WeClone
1.0.0
Menggunakan rekaman obrolan WeChat untuk menyempurnakan model bahasa yang besar, saya menggunakan sekitar 20.000 data efektif terintegrasi. Hasil akhirnya hanya bisa dikatakan kurang memuaskan, namun terkadang sangat lucu.
Penting
Saat ini, proyek menggunakan model chatglm3-6b secara default, dan metode LoRA digunakan untuk menyempurnakan tahap sft, yang memerlukan memori video sekitar 16 GB. Anda juga dapat menggunakan model dan metode lain yang didukung oleh LLaMA Factory, yang menggunakan lebih sedikit memori video. Anda perlu memodifikasi sendiri kata-kata perintah sistem templat dan konfigurasi terkait lainnya.
Perkiraan kebutuhan memori video:
| metode pelatihan | Ketepatan | 7B | 13B | 30B | 65B | 8x7B |
|---|---|---|---|---|---|---|
| Parameter lengkap | 16 | 160GB | 320GB | 600GB | 1200GB | 900GB |
| Beberapa parameter | 16 | 20GB | 40GB | 120GB | 240GB | 200GB |
| LoRA | 16 | 16 GB | 32GB | 80GB | 160GB | 120GB |
| QLoRA | 8 | 10GB | 16 GB | 40GB | 80GB | 80GB |
| QLoRA | 4 | 6GB | 12GB | 24GB | 48GB | 32GB |
| Diperlukan | Setidaknya | menyarankan |
|---|---|---|
| ular piton | 3.8 | 3.10 |
| obor | 1.13.1 | 2.2.1 |
| transformator | 4.37.2 | 4.38.1 |
| kumpulan data | 2.14.3 | 2.17.1 |
| mempercepat | 0.27.2 | 0.27.2 |
| peft | 0.9.0 | 0.9.0 |
| trl | 0.7.11 | 0.7.11 |
| Opsional | Setidaknya | menyarankan |
|---|---|---|
| CUDA | 11.6 | 12.2 |
| kecepatan dalam | 0.10.0 | 0.13.4 |
| bitsandbytes | 0.39.0 | 0.41.3 |
| flash-attn | 2.3.0 | 2.5.5 |
git clone https://github.com/xming521/WeClone.git
conda create -n weclone python=3.10
conda activate weclone
cd WeClone
pip install -r requirements.txtKonfigurasi terkait pelatihan dan inferensi disatukan dalam file settings.json
Silakan gunakan PyWxDump untuk mengekstrak catatan obrolan WeChat. Setelah mengunduh perangkat lunak dan mendekripsi database, klik Cadangan Obrolan. Jenis ekspornya adalah CSV. Anda dapat mengekspor beberapa kontak atau obrolan grup, lalu letakkan folder csv yang diekspor yang terletak di wxdump_tmp/export di direktori ./data , yang berbeda. Folder rekaman obrolan orang-orang ditempatkan bersama di ./data/csv . Contoh data terletak di data/example_chat.csv.
Secara default, proyek menghapus nomor ponsel, nomor ID, alamat email, dan alamat situs web dari data. Ini juga menyediakan database kata-kata yang dilarang, kata-kata yang diblokir, di mana Anda dapat menambahkan kata dan kalimat yang perlu disaring (seluruh kalimat termasuk kata-kata yang dilarang akan dihapus secara default). Jalankan skrip ./make_dataset/csv_to_json.py untuk memproses data.
Ketika orang yang sama menjawab beberapa kalimat secara berurutan, ada tiga cara untuk menanganinya:
| dokumen | Metode pengolahan |
|---|---|
| csv_to_json.py | Hubungkan dengan koma |
| csv_to_json-kalimat tunggalanswer.py (usang) | Hanya jawaban terpanjang yang dipilih sebagai data akhir |
| csv_to_json-kalimat tunggal beberapa putaran.py | Ditempatkan di 'sejarah' kata cepat |
Pilihan pertama adalah mendownload model ChatGLM3 dari Hugging Face. Jika Anda mengalami masalah saat mengunduh model Hugging Face, Anda dapat menggunakan komunitas MoDELSCOPE melalui metode berikut. Untuk pelatihan dan inferensi selanjutnya, Anda perlu menjalankan export USE_MODELSCOPE_HUB=1 terlebih dahulu untuk menggunakan model komunitas MoDELSCOPE.
Karena ukuran model yang besar maka proses download akan memakan waktu yang lama, harap bersabar.
export USE_MODELSCOPE_HUB=1 # Windows 使用 `set USE_MODELSCOPE_HUB=1`
git lfs install
git clone https://www.modelscope.cn/ZhipuAI/chatglm3-6b.git(Opsional) Ubah settings.json untuk memilih model lain yang diunduh secara lokal.
Ubah per_device_train_batch_size dan gradient_accumulation_steps untuk menyesuaikan penggunaan memori video.
Anda dapat mengubah parameter seperti num_train_epochs , lora_rank , lora_dropout sesuai dengan kuantitas dan kualitas kumpulan data Anda sendiri.
Jalankan src/train_sft.py untuk menyempurnakan tahap sft. Kerugian saya hanya turun menjadi sekitar 3,5. Jika dikurangi terlalu banyak, dapat menyebabkan over-fitting.
python src/train_sft.pypip install deepspeed
deepspeed --num_gpus=使用显卡数量 src/train_sft.pyCatatan
Anda juga dapat menyempurnakan tahap pt terlebih dahulu. Tampaknya efek peningkatannya tidak terlihat jelas. Gudang juga menyediakan kode untuk pra-pemrosesan dan pelatihan kumpulan data tahap pt.
python ./src/web_demo.py python ./src/api_service.pypython ./src/api_service.py
python ./src/test_model.pyPenting
Ada risiko penutupan akun di WeChat. Disarankan untuk menggunakan akun kecil dan harus mengikat kartu bank untuk menggunakannya.
python ./src/api_service.py # 先启动api服务
python ./src/wechat_bot/main.py Secara default, kode QR ditampilkan di terminal, cukup pindai kode untuk masuk. Dapat digunakan dalam obrolan pribadi atau obrolan grup @bot.
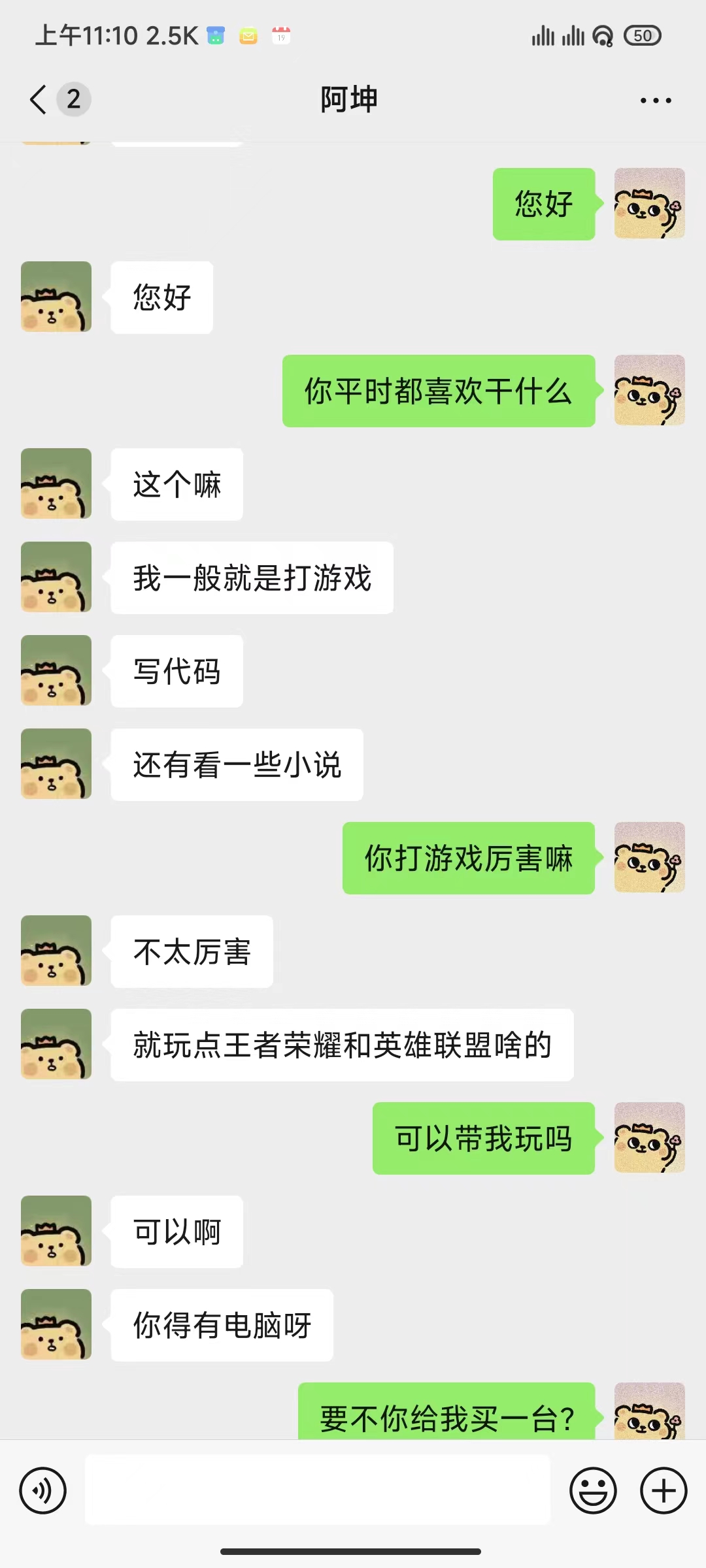

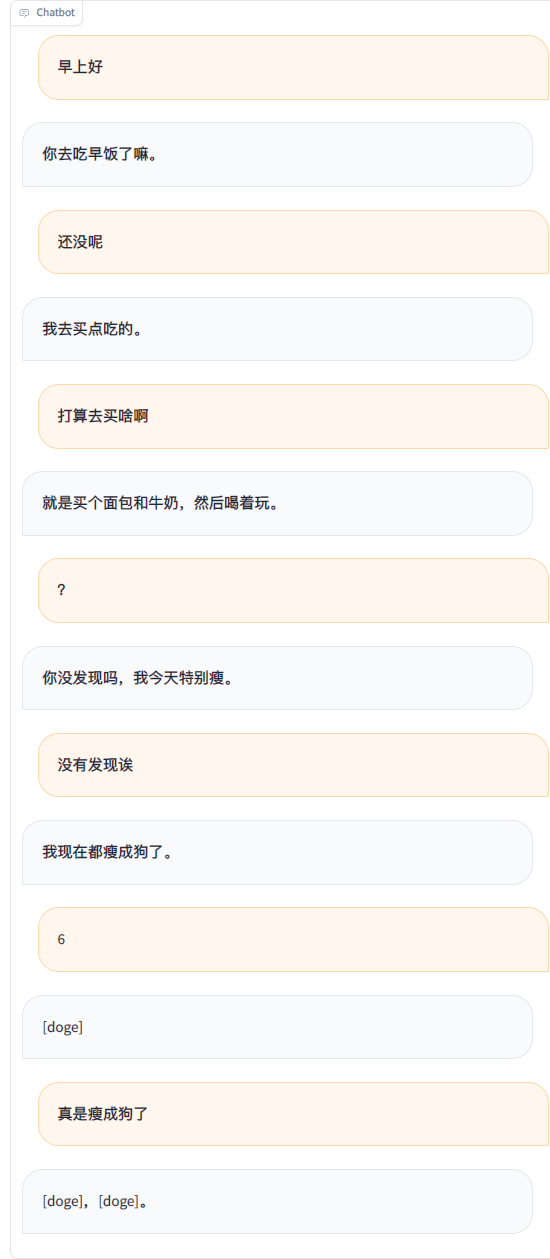
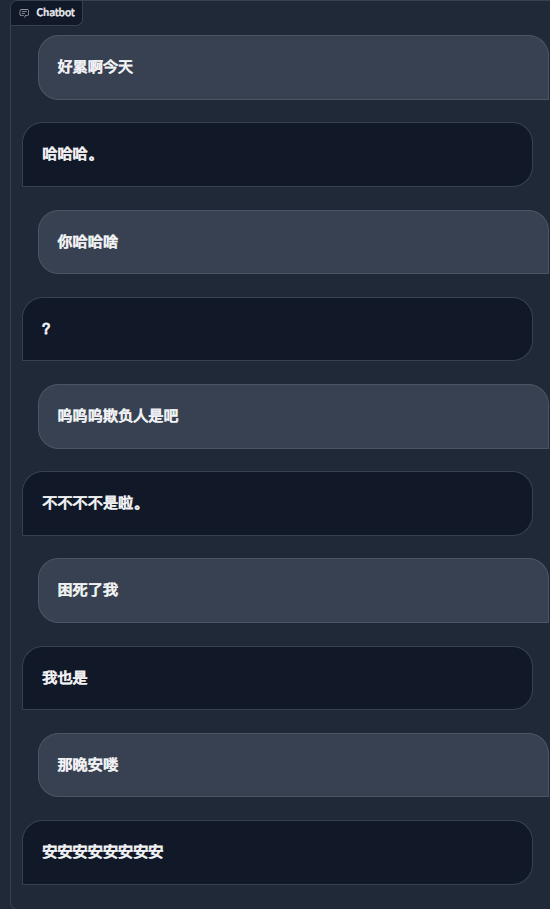
Semua yang harus dilakukan
Semua yang harus dilakukan


