se3 transformer pytorch
0.9.0
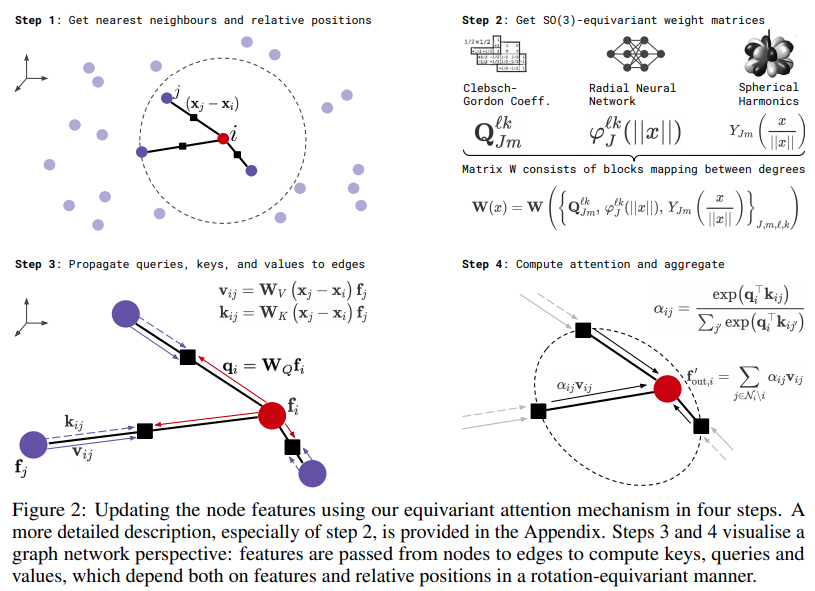
Implementasi SE3-Transformer untuk Perhatian Diri Setara, di Pytorch. Mungkin diperlukan untuk mereplikasi hasil Alphafold2 dan aplikasi penemuan obat lainnya.
Contoh kesetaraan
Jika Anda telah menggunakan SE3 Transformers versi apa pun sebelum versi 0.6.0, harap perbarui. Bug besar telah ditemukan oleh @MattMcPartlon, jika Anda tidak menggunakan pengaturan tetangga yang jarang dan mengandalkan fungsionalitas tetangga terdekat
Pembaruan: Disarankan agar Anda menggunakan Equiformer sebagai gantinya
$ pip install se3-transformer-pytorch import torch
from se3_transformer_pytorch import SE3Transformer
model = SE3Transformer (
dim = 512 ,
heads = 8 ,
depth = 6 ,
dim_head = 64 ,
num_degrees = 4 ,
valid_radius = 10
)
feats = torch . randn ( 1 , 1024 , 512 )
coors = torch . randn ( 1 , 1024 , 3 )
mask = torch . ones ( 1 , 1024 ). bool ()
out = model ( feats , coors , mask ) # (1, 1024, 512)Contoh penggunaan potensial di Alphafold2, seperti diuraikan di sini
import torch
from se3_transformer_pytorch import SE3Transformer
model = SE3Transformer (
dim = 64 ,
depth = 2 ,
input_degrees = 1 ,
num_degrees = 2 ,
output_degrees = 2 ,
reduce_dim_out = True ,
differentiable_coors = True
)
atom_feats = torch . randn ( 2 , 32 , 64 )
coors = torch . randn ( 2 , 32 , 3 )
mask = torch . ones ( 2 , 32 ). bool ()
refined_coors = coors + model ( atom_feats , coors , mask , return_type = 1 ) # (2, 32, 3)Anda juga dapat membiarkan kelas trafo dasar mengurus penyematan fitur tipe 0 yang diteruskan. Dengan asumsi mereka adalah atom
import torch
from se3_transformer_pytorch import SE3Transformer
model = SE3Transformer (
num_tokens = 28 , # 28 unique atoms
dim = 64 ,
depth = 2 ,
input_degrees = 1 ,
num_degrees = 2 ,
output_degrees = 2 ,
reduce_dim_out = True
)
atoms = torch . randint ( 0 , 28 , ( 2 , 32 ))
coors = torch . randn ( 2 , 32 , 3 )
mask = torch . ones ( 2 , 32 ). bool ()
refined_coors = coors + model ( atoms , coors , mask , return_type = 1 ) # (2, 32, 3)Jika menurut Anda internet dapat memperoleh manfaat lebih lanjut dari pengkodean posisi, Anda dapat menampilkan posisi Anda di ruang angkasa dan menyebarkannya sebagai berikut.
import torch
from se3_transformer_pytorch import SE3Transformer
model = SE3Transformer (
dim = 64 ,
depth = 2 ,
input_degrees = 2 ,
num_degrees = 2 ,
output_degrees = 2 ,
reduce_dim_out = True # reduce out the final dimension
)
atom_feats = torch . randn ( 2 , 32 , 64 , 1 ) # b x n x d x type0
coors_feats = torch . randn ( 2 , 32 , 64 , 3 ) # b x n x d x type1
# atom features are type 0, predicted coordinates are type 1
features = { '0' : atom_feats , '1' : coors_feats }
coors = torch . randn ( 2 , 32 , 3 )
mask = torch . ones ( 2 , 32 ). bool ()
refined_coors = coors + model ( features , coors , mask , return_type = 1 ) # (2, 32, 3) - equivariant to input type 1 features and coordinates Untuk menawarkan informasi tepi ke SE3 Transformers (misalnya jenis ikatan antar atom), Anda hanya perlu meneruskan dua argumen kata kunci lagi pada inisialisasi.
import torch
from se3_transformer_pytorch import SE3Transformer
model = SE3Transformer (
num_tokens = 28 ,
dim = 64 ,
num_edge_tokens = 4 , # number of edge type, say 4 bond types
edge_dim = 16 , # dimension of edge embedding
depth = 2 ,
input_degrees = 1 ,
num_degrees = 3 ,
output_degrees = 1 ,
reduce_dim_out = True
)
atoms = torch . randint ( 0 , 28 , ( 2 , 32 ))
bonds = torch . randint ( 0 , 4 , ( 2 , 32 , 32 ))
coors = torch . randn ( 2 , 32 , 3 )
mask = torch . ones ( 2 , 32 ). bool ()
pred = model ( atoms , coors , mask , edges = bonds , return_type = 0 ) # (2, 32, 1) Jika Anda ingin meneruskan nilai kontinu untuk tepian Anda, Anda dapat memilih untuk tidak menyetel num_edge_tokens , menyandikan tipe ikatan diskrit Anda, lalu menggabungkannya ke fitur fourier dari nilai kontinu ini
import torch
from se3_transformer_pytorch import SE3Transformer
from se3_transformer_pytorch . utils import fourier_encode
model = SE3Transformer (
dim = 64 ,
depth = 1 ,
attend_self = True ,
num_degrees = 2 ,
output_degrees = 2 ,
edge_dim = 34 # edge dimension must match the final dimension of the edges being passed in
)
feats = torch . randn ( 1 , 32 , 64 )
coors = torch . randn ( 1 , 32 , 3 )
mask = torch . ones ( 1 , 32 ). bool ()
pairwise_continuous_values = torch . randint ( 0 , 4 , ( 1 , 32 , 32 , 2 )) # say there are 2
edges = fourier_encode (
pairwise_continuous_values ,
num_encodings = 8 ,
include_self = True
) # (1, 32, 32, 34) - {2 * (2 * 8 + 1)}
out = model ( feats , coors , mask , edges = edges , return_type = 1 ) Jika Anda mengetahui konektivitas titik-titik Anda (misalkan Anda bekerja dengan molekul), Anda dapat memasukkan matriks ketetanggaan, dalam bentuk topeng boolean (di mana True menunjukkan konektivitas).
import torch
from se3_transformer_pytorch import SE3Transformer
model = SE3Transformer (
dim = 32 ,
heads = 8 ,
depth = 1 ,
dim_head = 64 ,
num_degrees = 2 ,
valid_radius = 10 ,
attend_sparse_neighbors = True , # this must be set to true, in which case it will assert that you pass in the adjacency matrix
num_neighbors = 0 , # if you set this to 0, it will only consider the connected neighbors as defined by the adjacency matrix. but if you set a value greater than 0, it will continue to fetch the closest points up to this many, excluding the ones already specified by the adjacency matrix
max_sparse_neighbors = 8 # you can cap the number of neighbors, sampled from within your sparse set of neighbors as defined by the adjacency matrix, if specified
)
feats = torch . randn ( 1 , 128 , 32 )
coors = torch . randn ( 1 , 128 , 3 )
mask = torch . ones ( 1 , 128 ). bool ()
# placeholder adjacency matrix
# naively assuming the sequence is one long chain (128, 128)
i = torch . arange ( 128 )
adj_mat = ( i [:, None ] <= ( i [ None , :] + 1 )) & ( i [:, None ] >= ( i [ None , :] - 1 ))
out = model ( feats , coors , mask , adj_mat = adj_mat ) # (1, 128, 512) Anda juga dapat membuat jaringan secara otomatis memperoleh tetangga tingkat N dengan satu kata kunci tambahan num_adj_degrees . Jika Anda ingin sistem membedakan derajat tetangga sebagai informasi tepi, teruskan adj_dim bukan nol.
import torch
from se3_transformer_pytorch . se3_transformer_pytorch import SE3Transformer
model = SE3Transformer (
dim = 64 ,
depth = 1 ,
attend_self = True ,
num_degrees = 2 ,
output_degrees = 2 ,
num_neighbors = 0 ,
attend_sparse_neighbors = True ,
num_adj_degrees = 2 , # automatically derive 2nd degree neighbors
adj_dim = 4 # embed 1st and 2nd degree neighbors (as well as null neighbors) with edge embeddings of this dimension
)
feats = torch . randn ( 1 , 32 , 64 )
coors = torch . randn ( 1 , 32 , 3 )
mask = torch . ones ( 1 , 32 ). bool ()
# placeholder adjacency matrix
# naively assuming the sequence is one long chain (128, 128)
i = torch . arange ( 128 )
adj_mat = ( i [:, None ] <= ( i [ None , :] + 1 )) & ( i [:, None ] >= ( i [ None , :] - 1 ))
out = model ( feats , coors , mask , adj_mat = adj_mat , return_type = 1 ) Untuk memiliki kontrol yang baik atas dimensi setiap jenis, Anda dapat menggunakan kata kunci hidden_fiber_dict dan out_fiber_dict untuk memasukkan kamus dengan nilai derajat ke dimensi sebagai kunci/nilai.
import torch
from se3_transformer_pytorch import SE3Transformer
model = SE3Transformer (
num_tokens = 28 ,
dim = 64 ,
num_edge_tokens = 4 ,
edge_dim = 16 ,
depth = 2 ,
input_degrees = 1 ,
num_degrees = 3 ,
output_degrees = 1 ,
hidden_fiber_dict = { 0 : 16 , 1 : 8 , 2 : 4 },
out_fiber_dict = { 0 : 16 , 1 : 1 },
reduce_dim_out = False
)
atoms = torch . randint ( 0 , 28 , ( 2 , 32 ))
bonds = torch . randint ( 0 , 4 , ( 2 , 32 , 32 ))
coors = torch . randn ( 2 , 32 , 3 )
mask = torch . ones ( 2 , 32 ). bool ()
pred = model ( atoms , coors , mask , edges = bonds )
pred [ '0' ] # (2, 32, 16)
pred [ '1' ] # (2, 32, 1, 3) Anda dapat mengontrol lebih lanjut node mana yang dapat dipertimbangkan dengan meneruskan masker tetangga. Semua nilai False akan ditutupi tanpa pertimbangan.
import torch
from se3_transformer_pytorch . se3_transformer_pytorch import SE3Transformer
model = SE3Transformer (
dim = 16 ,
dim_head = 16 ,
attend_self = True ,
num_degrees = 4 ,
output_degrees = 2 ,
num_edge_tokens = 4 ,
num_neighbors = 8 , # make sure you set this value as the maximum number of neighbors set by your neighbor_mask, or it will throw a warning
edge_dim = 2 ,
depth = 3
)
feats = torch . randn ( 1 , 32 , 16 )
coors = torch . randn ( 1 , 32 , 3 )
mask = torch . ones ( 1 , 32 ). bool ()
bonds = torch . randint ( 0 , 4 , ( 1 , 32 , 32 ))
neighbor_mask = torch . ones ( 1 , 32 , 32 ). bool () # set the nodes you wish to be masked out as False
out = model (
feats ,
coors ,
mask ,
edges = bonds ,
neighbor_mask = neighbor_mask ,
return_type = 1
)Fitur ini memungkinkan Anda meneruskan vektor yang dapat dilihat sebagai node global yang dilihat oleh semua node lainnya. Idenya adalah menggabungkan grafik Anda menjadi beberapa vektor fitur, yang akan diproyeksikan ke kunci/nilai di semua lapisan perhatian dalam jaringan. Semua node akan memiliki akses penuh ke informasi node global, terlepas dari perhitungan tetangga terdekat atau kedekatannya.
import torch
from torch import nn
from se3_transformer_pytorch import SE3Transformer
model = SE3Transformer (
dim = 64 ,
depth = 1 ,
num_degrees = 2 ,
num_neighbors = 4 ,
valid_radius = 10 ,
global_feats_dim = 32 # this must be set to the dimension of the global features, in this example, 32
)
feats = torch . randn ( 1 , 32 , 64 )
coors = torch . randn ( 1 , 32 , 3 )
mask = torch . ones ( 1 , 32 ). bool ()
# naively derive global features
# by pooling features and projecting
global_feats = nn . Linear ( 64 , 32 )( feats . mean ( dim = 1 , keepdim = True )) # (1, 1, 32)
out = model ( feats , coors , mask , return_type = 0 , global_feats = global_feats )Tugas:
Anda dapat menggunakan SE3 Transformers secara autoregresif hanya dengan satu tanda tambahan
import torch
from se3_transformer_pytorch import SE3Transformer
model = SE3Transformer (
dim = 512 ,
heads = 8 ,
depth = 6 ,
dim_head = 64 ,
num_degrees = 4 ,
valid_radius = 10 ,
causal = True # set this to True
)
feats = torch . randn ( 1 , 1024 , 512 )
coors = torch . randn ( 1 , 1024 , 3 )
mask = torch . ones ( 1 , 1024 ). bool ()
out = model ( feats , coors , mask ) # (1, 1024, 512) Saya telah menemukan bahwa menggunakan kunci yang diproyeksikan secara linier (daripada konvolusi berpasangan) tampaknya cukup baik dalam tugas penolakan mainan. Hal ini menyebabkan penghematan memori sebesar 25%. Anda dapat mencoba fitur ini dengan mengatur linear_proj_keys = True
import torch
from se3_transformer_pytorch import SE3Transformer
model = SE3Transformer (
dim = 64 ,
depth = 1 ,
num_degrees = 4 ,
num_neighbors = 8 ,
valid_radius = 10 ,
splits = 4 ,
linear_proj_keys = True # set this to True
). cuda ()
feats = torch . randn ( 1 , 32 , 64 ). cuda ()
coors = torch . randn ( 1 , 32 , 3 ). cuda ()
mask = torch . ones ( 1 , 32 ). bool (). cuda ()
out = model ( feats , coors , mask , return_type = 0 )Ada teknik yang relatif tidak diketahui untuk transformator di mana seseorang dapat berbagi satu kepala kunci/nilai di semua kepala kueri. Dalam pengalaman saya di NLP, hal ini biasanya menyebabkan kinerja lebih buruk, tetapi jika Anda benar-benar perlu mengorbankan memori untuk kedalaman yang lebih besar atau jumlah derajat yang lebih tinggi, ini mungkin merupakan pilihan yang baik.
import torch
from se3_transformer_pytorch import SE3Transformer
model = SE3Transformer (
dim = 64 ,
depth = 8 ,
num_degrees = 4 ,
num_neighbors = 8 ,
valid_radius = 10 ,
splits = 4 ,
one_headed_key_values = True # one head of key / values shared across all heads of the queries
). cuda ()
feats = torch . randn ( 1 , 32 , 64 ). cuda ()
coors = torch . randn ( 1 , 32 , 3 ). cuda ()
mask = torch . ones ( 1 , 32 ). bool (). cuda ()
out = model ( feats , coors , mask , return_type = 0 )Anda juga dapat mengikat kunci/nilai (menjadikannya sama), untuk menghemat separuh memori
import torch
from se3_transformer_pytorch import SE3Transformer
model = SE3Transformer (
dim = 64 ,
depth = 8 ,
num_degrees = 4 ,
num_neighbors = 8 ,
valid_radius = 10 ,
splits = 4 ,
tie_key_values = True # set this to True
). cuda ()
feats = torch . randn ( 1 , 32 , 64 ). cuda ()
coors = torch . randn ( 1 , 32 , 3 ). cuda ()
mask = torch . ones ( 1 , 32 ). bool (). cuda ()
out = model ( feats , coors , mask , return_type = 0 ) Ini adalah versi eksperimental EGNN yang berfungsi untuk tipe yang lebih tinggi, dan dimensi yang lebih besar dari hanya 1 (untuk koordinat). Nama kelasnya tetap SE3Transformer karena menggunakan kembali beberapa logika yang sudah ada sebelumnya, jadi abaikan saja untuk saat ini hingga saya membersihkannya nanti.
import torch
from se3_transformer_pytorch import SE3Transformer
model = SE3Transformer (
dim = 32 ,
num_neighbors = 8 ,
num_edge_tokens = 4 ,
edge_dim = 4 ,
num_degrees = 4 , # number of higher order types - will use basis on a TCN to project to these dimensions
use_egnn = True , # set this to true to use EGNN instead of equivariant attention layers
egnn_hidden_dim = 64 , # egnn hidden dimension
depth = 4 , # depth of EGNN
reduce_dim_out = True # will project the dimension of the higher types to 1
). cuda ()
feats = torch . randn ( 2 , 32 , 32 ). cuda ()
coors = torch . randn ( 2 , 32 , 3 ). cuda ()
bonds = torch . randint ( 0 , 4 , ( 2 , 32 , 32 )). cuda ()
mask = torch . ones ( 2 , 32 ). bool (). cuda ()
refinement = model ( feats , coors , mask , edges = bonds , return_type = 1 ) # (2, 32, 3)
coors = coors + refinement # update coors with refinement Jika Anda ingin menentukan dimensi individual untuk masing-masing tipe yang lebih tinggi, cukup masukkan hidden_fiber_dict dengan kamus dalam format {<degree>:<dim>}, bukan num_degrees
import torch
from se3_transformer_pytorch import SE3Transformer
model = SE3Transformer (
dim = 32 ,
num_neighbors = 8 ,
hidden_fiber_dict = { 0 : 32 , 1 : 16 , 2 : 8 , 3 : 4 },
use_egnn = True ,
depth = 4 ,
egnn_hidden_dim = 64 ,
egnn_weights_clamp_value = 2 ,
reduce_dim_out = True
). cuda ()
feats = torch . randn ( 2 , 32 , 32 ). cuda ()
coors = torch . randn ( 2 , 32 , 3 ). cuda ()
mask = torch . ones ( 2 , 32 ). bool (). cuda ()
refinement = model ( feats , coors , mask , return_type = 1 ) # (2, 32, 3)
coors = coors + refinement # update coors with refinement Bagian ini akan mencantumkan upaya berkelanjutan untuk membuat skala SE3 Transformer sedikit lebih baik.
Pertama, saya telah menambahkan jaringan yang dapat dibalik. Hal ini memungkinkan saya untuk menambahkan sedikit lebih dalam sebelum mencapai hambatan memori yang biasa. Pelestarian ekuivariansi ditunjukkan dalam pengujian.
import torch
from se3_transformer_pytorch import SE3Transformer
model = SE3Transformer (
num_tokens = 20 ,
dim = 32 ,
dim_head = 32 ,
heads = 4 ,
depth = 12 , # 12 layers
input_degrees = 1 ,
num_degrees = 3 ,
output_degrees = 1 ,
reduce_dim_out = True ,
reversible = True # set reversible to True
). cuda ()
atoms = torch . randint ( 0 , 4 , ( 2 , 32 )). cuda ()
coors = torch . randn ( 2 , 32 , 3 ). cuda ()
mask = torch . ones ( 2 , 32 ). bool (). cuda ()
pred = model ( atoms , coors , mask = mask , return_type = 0 )
loss = pred . sum ()
loss . backward () Pertama instal sidechainnet
$ pip install sidechainnetKemudian jalankan tugas penolakan tulang punggung protein
$ python denoise.py Secara default, vektor basis di-cache. Namun, jika ada kebutuhan untuk menghapus cache, Anda cukup mengatur flag lingkungan CLEAR_CACHE ke beberapa nilai saat memulai skrip
$ CLEAR_CACHE=1 python train.pyAtau Anda dapat mencoba menghapus direktori cache yang seharusnya ada di
$ rm -rf ~ /.cache.equivariant_attentionAnda juga dapat menentukan direktori Anda sendiri di mana Anda ingin menyimpan cache, jika direktori default mungkin memiliki masalah izin
CACHE_PATH=./path/to/my/cache python train.py$ python setup.py pytestPerpustakaan ini sebagian besar merupakan port dari repositori resmi Fabian, tetapi tanpa perpustakaan DGL.
@misc { fuchs2020se3transformers ,
title = { SE(3)-Transformers: 3D Roto-Translation Equivariant Attention Networks } ,
author = { Fabian B. Fuchs and Daniel E. Worrall and Volker Fischer and Max Welling } ,
year = { 2020 } ,
eprint = { 2006.10503 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.LG }
} @misc { satorras2021en ,
title = { E(n) Equivariant Graph Neural Networks } ,
author = { Victor Garcia Satorras and Emiel Hoogeboom and Max Welling } ,
year = { 2021 } ,
eprint = { 2102.09844 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.LG }
} @misc { gomez2017reversible ,
title = { The Reversible Residual Network: Backpropagation Without Storing Activations } ,
author = { Aidan N. Gomez and Mengye Ren and Raquel Urtasun and Roger B. Grosse } ,
year = { 2017 } ,
eprint = { 1707.04585 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { shazeer2019fast ,
title = { Fast Transformer Decoding: One Write-Head is All You Need } ,
author = { Noam Shazeer } ,
year = { 2019 } ,
eprint = { 1911.02150 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.NE }
}

