rotary embedding torch
0.8.6
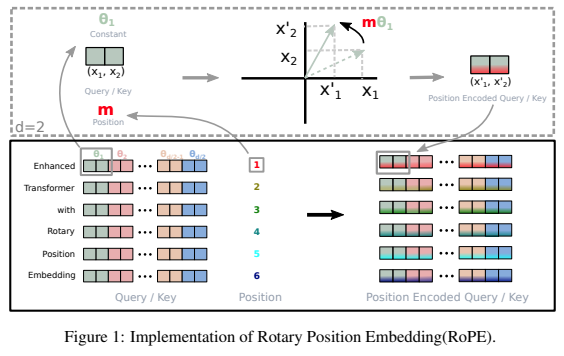
Pustaka mandiri untuk menambahkan penyematan putar ke transformator di Pytorch, mengikuti kesuksesannya sebagai pengkodean posisi relatif. Secara khusus, ini akan membuat informasi yang berputar ke sumbu tensor mana pun menjadi mudah dan efisien, baik dalam posisi tetap atau dipelajari. Perpustakaan ini akan memberi Anda hasil canggih untuk penyematan posisi, dengan sedikit biaya.
Perasaan saya juga memberi tahu saya bahwa ada sesuatu yang lebih dari rotasi yang dapat dieksploitasi dalam jaringan saraf tiruan.
$ pip install rotary-embedding-torch import torch
from rotary_embedding_torch import RotaryEmbedding
# instantiate the positional embedding in your transformer and pass to all your attention layers
rotary_emb = RotaryEmbedding ( dim = 32 )
# mock queries and keys - dimensions should end with (seq_len, feature dimension), and any number of preceding dimensions (batch, heads, etc)
q = torch . randn ( 1 , 8 , 1024 , 64 ) # queries - (batch, heads, seq len, dimension of head)
k = torch . randn ( 1 , 8 , 1024 , 64 ) # keys
# apply the rotations to your queries and keys after the heads have been split out, but prior to the dot product and subsequent softmax (attention)
q = rotary_emb . rotate_queries_or_keys ( q )
k = rotary_emb . rotate_queries_or_keys ( k )
# then do your attention with your queries (q) and keys (k) as usualJika Anda melakukan semua langkah di atas dengan benar, Anda akan melihat peningkatan yang dramatis selama pelatihan
Saat menangani cache kunci/nilai pada inferensi, posisi kueri perlu diimbangi dengan key_value_seq_length - query_seq_length
Untuk mempermudahnya, gunakan rotate_queries_with_cached_keys
q = torch . randn ( 1 , 8 , 1 , 64 ) # only one query at a time
k = torch . randn ( 1 , 8 , 1024 , 64 ) # key / values with cache concatted
q , k = rotary_emb . rotate_queries_with_cached_keys ( q , k )Anda juga dapat melakukannya secara manual seperti itu
q = rotary_emb . rotate_queries_or_keys ( q , offset = k . shape [ - 2 ] - q . shape [ - 2 ])Untuk memudahkan penggunaan penyematan posisi relatif aksial n-dimensi, mis. transformator video
import torch
from rotary_embedding_torch import (
RotaryEmbedding ,
apply_rotary_emb
)
pos_emb = RotaryEmbedding (
dim = 16 ,
freqs_for = 'pixel' ,
max_freq = 256
)
# queries and keys for frequencies to be rotated into
# say for a video with 8 frames, and rectangular image (feature dimension comes last)
q = torch . randn ( 1 , 8 , 64 , 32 , 64 )
k = torch . randn ( 1 , 8 , 64 , 32 , 64 )
# get axial frequencies - (8, 64, 32, 16 * 3 = 48)
# will automatically do partial rotary
freqs = pos_emb . get_axial_freqs ( 8 , 64 , 32 )
# rotate in frequencies
q = apply_rotary_emb ( freqs , q )
k = apply_rotary_emb ( freqs , k ) Dalam makalah ini, mereka mampu memperbaiki masalah ekstrapolasi panjang dengan penyematan putar dengan memberikan peluruhan yang mirip dengan ALiBi. Mereka menamai teknik ini XPos, dan Anda dapat menggunakannya dengan mengatur use_xpos = True pada inisialisasi.
Ini hanya dapat digunakan untuk transformator autoregresif
import torch
from rotary_embedding_torch import RotaryEmbedding
# instantiate the positional embedding in your transformer and pass to all your attention layers
rotary_emb = RotaryEmbedding (
dim = 32 ,
use_xpos = True # set this to True to make rotary embeddings extrapolate better to sequence lengths greater than the one used at training time
)
# mock queries and keys - dimensions should end with (seq_len, feature dimension), and any number of preceding dimensions (batch, heads, etc)
q = torch . randn ( 1 , 8 , 1024 , 64 ) # queries - (batch, heads, seq len, dimension of head)
k = torch . randn ( 1 , 8 , 1024 , 64 ) # keys
# apply the rotations to your queries and keys after the heads have been split out, but prior to the dot product and subsequent softmax (attention)
# instead of using `rotate_queries_or_keys`, you will use `rotate_queries_and_keys`, the rest is taken care of
q , k = rotary_emb . rotate_queries_and_keys ( q , k )Makalah MetaAI ini mengusulkan penyesuaian sederhana pada interpolasi posisi urutan untuk memperluas konteks yang lebih panjang untuk model yang telah dilatih sebelumnya. Mereka menunjukkan bahwa kinerjanya jauh lebih baik daripada sekadar menyempurnakan posisi urutan yang sama tetapi diperluas lebih jauh.
Anda dapat menggunakan ini dengan menyetel interpolate_factor pada inisialisasi ke nilai yang lebih besar dari 1. (mis. jika model yang telah dilatih sebelumnya dilatih pada tahun 2048, menyetel interpolate_factor = 2. akan memungkinkan penyesuaian ke 2048 x 2. = 4096 )
Pembaruan: seseorang di komunitas telah melaporkan bahwa ini tidak berfungsi dengan baik. silakan kirim email kepada saya jika Anda melihat hasil positif atau negatif
import torch
from rotary_embedding_torch import RotaryEmbedding
rotary_emb = RotaryEmbedding (
dim = 32 ,
interpolate_factor = 2. # add this line of code to pretrained model and fine-tune for ~1000 steps, as shown in paper
) @misc { su2021roformer ,
title = { RoFormer: Enhanced Transformer with Rotary Position Embedding } ,
author = { Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu } ,
year = { 2021 } ,
eprint = { 2104.09864 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CL }
} @inproceedings { Sun2022ALT ,
title = { A Length-Extrapolatable Transformer } ,
author = { Yutao Sun and Li Dong and Barun Patra and Shuming Ma and Shaohan Huang and Alon Benhaim and Vishrav Chaudhary and Xia Song and Furu Wei } ,
year = { 2022 }
} @inproceedings { Chen2023ExtendingCW ,
title = { Extending Context Window of Large Language Models via Positional Interpolation } ,
author = { Shouyuan Chen and Sherman Wong and Liangjian Chen and Yuandong Tian } ,
year = { 2023 }
} @misc { bloc97-2023
title = { NTK-Aware Scaled RoPE allows LLaMA models to have extended (8k+) context size without any fine-tuning and minimal perplexity degradation. } ,
author = { /u/bloc97 } ,
url = { https://www.reddit.com/r/LocalLLaMA/comments/14lz7j5/ntkaware_scaled_rope_allows_llama_models_to_have/ }
}

