audiolm pytorch
2.2.3
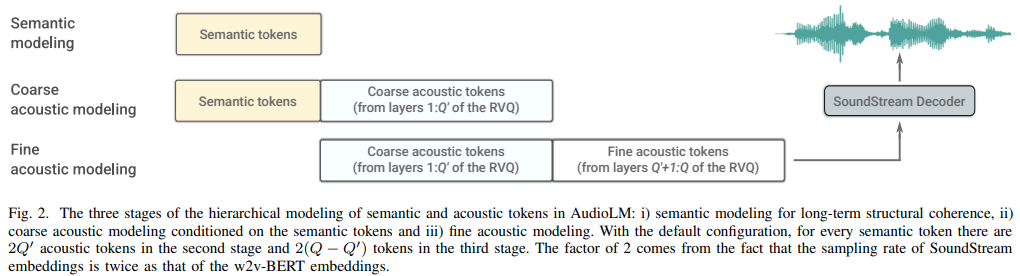
Implementasi AudioLM, Pendekatan Pemodelan Bahasa untuk Pembuatan Audio dari Google Research, di Pytorch
Ini juga memperluas pekerjaan pengkondisian dengan panduan bebas pengklasifikasi dengan T5. Hal ini memungkinkan seseorang untuk melakukan text-to-audio atau TTS, tidak ditawarkan di koran. Ya, ini berarti VALL-E dapat dilatih dari repositori ini. Ini pada dasarnya sama.
Silakan bergabung jika Anda tertarik untuk mereplikasi karya ini di tempat terbuka
Repositori ini sekarang juga berisi SoundStream versi berlisensi MIT. Ini juga kompatibel dengan EnCodec, yang juga berlisensi MIT pada saat penulisan.
Pembaruan: AudioLM pada dasarnya digunakan untuk 'menyelesaikan' pembuatan musik di MusicLM baru
Di masa depan, klip video ini tidak lagi masuk akal. Anda cukup meminta AI saja.
Stability.ai atas sponsor yang murah hati untuk bekerja dan membuka sumber penelitian kecerdasan buatan yang canggih
? Huggingface untuk perpustakaan akselerasi dan transformatornya yang luar biasa
MetaAI untuk Fairseq dan lisensi liberal
@eonglints dan Joseph karena telah menawarkan saran dan keahlian profesional mereka serta permintaan tarik!
@djqualia, @yigityu, @inspirit, dan @BlackFox1197 untuk membantu debugging soundstream
Allen dan LWprogramming untuk meninjau kode dan mengirimkan perbaikan bug!
Ilya karena menemukan masalah pada downsampling diskriminator multiskala dan untuk penyempurnaan pelatih aliran suara
Andrey karena mengidentifikasi kehilangan yang hilang dalam aliran suara dan membimbing saya melalui hyperparameter spektogram mel yang tepat
Alejandro dan Ilya karena berbagi hasil mereka dengan pelatihan soundstream, dan untuk mengatasi beberapa masalah dengan penyematan posisi perhatian lokal
Pemrograman LW untuk menambahkan kompatibilitas Encodec!
Pemrograman LW untuk menemukan masalah penanganan token EOS saat mengambil sampel dari FineTransformer !
@YoungloLee karena mengidentifikasi bug besar dalam konvolusi kausal 1 hari untuk aliran suara yang terkait dengan padding yang tidak memperhitungkan langkah!
Hayden yang menunjukkan beberapa perbedaan dalam diskriminator multi-skala untuk Soundstream
$ pip install audiolm-pytorchAda dua opsi untuk codec saraf. Jika Anda ingin menggunakan Encodec 24kHz yang telah dilatih sebelumnya, cukup buat objek Encodec sebagai berikut:
from audiolm_pytorch import EncodecWrapper
encodec = EncodecWrapper ()
# Now you can use the encodec variable in the same way you'd use the soundstream variables below. Jika tidak, agar lebih sesuai dengan makalah aslinya, Anda dapat menggunakan SoundStream . Pertama, SoundStream perlu dilatih pada kumpulan data audio yang besar
from audiolm_pytorch import SoundStream , SoundStreamTrainer
soundstream = SoundStream (
codebook_size = 4096 ,
rq_num_quantizers = 8 ,
rq_groups = 2 , # this paper proposes using multi-headed residual vector quantization - https://arxiv.org/abs/2305.02765
use_lookup_free_quantizer = True , # whether to use residual lookup free quantization - there are now reports of successful usage of this unpublished technique
use_finite_scalar_quantizer = False , # whether to use residual finite scalar quantization
attn_window_size = 128 , # local attention receptive field at bottleneck
attn_depth = 2 # 2 local attention transformer blocks - the soundstream folks were not experts with attention, so i took the liberty to add some. encodec went with lstms, but attention should be better
)
trainer = SoundStreamTrainer (
soundstream ,
folder = '/path/to/audio/files' ,
batch_size = 4 ,
grad_accum_every = 8 , # effective batch size of 32
data_max_length_seconds = 2 , # train on 2 second audio
num_train_steps = 1_000_000
). cuda ()
trainer . train ()
# after a lot of training, you can test the autoencoding as so
soundstream . eval () # your soundstream must be in eval mode, to avoid having the residual dropout of the residual VQ necessary for training
audio = torch . randn ( 10080 ). cuda ()
recons = soundstream ( audio , return_recons_only = True ) # (1, 10080) - 1 channel SoundStream Anda yang terlatih kemudian dapat digunakan sebagai tokenizer umum untuk audio
audio = torch . randn ( 1 , 512 * 320 )
codes = soundstream . tokenize ( audio )
# you can now train anything with the codebook ids
recon_audio_from_codes = soundstream . decode_from_codebook_indices ( codes )
# sanity check
assert torch . allclose (
recon_audio_from_codes ,
soundstream ( audio , return_recons_only = True )
) Anda juga dapat menggunakan aliran suara khusus untuk AudioLM dan MusicLM dengan mengimpor masing-masing AudioLMSoundStream dan MusicLMSoundStream
from audiolm_pytorch import AudioLMSoundStream , MusicLMSoundStream
soundstream = AudioLMSoundStream (...) # say you want the hyperparameters as in Audio LM paper
# rest is the same as above Pada versi 0.17.0 , Anda kini dapat memanggil metode kelas di SoundStream untuk memuat dari file pos pemeriksaan, tanpa harus mengingat konfigurasi Anda.
from audiolm_pytorch import SoundStream
soundstream = SoundStream . init_and_load_from ( './path/to/checkpoint.pt' ) Untuk menggunakan pelacakan Bobot & Bias, setel dulu use_wandb_tracking = True pada SoundStreamTrainer , lalu lakukan hal berikut
trainer = SoundStreamTrainer (
soundstream ,
...,
use_wandb_tracking = True
)
# wrap .train() with contextmanager, specifying project and run name
with trainer . wandb_tracker ( project = 'soundstream' , run = 'baseline' ):
trainer . train () Kemudian tiga transformator terpisah ( SemanticTransformer , CoarseTransformer , FineTransformer ) perlu dilatih
mantan. SemanticTransformer
import torch
from audiolm_pytorch import HubertWithKmeans , SemanticTransformer , SemanticTransformerTrainer
# hubert checkpoints can be downloaded at
# https://github.com/facebookresearch/fairseq/tree/main/examples/hubert
wav2vec = HubertWithKmeans (
checkpoint_path = './hubert/hubert_base_ls960.pt' ,
kmeans_path = './hubert/hubert_base_ls960_L9_km500.bin'
)
semantic_transformer = SemanticTransformer (
num_semantic_tokens = wav2vec . codebook_size ,
dim = 1024 ,
depth = 6 ,
flash_attn = True
). cuda ()
trainer = SemanticTransformerTrainer (
transformer = semantic_transformer ,
wav2vec = wav2vec ,
folder = '/path/to/audio/files' ,
batch_size = 1 ,
data_max_length = 320 * 32 ,
num_train_steps = 1
)
trainer . train () mantan. CoarseTransformer
import torch
from audiolm_pytorch import HubertWithKmeans , SoundStream , CoarseTransformer , CoarseTransformerTrainer
wav2vec = HubertWithKmeans (
checkpoint_path = './hubert/hubert_base_ls960.pt' ,
kmeans_path = './hubert/hubert_base_ls960_L9_km500.bin'
)
soundstream = SoundStream . init_and_load_from ( '/path/to/trained/soundstream.pt' )
coarse_transformer = CoarseTransformer (
num_semantic_tokens = wav2vec . codebook_size ,
codebook_size = 1024 ,
num_coarse_quantizers = 3 ,
dim = 512 ,
depth = 6 ,
flash_attn = True
)
trainer = CoarseTransformerTrainer (
transformer = coarse_transformer ,
codec = soundstream ,
wav2vec = wav2vec ,
folder = '/path/to/audio/files' ,
batch_size = 1 ,
data_max_length = 320 * 32 ,
num_train_steps = 1_000_000
)
trainer . train () mantan. FineTransformer
import torch
from audiolm_pytorch import SoundStream , FineTransformer , FineTransformerTrainer
soundstream = SoundStream . init_and_load_from ( '/path/to/trained/soundstream.pt' )
fine_transformer = FineTransformer (
num_coarse_quantizers = 3 ,
num_fine_quantizers = 5 ,
codebook_size = 1024 ,
dim = 512 ,
depth = 6 ,
flash_attn = True
)
trainer = FineTransformerTrainer (
transformer = fine_transformer ,
codec = soundstream ,
folder = '/path/to/audio/files' ,
batch_size = 1 ,
data_max_length = 320 * 32 ,
num_train_steps = 1_000_000
)
trainer . train ()Semua bersama-sama sekarang
from audiolm_pytorch import AudioLM
audiolm = AudioLM (
wav2vec = wav2vec ,
codec = soundstream ,
semantic_transformer = semantic_transformer ,
coarse_transformer = coarse_transformer ,
fine_transformer = fine_transformer
)
generated_wav = audiolm ( batch_size = 1 )
# or with priming
generated_wav_with_prime = audiolm ( prime_wave = torch . randn ( 1 , 320 * 8 ))
# or with text condition, if given
generated_wav_with_text_condition = audiolm ( text = [ 'chirping of birds and the distant echos of bells' ])Pembaruan: Sepertinya ini akan berhasil, mengingat 'VALL-E'
mantan. Transformator Semantik
import torch
from audiolm_pytorch import HubertWithKmeans , SemanticTransformer , SemanticTransformerTrainer
wav2vec = HubertWithKmeans (
checkpoint_path = './hubert/hubert_base_ls960.pt' ,
kmeans_path = './hubert/hubert_base_ls960_L9_km500.bin'
)
semantic_transformer = SemanticTransformer (
num_semantic_tokens = 500 ,
dim = 1024 ,
depth = 6 ,
has_condition = True , # this will have to be set to True
cond_as_self_attn_prefix = True # whether to condition as prefix to self attention, instead of cross attention, as was done in 'VALL-E' paper
). cuda ()
# mock text audio dataset (as an example)
# you will have to extend your own from `Dataset`, and return an audio tensor as well as a string (the audio description) in any order (the framework will autodetect and route it into the transformer)
from torch . utils . data import Dataset
class MockTextAudioDataset ( Dataset ):
def __init__ ( self , length = 100 , audio_length = 320 * 32 ):
super (). __init__ ()
self . audio_length = audio_length
self . len = length
def __len__ ( self ):
return self . len
def __getitem__ ( self , idx ):
mock_audio = torch . randn ( self . audio_length )
mock_caption = 'audio caption'
return mock_caption , mock_audio
dataset = MockTextAudioDataset ()
# instantiate semantic transformer trainer and train
trainer = SemanticTransformerTrainer (
transformer = semantic_transformer ,
wav2vec = wav2vec ,
dataset = dataset ,
batch_size = 4 ,
grad_accum_every = 8 ,
data_max_length = 320 * 32 ,
num_train_steps = 1_000_000
)
trainer . train ()
# after much training above
sample = trainer . generate ( text = [ 'sound of rain drops on the rooftops' ], batch_size = 1 , max_length = 2 ) # (1, < 128) - may terminate early if it detects [eos] Karena semua kelas pelatih menggunakan ? Accelerator, Anda dapat dengan mudah melakukan pelatihan multi gpu dengan menggunakan perintah accelerate juga
Di root proyek
$ accelerate configKemudian, di direktori yang sama
$ accelerate launch train . py menyelesaikan CoarseTransformer
gunakan fairseq vq-wav2vec untuk penyematan
tambahkan pengkondisian
tambahkan panduan gratis pengklasifikasi
tambahkan unik berturut-turut untuk
menggabungkan kemampuan untuk menggunakan fitur perantara hubert sebagai token semantik, yang direkomendasikan oleh eonglints
mengakomodasi audio berdurasi variabel, bawa token eos
pastikan pekerjaan berturut-turut yang unik dengan trafo kasar
cukup mencetak semua kerugian diskriminator untuk dicatat
ditangani saat membuat token semantik, bahwa logit terakhir belum tentu menjadi yang terakhir dalam urutan karena pemrosesan berurutan yang unik
kode pengambilan sampel lengkap untuk Transformator Kasar dan Halus, yang akan rumit
pastikan inferensi penuh dengan atau tanpa perintah berfungsi di kelas AudioLM
menyelesaikan kode pelatihan lengkap untuk soundstream, mengurus pelatihan diskriminator
tambahkan penalti gradien yang efisien untuk diskriminator untuk aliran suara
sambungkan sampel hz dari kumpulan data suara -> transformator, dan lakukan pengambilan sampel ulang yang tepat selama pelatihan - pikirkan apakah akan mengizinkan kumpulan data memiliki file suara yang bervariasi atau menerapkan sampel hz yang sama
kode pelatihan trafo lengkap untuk ketiga trafo
refactor sehingga transformator semantik memiliki pembungkus yang menangani konsekutif unik serta wav ke hubert atau vq-wav2vec
hanya tidak memperhatikan token eos di sisi prompt (semantik untuk trafo kasar, kasar untuk trafo halus)
menambahkan dropout terstruktur dari penyamaran kausal yang pelupa, jauh lebih baik daripada dropout tradisional
mencari cara untuk menekan logging di fairseq
menegaskan bahwa ketiga transformator yang diteruskan ke audiolm kompatibel
memungkinkan penyematan posisi relatif khusus pada transformator halus berdasarkan pada posisi pencocokan mutlak kuantizer antara kasar dan halus
izinkan sisa vq yang dikelompokkan dalam soundstream (gunakan GroupedResidualVQ dari vector-quantize-pytorch lib), dari hifi-codec
tambahkan perhatian kilat dengan NoPE
menerima gelombang utama di AudioLM sebagai jalur ke file audio, dan mengambil sampel ulang otomatis untuk semantik vs akustik
tambahkan cache kunci/nilai ke semua transformator, mempercepat inferensi
merancang trafo kasar dan halus secara hierarkis
selidiki decoding spesifikasi, uji pertama di x-transformer, lalu porting jika ada
ulangi penyematan posisi di hadapan grup di sisa vq
tes dengan sintesis ucapan sebagai permulaan
alat cli, sesuatu seperti audiolm generate <wav.file | text> dan simpan file wav yang dihasilkan ke direktori lokal
mengembalikan daftar gelombang dalam hal audio berdurasi variabel
hanya menangani kasus tepi dalam pelatihan pengkondisian teks transformator kasar, di mana gelombang mentah diambil sampelnya ulang pada frekuensi yang berbeda. menentukan secara otomatis cara merutekan berdasarkan panjangnya
@inproceedings { Borsos2022AudioLMAL ,
title = { AudioLM: a Language Modeling Approach to Audio Generation } ,
author = { Zal{'a}n Borsos and Rapha{"e}l Marinier and Damien Vincent and Eugene Kharitonov and Olivier Pietquin and Matthew Sharifi and Olivier Teboul and David Grangier and Marco Tagliasacchi and Neil Zeghidour } ,
year = { 2022 }
} @misc { https://doi.org/10.48550/arxiv.2107.03312 ,
title = { SoundStream: An End-to-End Neural Audio Codec } ,
author = { Zeghidour, Neil and Luebs, Alejandro and Omran, Ahmed and Skoglund, Jan and Tagliasacchi, Marco } ,
publisher = { arXiv } ,
url = { https://arxiv.org/abs/2107.03312 } ,
year = { 2021 }
} @misc { shazeer2020glu ,
title = { GLU Variants Improve Transformer } ,
author = { Noam Shazeer } ,
year = { 2020 } ,
url = { https://arxiv.org/abs/2002.05202 }
} @article { Shazeer2019FastTD ,
title = { Fast Transformer Decoding: One Write-Head is All You Need } ,
author = { Noam M. Shazeer } ,
journal = { ArXiv } ,
year = { 2019 } ,
volume = { abs/1911.02150 }
} @article { Ho2022ClassifierFreeDG ,
title = { Classifier-Free Diffusion Guidance } ,
author = { Jonathan Ho } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2207.12598 }
} @misc { crowson2022 ,
author = { Katherine Crowson } ,
url = { https://twitter.com/rivershavewings }
} @misc { ding2021cogview ,
title = { CogView: Mastering Text-to-Image Generation via Transformers } ,
author = { Ming Ding and Zhuoyi Yang and Wenyi Hong and Wendi Zheng and Chang Zhou and Da Yin and Junyang Lin and Xu Zou and Zhou Shao and Hongxia Yang and Jie Tang } ,
year = { 2021 } ,
eprint = { 2105.13290 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @article { Liu2022FCMFC ,
title = { FCM: Forgetful Causal Masking Makes Causal Language Models Better Zero-Shot Learners } ,
author = { Hao Liu and Xinyang Geng and Lisa Lee and Igor Mordatch and Sergey Levine and Sharan Narang and P. Abbeel } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2210.13432 }
} @inproceedings { anonymous2022normformer ,
title = { NormFormer: Improved Transformer Pretraining with Extra Normalization } ,
author = { Anonymous } ,
booktitle = { Submitted to The Tenth International Conference on Learning Representations } ,
year = { 2022 } ,
url = { https://openreview.net/forum?id=GMYWzWztDx5 } ,
note = { under review }
} @misc { liu2021swin ,
title = { Swin Transformer V2: Scaling Up Capacity and Resolution } ,
author = { Ze Liu and Han Hu and Yutong Lin and Zhuliang Yao and Zhenda Xie and Yixuan Wei and Jia Ning and Yue Cao and Zheng Zhang and Li Dong and Furu Wei and Baining Guo } ,
year = { 2021 } ,
eprint = { 2111.09883 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @article { Li2021LocalViTBL ,
title = { LocalViT: Bringing Locality to Vision Transformers } ,
author = { Yawei Li and K. Zhang and Jie Cao and Radu Timofte and Luc Van Gool } ,
journal = { ArXiv } ,
year = { 2021 } ,
volume = { abs/2104.05707 }
} @article { Defossez2022HighFN ,
title = { High Fidelity Neural Audio Compression } ,
author = { Alexandre D'efossez and Jade Copet and Gabriel Synnaeve and Yossi Adi } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2210.13438 }
} @article { Hu2017SqueezeandExcitationN ,
title = { Squeeze-and-Excitation Networks } ,
author = { Jie Hu and Li Shen and Gang Sun } ,
journal = { 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition } ,
year = { 2017 } ,
pages = { 7132-7141 }
} @inproceedings { Yang2023HiFiCodecGV ,
title = { HiFi-Codec: Group-residual Vector quantization for High Fidelity Audio Codec } ,
author = { Dongchao Yang and Songxiang Liu and Rongjie Huang and Jinchuan Tian and Chao Weng and Yuexian Zou } ,
year = { 2023 }
} @article { Kazemnejad2023TheIO ,
title = { The Impact of Positional Encoding on Length Generalization in Transformers } ,
author = { Amirhossein Kazemnejad and Inkit Padhi and Karthikeyan Natesan Ramamurthy and Payel Das and Siva Reddy } ,
journal = { ArXiv } ,
year = { 2023 } ,
volume = { abs/2305.19466 }
} @inproceedings { dao2022flashattention ,
title = { Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness } ,
author = { Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher } ,
booktitle = { Advances in Neural Information Processing Systems } ,
year = { 2022 }
} @misc { yu2023language ,
title = { Language Model Beats Diffusion -- Tokenizer is Key to Visual Generation } ,
author = { Lijun Yu and José Lezama and Nitesh B. Gundavarapu and Luca Versari and Kihyuk Sohn and David Minnen and Yong Cheng and Agrim Gupta and Xiuye Gu and Alexander G. Hauptmann and Boqing Gong and Ming-Hsuan Yang and Irfan Essa and David A. Ross and Lu Jiang } ,
year = { 2023 } ,
eprint = { 2310.05737 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @inproceedings { Katsch2023GateLoopFD ,
title = { GateLoop: Fully Data-Controlled Linear Recurrence for Sequence Modeling } ,
author = { Tobias Katsch } ,
year = { 2023 } ,
url = { https://api.semanticscholar.org/CorpusID:265018962 }
} @article { Fifty2024Restructuring ,
title = { Restructuring Vector Quantization with the Rotation Trick } ,
author = { Christopher Fifty, Ronald G. Junkins, Dennis Duan, Aniketh Iyengar, Jerry W. Liu, Ehsan Amid, Sebastian Thrun, Christopher Ré } ,
journal = { ArXiv } ,
year = { 2024 } ,
volume = { abs/2410.06424 } ,
url = { https://api.semanticscholar.org/CorpusID:273229218 }
} @inproceedings { Zhou2024ValueRL ,
title = { Value Residual Learning For Alleviating Attention Concentration In Transformers } ,
author = { Zhanchao Zhou and Tianyi Wu and Zhiyun Jiang and Zhenzhong Lan } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:273532030 }
}

