lion pytorch
0.2.3
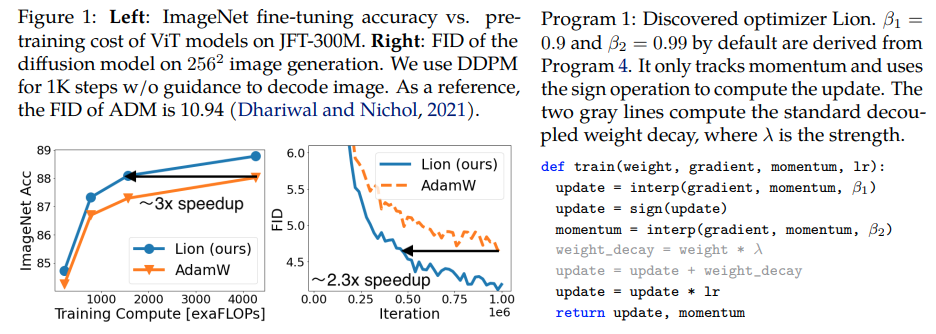
Lion, Evo L ved S i gn M o me n tum, pengoptimal baru yang ditemukan oleh Google Brain yang konon lebih baik daripada Adam(w), di Pytorch. Ini hampir merupakan salinan langsung dari sini, dengan sedikit modifikasi kecil.
Ini sangat sederhana, sebaiknya kita dapat mengaksesnya dan menggunakannya secepatnya oleh semua orang untuk melatih beberapa model hebat, apakah itu benar-benar berhasil?
Kecepatan pembelajaran dan peluruhan bobot: penulis menulis di Bagian 5 - Based on our experience, a suitable learning rate for Lion is typically 3-10x smaller than that for AdamW. Since the effective weight decay is lr * λ, the value of decoupled weight decay λ used for Lion is 3-10x larger than that for AdamW in order to maintain a similar strength. Nilai awal, nilai puncak, dan nilai akhir pada jadwal learning rate harus diubah secara bersamaan dengan rasio yang sama dibandingkan AdamW, dibuktikan oleh peneliti.
Jadwal kecepatan pembelajaran: penulis menggunakan jadwal kecepatan pembelajaran yang sama untuk Lion seperti AdamW di makalah. Namun demikian, mereka mengamati keuntungan yang lebih besar ketika menggunakan jadwal peluruhan kosinus untuk melatih ViT, dibandingkan dengan jadwal akar kuadrat timbal balik.
β1 dan β2: penulis menulis di Bagian 5 - The default values for β1 and β2 in AdamW are set as 0.9 and 0.999, respectively, with an ε of 1e−8, while in Lion, the default values for β1 and β2 are discovered through the program search process and set as 0.9 and 0.99, respectively. Mirip dengan cara orang mengurangi β2 menjadi 0,99 atau lebih kecil dan meningkatkan ε menjadi 1e-6 di AdamW untuk meningkatkan stabilitas, menggunakan β1=0.95, β2=0.98 di Lion juga dapat membantu dalam mengurangi ketidakstabilan selama pelatihan, seperti yang disarankan oleh penulis. Hal ini dikuatkan oleh seorang peneliti.
Pembaruan: sepertinya berfungsi untuk pemodelan bahasa autoregresif enwik8 lokal saya.
Pembaruan 2: eksperimen, nampaknya jauh lebih buruk daripada Adam jika kecepatan pembelajaran tetap konstan.
Pembaruan 3: Membagi kecepatan pembelajaran dengan 3, melihat hasil awal yang lebih baik daripada Adam. Mungkin Adam telah dicopot dari jabatannya, setelah hampir satu dekade.
Pembaruan 4: menggunakan aturan praktis kecepatan pemelajaran 10x lebih kecil dari makalah menghasilkan hasil terburuk. Jadi menurut saya masih perlu sedikit penyetelan.
Rangkuman dari pembaruan sebelumnya: seperti yang ditunjukkan dalam eksperimen, Lion dengan kecepatan pemelajaran 3x lebih kecil mengalahkan Adam. Masih diperlukan sedikit penyesuaian karena kecepatan pembelajaran 10x lebih kecil akan memberikan hasil yang lebih buruk.
Pembaruan 5: sejauh ini mendengar semua hasil positif untuk pemodelan bahasa, jika dilakukan dengan benar. Juga terdengar hasil positif untuk pelatihan teks-ke-gambar yang signifikan, meskipun memerlukan sedikit penyesuaian. Hasil negatif tampaknya terjadi pada masalah dan arsitektur di luar apa yang dievaluasi dalam makalah ini - RL, jaringan feedforward, arsitektur hybrid aneh dengan LSTM + konvolusi, dll. Anekdata negatif juga menegaskan bahwa teknik ini sensitif terhadap ukuran batch, jumlah data/augmentasi . Ketahui jadwal kecepatan pemelajaran optimalnya, dan apakah cooldown memengaruhi hasil. Menariknya juga terdapat hasil positif pada klip terbuka, yang menjadi negatif seiring dengan peningkatan ukuran model (tetapi mungkin dapat diselesaikan).
Pembaruan 6: masalah klip terbuka diselesaikan oleh penulis, dengan mengatur suhu awal yang lebih tinggi.
Pembaruan 7: hanya akan merekomendasikan pengoptimal ini dalam pengaturan ukuran batch tinggi (64 atau lebih tinggi)
$ pip instal singa-pytorch
Alternatifnya, menggunakan conda:
$ conda instal singa-pytorch
# model mainanimport torchfrom torch import nnmodel = nn.Linear(10, 1)# import Lion dan instantiate dengan parameter dari lion_pytorch import Lionopt = Lion(model.parameters(), lr=1e-4, Weight_decay=1e-2)# maju dan backwardsloss = model(torch.randn(10))loss.backward()# pengoptimal stepopt.step()opt.zero_grad()
Untuk menggunakan kernel yang menyatu untuk memperbarui parameter, pertama pip install triton -U --pre , lalu
opt = Lion(model.parameters(),lr=1e-4,weight_decay=1e-2,use_triton=True # setel ini ke True untuk menggunakan kernel cuda dengan Triton lang (Tillet dkk))
Stability.ai atas sponsor yang murah hati untuk bekerja dan membuka sumber penelitian kecerdasan buatan yang canggih
@misc{https://doi.org/10.48550/arxiv.2302.06675,url = {https://arxiv.org/abs/2302.06675},author = {Chen, Xiangning dan Liang, Chen dan Huang, Da dan Real, Esteban dan Wang, Kaiyuan dan Liu, Yao dan Pham, Hieu dan Dong, Xuanyi dan Luong, Thang dan Hsieh, Cho-Jui dan Lu, Yifeng dan Le, Quoc V.},title = {Penemuan Simbolik Algoritma Optimasi},publisher = {arXiv},year = {2023}} @article{Tillet2019TritonAI,title = {Triton: bahasa perantara dan kompiler untuk komputasi jaringan neural bersusun},author = {Philippe Tillet dan H. Kung dan D. Cox},journal = {Prosiding Lokakarya Internasional ACM SIGPLAN ke-3 tentang Mesin Pembelajaran dan Bahasa Pemrograman},tahun = {2019}} @misc{Schaipp2024,penulis = {Fabian Schaipp},url = {https://fabian-sp.github.io/posts/2024/02/decoupling/}} @inproceedings{Liang2024CautiousOI,title = {Pengoptimal yang Berhati-hati: Meningkatkan Pelatihan dengan Satu Baris Kode},author = {Kaizhao Liang dan Lizhang Chen dan Bo Liu dan Qiang Liu},year = {2024},url = {https://api .semanticscholar.org/CorpusID:274234738}} 

