembatas regex cenderung mengabaikan data yang dikutip. Contoh ekspresi reguler: 'rt'. |
| pembatas | bawaan Tidak ada | Alias untuk September. |
| tajuk | int, daftar int, default 'menyimpulkan' | Nomor baris yang akan digunakan sebagai nama kolom, dan awal data. Perilaku defaultnya adalah menyimpulkan nama kolom: jika tidak ada nama yang diteruskan, perilakunya identik dengan header=0 dan nama kolom disimpulkan dari baris pertama file, jika nama kolom diteruskan secara eksplisit maka perilakunya identik dengan header=None . Secara eksplisit meneruskan header=0 untuk dapat mengganti nama yang sudah ada. Header dapat berupa daftar bilangan bulat yang menentukan lokasi baris untuk multi-indeks pada kolom misalnya [0,1,3]. Baris intervensi yang tidak ditentukan akan dilewati (misalnya 2 dalam contoh ini dilewati). Perhatikan bahwa parameter ini mengabaikan baris komentar dan baris kosong jika skip_blank_lines=True, jadi header=0 menunjukkan baris pertama data, bukan baris pertama file. |
| nama | seperti array, opsional | Daftar nama kolom yang akan digunakan. Jika file berisi baris header, maka Anda harus meneruskan header=0 secara eksplisit untuk mengganti nama kolom. Duplikat dalam daftar ini tidak diperbolehkan. |
| indeks_kol | int, str, urutan int / str, atau False, default Tidak Ada | Kolom yang akan digunakan sebagai label baris DataFrame, baik diberikan sebagai nama string atau indeks kolom. Jika urutan int / str diberikan, MultiIndex digunakan. Catatan: index_col=False dapat digunakan untuk memaksa panda agar tidak menggunakan kolom pertama sebagai indeks, misalnya ketika Anda memiliki format file yang salah dengan pembatas di akhir setiap baris. |
| usecols | seperti daftar atau dapat dipanggil, opsional | Mengembalikan subset kolom. Jika seperti daftar, semua elemen harus berupa posisi (yaitu indeks bilangan bulat ke dalam kolom dokumen) atau string yang sesuai dengan nama kolom yang diberikan oleh pengguna dalam nama atau disimpulkan dari baris header dokumen. Misalnya, parameter usecols seperti daftar yang valid adalah [0, 1, 2] atau ['foo', 'bar', 'baz']. Urutan elemen diabaikan, jadi usecols=[0, 1] sama dengan [1, 0]. Untuk membuat instance DataFrame dari data dengan urutan elemen yang dipertahankan, gunakan pd.read_csv(data, usecols=['foo', 'bar'])[['foo', 'bar']] untuk kolom di ['foo', 'bar '] pesan atau pd.read_csv(data, usecols=['foo', 'bar'])[['bar', 'foo']] untuk ['bar', 'foo'] memesan. Jika dapat dipanggil, fungsi yang dapat dipanggil akan dievaluasi berdasarkan nama kolom, mengembalikan nama dengan fungsi yang dapat dipanggil bernilai True. Contoh argumen callable yang valid adalah lambda x: x.upper() di ['AAA', 'BBB', 'DDD']. Menggunakan parameter ini menghasilkan waktu penguraian yang lebih cepat dan penggunaan memori yang lebih rendah. |
| meremas | bodoh, defaultnya Salah | Jika data yang diuraikan hanya berisi satu kolom, maka kembalikan Seri. |
| awalan | str, opsional | Awalan untuk menambah nomor kolom bila tidak ada header, misal 'X' untuk X0, X1, … |
| mangle_dupe_cols | bodoh, defaultnya Benar | Kolom duplikat akan ditentukan sebagai 'X', 'X.1', …'X.N', bukan 'X'…'X'. Melewati False akan menyebabkan data tertimpa jika ada nama duplikat di kolom. |
| tipe | {'c', 'python'}, opsional | Mesin parser untuk digunakan. Mesin C lebih cepat sedangkan mesin python saat ini lebih lengkap fiturnya. |
| konverter | dikte, opsional | Dict fungsi untuk mengkonversi nilai pada kolom tertentu. Kunci dapat berupa bilangan bulat atau label kolom. |
| nilai_benar | daftar, opsional | Nilai yang dianggap Benar. |
| nilai_salah | daftar, opsional | Nilai yang dianggap Salah. |
| skipinitialspace | bodoh, defaultnya Salah | Lewati spasi setelah pembatas. |
| lompatan | seperti daftar, int atau dapat dipanggil, opsional | Nomor baris yang harus dilewati (diindeks 0) atau jumlah baris yang harus dilewati (int) di awal file. Jika dapat dipanggil, fungsi yang dapat dipanggil akan dievaluasi berdasarkan indeks baris, mengembalikan True jika baris harus dilewati dan False jika tidak. Contoh argumen callable yang valid adalah lambda x: x di [0, 2]. |
| skipfooter | ke dalam, bawaan 0 | Jumlah baris di bagian bawah file yang akan dilewati (Tidak didukung dengan engine='c'). |
| sekarang | ke dalam, opsional | Jumlah baris file yang akan dibaca. Berguna untuk membaca potongan file berukuran besar. |
| na_nilai | skalar, str, seperti daftar, atau dikt, opsional | String tambahan untuk dikenali sebagai NA/NaN. Jika dict lolos, nilai NA per kolom tertentu. Secara default, nilai berikut diinterpretasikan sebagai NaN: '', '#N/A', '#N/AN/A', '#NA', '-1.#IND', '-1.#QNAN', '-NaN', '-nan', '1.#IND', '1.#QNAN', '<NA>', 'N/A', 'NA', 'NULL', 'NaN', 'n /a', 'nan', 'batal'. |
| simpan_default_na | bodoh, defaultnya Benar | Apakah akan menyertakan nilai NaN default saat mengurai data atau tidak. Bergantung pada apakah na_values diteruskan, perilakunya adalah sebagai berikut: Jika keep_default_na adalah True, dan na_values ditentukan, na_values ditambahkan ke nilai NaN default yang digunakan untuk penguraian. Jika keep_default_na bernilai True, dan na_values tidak ditentukan, hanya nilai NaN default yang digunakan untuk penguraian. Jika keep_default_na adalah False, dan na_values ditentukan, hanya nilai NaN yang ditentukan na_values yang digunakan untuk penguraian. Jika keep_default_na adalah False, dan na_values tidak ditentukan, tidak ada string yang akan diurai sebagai NaN. Perhatikan bahwa jika na_filter diteruskan sebagai False, parameter keep_default_na dan na_values akan diabaikan. |
| na_filter | bodoh, defaultnya Benar | Deteksi penanda nilai yang hilang (string kosong dan nilai na_values). Pada data tanpa NA apa pun, meneruskan na_filter=False dapat meningkatkan performa membaca file besar. |
| bertele-tele | bodoh, defaultnya Salah | Tunjukkan jumlah nilai NA yang ditempatkan di kolom non-numerik. |
| lewati_blank_lines | bodoh, defaultnya Benar | Jika Benar, lewati baris kosong daripada menafsirkannya sebagai nilai NaN. |
| parse_tanggal | bool atau daftar int atau nama atau daftar daftar atau dict, default False | Perilakunya adalah sebagai berikut: boolean. Jika Benar -> coba parsing indeks. daftar int atau nama. misalnya Jika [1, 2, 3] -> coba parsing kolom 1, 2, 3 masing-masing sebagai kolom tanggal terpisah. daftar daftar. misalnya If [[1, 3]] -> gabungkan kolom 1 dan 3 dan parsing sebagai kolom tanggal tunggal. dict, misalnya {'foo' : [1, 3]} -> parsing kolom 1, 3 sebagai tanggal dan panggil hasil 'foo' Jika kolom atau indeks tidak dapat direpresentasikan sebagai array waktu tanggal, katakanlah karena nilai yang tidak dapat diurai atau campuran zona waktu, kolom atau indeks akan dikembalikan tanpa diubah sebagai tipe data objek. |
| menyimpulkan_format_tanggalwaktu | bodoh, defaultnya Salah | Jika True dan parse_dates diaktifkan, panda akan mencoba menyimpulkan format string datetime di kolom, dan jika dapat disimpulkan, beralihlah ke metode penguraian yang lebih cepat. Dalam beberapa kasus, hal ini dapat meningkatkan kecepatan penguraian sebesar 5-10x. |
| simpan_tanggal_kol | bodoh, defaultnya Salah | Jika True dan parse_dates menentukan penggabungan beberapa kolom, pertahankan kolom aslinya. |
| tanggal_parser | fungsi, opsional | Fungsi yang digunakan untuk mengonversi urutan kolom string menjadi array instance datetime. Defaultnya menggunakan dateutil.parser.parser untuk melakukan konversi. Panda akan mencoba memanggil date_parser dengan tiga cara berbeda, melanjutkan ke cara berikutnya jika terjadi pengecualian: 1) Meneruskan satu atau lebih array (seperti yang didefinisikan oleh parse_dates) sebagai argumen; 2) menggabungkan (berdasarkan baris) nilai string dari kolom yang ditentukan oleh parse_dates ke dalam satu array dan meneruskannya; dan 3) memanggil date_parser satu kali untuk setiap baris menggunakan satu atau lebih string (sesuai dengan kolom yang ditentukan oleh parse_dates) sebagai argumen. |
| hari pertama | bodoh, defaultnya Salah | Tanggal format DD/MM, format internasional dan Eropa. |
| tanggal_cache | bodoh, defaultnya Benar | Jika Benar, gunakan cache tanggal unik yang dikonversi untuk menerapkan konversi tanggal dan waktu. Dapat menghasilkan percepatan yang signifikan saat mengurai string tanggal duplikat, terutama string dengan offset zona waktu. |
| ribuan | str, opsional | Pemisah ribuan. |
| desimal | str, bawaan '.' | Karakter yang dikenali sebagai koma desimal (misal, gunakan ',' untuk data Eropa). |
| garisterminator | str (panjang 1), opsional | Karakter untuk memecah file menjadi beberapa baris. Hanya valid dengan parser C. |
| escapechar | str (panjang 1), opsional | String satu karakter digunakan untuk keluar dari karakter lain. |
| komentar | str, opsional | Menunjukkan sisa baris tidak boleh diuraikan. Jika ditemukan di awal baris, baris tersebut akan diabaikan sama sekali. |
| pengkodean | str, opsional | Pengkodean yang digunakan untuk UTF saat membaca/menulis (mis. 'utf-8'). |
| dialek | str atau csv.Dialect, opsional | Jika disediakan, parameter ini akan menggantikan nilai (default atau tidak) untuk parameter berikut: pembatas, tanda kutip ganda, escapechar, skipinitialspace, quotechar, dan kutipan |
| memori_rendah | bodoh, defaultnya Benar | Memproses file secara internal dalam beberapa bagian, sehingga mengurangi penggunaan memori saat penguraian, tetapi mungkin inferensi tipe campuran. Untuk memastikan tidak ada tipe campuran, setel False, atau tentukan tipe dengan parameter dtype. Perhatikan bahwa seluruh file dibaca ke dalam satu DataFrame, apa pun itu, |
| memori_peta | bodoh, defaultnya Salah | memetakan objek file langsung ke memori dan mengakses data langsung dari sana. Menggunakan opsi ini dapat meningkatkan kinerja karena tidak ada lagi overhead I/O. |
Solusi ujung ke ujung yang lengkap disediakan di bagian ini untuk membuktikan kemampuan igel . Seperti yang dijelaskan sebelumnya, Anda perlu membuat file konfigurasi yaml. Berikut adalah contoh end to end untuk memprediksi apakah seseorang menderita diabetes atau tidak menggunakan algoritma pohon keputusan . Kumpulan data dapat ditemukan di folder contoh.
model :
type : classification
algorithm : DecisionTree
target :
- sick $ igel fit -dp path_to_the_dataset -yml path_to_the_yaml_fileItu saja, igel sekarang akan menyesuaikan modelnya untuk Anda dan menyimpannya di folder model_results di direktori Anda saat ini.
Evaluasi model yang telah dipasang sebelumnya. Igel akan memuat model yang telah dipasang sebelumnya dari direktori model_results dan mengevaluasinya untuk Anda. Anda hanya perlu menjalankan perintah evaluasi dan memberikan jalur ke data evaluasi Anda.
$ igel evaluate -dp path_to_the_evaluation_datasetItu saja! Igel akan mengevaluasi model dan menyimpan statistik/hasil dalam file evaluasi.json di dalam folder model_results
Gunakan model yang telah dipasang sebelumnya untuk memprediksi data baru. Ini dilakukan secara otomatis oleh igel, Anda hanya perlu memberikan jalur ke data yang ingin Anda gunakan prediksinya.
$ igel predict -dp path_to_the_new_datasetItu saja! Igel akan menggunakan model yang telah dipasang sebelumnya untuk membuat prediksi dan menyimpannya dalam file prediksi.csv di dalam folder model_results
Anda juga dapat melakukan beberapa metode pra-pemrosesan atau operasi lain dengan menyediakannya di file yaml. Berikut ini contohnya, data dibagi menjadi 80% untuk pelatihan dan 20% untuk validasi/pengujian. Selain itu, data diacak saat dipecah.
Selanjutnya, data diproses terlebih dahulu dengan mengganti nilai yang hilang dengan mean (Anda juga dapat menggunakan median, mode, dll.). periksa tautan ini untuk informasi lebih lanjut
# dataset operations
dataset :
split :
test_size : 0.2
shuffle : True
stratify : default
preprocess : # preprocessing options
missing_values : mean # other possible values: [drop, median, most_frequent, constant] check the docs for more
encoding :
type : oneHotEncoding # other possible values: [labelEncoding]
scale : # scaling options
method : standard # standardization will scale values to have a 0 mean and 1 standard deviation | you can also try minmax
target : inputs # scale inputs. | other possible values: [outputs, all] # if you choose all then all values in the dataset will be scaled
# model definition
model :
type : classification
algorithm : RandomForest
arguments :
# notice that this is the available args for the random forest model. check different available args for all supported models by running igel help
n_estimators : 100
max_depth : 20
# target you want to predict
target :
- sickKemudian, Anda dapat menyesuaikan model dengan menjalankan perintah igel seperti yang ditunjukkan pada contoh lainnya
$ igel fit -dp path_to_the_dataset -yml path_to_the_yaml_fileUntuk evaluasi
$ igel evaluate -dp path_to_the_evaluation_datasetUntuk produksi
$ igel predict -dp path_to_the_new_dataset Dalam folder contoh di repositori, Anda akan menemukan folder data, tempat penyimpanan kumpulan data indian-diabetes, iris, dan linnerud (dari sklearn) yang terkenal. Selain itu, ada contoh ujung ke ujung di dalam setiap folder, di mana terdapat skrip dan file yaml yang akan membantu Anda memulai.
Folder indian-diabetes-example berisi dua contoh untuk membantu Anda memulai:
Folder iris-example berisi contoh regresi logistik , di mana beberapa pra-pemrosesan (satu pengkodean panas) dilakukan pada kolom target untuk menunjukkan lebih banyak kemampuan igel.
Selanjutnya, contoh multioutput berisi contoh regresi multioutput . Terakhir, cv-example berisi contoh penggunaan pengklasifikasi Ridge menggunakan validasi silang.
Anda juga dapat menemukan contoh validasi silang dan pencarian hyperparameter di folder.
Saya sarankan Anda bermain-main dengan contoh dan igel cli. Namun, Anda juga dapat langsung menjalankan fit.py, evaluasi.py, dan prediksi.py jika Anda mau.
Pertama, buat atau ubah dataset gambar yang dikategorikan ke dalam subfolder berdasarkan label/kelas gambar. Misalnya, jika Anda memiliki gambar anjing dan kucing, maka Anda memerlukan 2 subfolder:
Dengan asumsi dua sub-folder ini terdapat dalam satu folder induk bernama gambar, cukup masukkan data ke igel:
$ igel auto-train -dp ./images --task ImageClassificationIgel akan menangani semuanya mulai dari pra-pemrosesan data hingga pengoptimalan hyperparameter. Pada akhirnya, model terbaik akan disimpan di direktori kerja saat ini.
Pertama, buat atau ubah kumpulan data teks yang dikategorikan ke dalam subfolder berdasarkan label/kelas teks. Misalnya, jika Anda memiliki kumpulan data teks masukan positif dan negatif, maka Anda memerlukan 2 subfolder:
Dengan asumsi dua sub-folder ini terdapat dalam satu folder induk bernama teks, cukup masukkan data ke igel:
$ igel auto-train -dp ./texts --task TextClassificationIgel akan menangani semuanya mulai dari pra-pemrosesan data hingga pengoptimalan hyperparameter. Pada akhirnya, model terbaik akan disimpan di direktori kerja saat ini.
Anda juga dapat menjalankan igel UI jika Anda tidak terbiasa dengan terminalnya. Instal saja igel di mesin Anda seperti yang disebutkan di atas. Kemudian jalankan perintah tunggal ini di terminal Anda
$ igel guiIni akan membuka gui, yang sangat mudah digunakan. Periksa contoh tampilan gui dan cara menggunakannya di sini: https://github.com/nidhaloff/igel-ui
Anda dapat menarik gambar terlebih dahulu dari docker hub
$ docker pull nidhaloff/igelKemudian gunakan:
$ docker run -it --rm -v $( pwd ) :/data nidhaloff/igel fit -yml ' your_file.yaml ' -dp ' your_dataset.csv 'Anda dapat menjalankan igel di dalam docker dengan terlebih dahulu membuat image:
$ docker build -t igel .Lalu jalankan dan lampirkan direktori Anda saat ini (tidak harus berupa direktori igel) sebagai /data (workdir) di dalam container:
$ docker run -it --rm -v $( pwd ) :/data igel fit -yml ' your_file.yaml ' -dp ' your_dataset.csv ' Jika Anda menghadapi masalah apa pun, silakan membuka masalah. Selain itu, Anda dapat menghubungi penulis untuk informasi/pertanyaan lebih lanjut.
Apakah kamu suka igel? Anda selalu dapat membantu pengembangan proyek ini dengan:
Menurut Anda proyek ini berguna dan Anda ingin menghadirkan ide-ide baru, fitur-fitur baru, perbaikan bug, memperluas dokumen?
Kontribusi selalu diterima. Pastikan Anda membaca pedomannya terlebih dahulu
lisensi MIT
Hak Cipta (c) 2020-sekarang, Nidhal Baccouri


