whisper.cpp
v1.7.2
Stabil: V1.7.2 / Roadmap | FAQ
Inferensi kinerja tinggi dari model pengenalan wispen ucapan otomatis (ASR) Openai:
Platform yang Didukung:
Seluruh implementasi tingkat tinggi dari model ini terkandung dalam Whisper.h dan Whisper.cpp. Sisa kode adalah bagian dari Perpustakaan Pembelajaran Mesin ggml .
Memiliki implementasi model yang ringan memungkinkan untuk dengan mudah mengintegrasikannya dalam platform dan aplikasi yang berbeda. Sebagai contoh, berikut adalah video menjalankan model pada perangkat iPhone 13 - sepenuhnya offline, on -device: whisper.objc
Anda juga dapat dengan mudah membuat aplikasi asisten suara offline Anda sendiri: perintah
Pada silikon apel, inferensi berjalan sepenuhnya pada GPU melalui logam:
Atau Anda bahkan dapat menjalankannya langsung di browser: bicara.wasme
Operator tensor dioptimalkan banyak untuk CPU silikon apel. Bergantung pada ukuran perhitungan, intrinsik ARM Neon SIMD atau rutinitas kerangka kerja CBLA Accelerate digunakan. Yang terakhir ini sangat efektif untuk ukuran yang lebih besar karena kerangka kerja Accelerate menggunakan coprocessor AMX tujuan khusus yang tersedia dalam produk Apple modern.
Klon pertama repositori:
git clone https://github.com/ggerganov/whisper.cpp.gitMenavigasi ke direktori:
cd whisper.cpp
Kemudian, unduh salah satu model Whisper yang dikonversi dalam format ggml . Misalnya:
sh ./models/download-ggml-model.sh base.enSekarang bangun contoh utama dan transkripsi file audio seperti ini:
# build the main example
make -j
# transcribe an audio file
./main -f samples/jfk.wav Untuk demo cepat, cukup jalankan make base.en :
$ make -j base.en
cc -I. -O3 -std=c11 -pthread -DGGML_USE_ACCELERATE -c ggml.c -o ggml.o
c++ -I. -I./examples -O3 -std=c++11 -pthread -c whisper.cpp -o whisper.o
c++ -I. -I./examples -O3 -std=c++11 -pthread examples/main/main.cpp whisper.o ggml.o -o main -framework Accelerate
./main -h
usage: ./main [options] file0.wav file1.wav ...
options:
-h, --help [default] show this help message and exit
-t N, --threads N [4 ] number of threads to use during computation
-p N, --processors N [1 ] number of processors to use during computation
-ot N, --offset-t N [0 ] time offset in milliseconds
-on N, --offset-n N [0 ] segment index offset
-d N, --duration N [0 ] duration of audio to process in milliseconds
-mc N, --max-context N [-1 ] maximum number of text context tokens to store
-ml N, --max-len N [0 ] maximum segment length in characters
-sow, --split-on-word [false ] split on word rather than on token
-bo N, --best-of N [5 ] number of best candidates to keep
-bs N, --beam-size N [5 ] beam size for beam search
-wt N, --word-thold N [0.01 ] word timestamp probability threshold
-et N, --entropy-thold N [2.40 ] entropy threshold for decoder fail
-lpt N, --logprob-thold N [-1.00 ] log probability threshold for decoder fail
-debug, --debug-mode [false ] enable debug mode (eg. dump log_mel)
-tr, --translate [false ] translate from source language to english
-di, --diarize [false ] stereo audio diarization
-tdrz, --tinydiarize [false ] enable tinydiarize (requires a tdrz model)
-nf, --no-fallback [false ] do not use temperature fallback while decoding
-otxt, --output-txt [false ] output result in a text file
-ovtt, --output-vtt [false ] output result in a vtt file
-osrt, --output-srt [false ] output result in a srt file
-olrc, --output-lrc [false ] output result in a lrc file
-owts, --output-words [false ] output script for generating karaoke video
-fp, --font-path [/System/Library/Fonts/Supplemental/Courier New Bold.ttf] path to a monospace font for karaoke video
-ocsv, --output-csv [false ] output result in a CSV file
-oj, --output-json [false ] output result in a JSON file
-ojf, --output-json-full [false ] include more information in the JSON file
-of FNAME, --output-file FNAME [ ] output file path (without file extension)
-ps, --print-special [false ] print special tokens
-pc, --print-colors [false ] print colors
-pp, --print-progress [false ] print progress
-nt, --no-timestamps [false ] do not print timestamps
-l LANG, --language LANG [en ] spoken language ('auto' for auto-detect)
-dl, --detect-language [false ] exit after automatically detecting language
--prompt PROMPT [ ] initial prompt
-m FNAME, --model FNAME [models/ggml-base.en.bin] model path
-f FNAME, --file FNAME [ ] input WAV file path
-oved D, --ov-e-device DNAME [CPU ] the OpenVINO device used for encode inference
-ls, --log-score [false ] log best decoder scores of tokens
-ng, --no-gpu [false ] disable GPU
sh ./models/download-ggml-model.sh base.en
Downloading ggml model base.en ...
ggml-base.en.bin 100%[========================>] 141.11M 6.34MB/s in 24s
Done! Model 'base.en' saved in 'models/ggml-base.en.bin'
You can now use it like this:
$ ./main -m models/ggml-base.en.bin -f samples/jfk.wav
===============================================
Running base.en on all samples in ./samples ...
===============================================
----------------------------------------------
[+] Running base.en on samples/jfk.wav ... (run 'ffplay samples/jfk.wav' to listen)
----------------------------------------------
whisper_init_from_file: loading model from 'models/ggml-base.en.bin'
whisper_model_load: loading model
whisper_model_load: n_vocab = 51864
whisper_model_load: n_audio_ctx = 1500
whisper_model_load: n_audio_state = 512
whisper_model_load: n_audio_head = 8
whisper_model_load: n_audio_layer = 6
whisper_model_load: n_text_ctx = 448
whisper_model_load: n_text_state = 512
whisper_model_load: n_text_head = 8
whisper_model_load: n_text_layer = 6
whisper_model_load: n_mels = 80
whisper_model_load: f16 = 1
whisper_model_load: type = 2
whisper_model_load: mem required = 215.00 MB (+ 6.00 MB per decoder)
whisper_model_load: kv self size = 5.25 MB
whisper_model_load: kv cross size = 17.58 MB
whisper_model_load: adding 1607 extra tokens
whisper_model_load: model ctx = 140.60 MB
whisper_model_load: model size = 140.54 MB
system_info: n_threads = 4 / 10 | AVX = 0 | AVX2 = 0 | AVX512 = 0 | FMA = 0 | NEON = 1 | ARM_FMA = 1 | F16C = 0 | FP16_VA = 1 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 0 | VSX = 0 |
main: processing 'samples/jfk.wav' (176000 samples, 11.0 sec), 4 threads, 1 processors, lang = en, task = transcribe, timestamps = 1 ...
[00:00:00.000 --> 00:00:11.000] And so my fellow Americans, ask not what your country can do for you, ask what you can do for your country.
whisper_print_timings: fallbacks = 0 p / 0 h
whisper_print_timings: load time = 113.81 ms
whisper_print_timings: mel time = 15.40 ms
whisper_print_timings: sample time = 11.58 ms / 27 runs ( 0.43 ms per run)
whisper_print_timings: encode time = 266.60 ms / 1 runs ( 266.60 ms per run)
whisper_print_timings: decode time = 66.11 ms / 27 runs ( 2.45 ms per run)
whisper_print_timings: total time = 476.31 ms
Perintah mengunduh model base.en yang dikonversi ke format ggml khusus dan menjalankan inferensi pada semua sampel .wav dalam samples folder.
Untuk instruksi penggunaan terperinci, jalankan: ./main -h
Perhatikan bahwa contoh utama saat ini hanya berjalan dengan file WAV 16-bit, jadi pastikan untuk mengonversi input Anda sebelum menjalankan alat. Misalnya, Anda dapat menggunakan ffmpeg seperti ini:
ffmpeg -i input.mp3 -ar 16000 -ac 1 -c:a pcm_s16le output.wavJika Anda ingin beberapa sampel audio tambahan dimainkan, cukup jalankan:
make -j samples
Ini akan mengunduh beberapa file audio lagi dari Wikipedia dan mengonversinya menjadi format WAV 16-bit melalui ffmpeg .
Anda dapat mengunduh dan menjalankan model lain sebagai berikut:
make -j tiny.en
make -j tiny
make -j base.en
make -j base
make -j small.en
make -j small
make -j medium.en
make -j medium
make -j large-v1
make -j large-v2
make -j large-v3
make -j large-v3-turbo
| Model | Disk | Mem |
|---|---|---|
| kecil | 75 MIB | ~ 273 MB |
| basis | 142 MIB | ~ 388 MB |
| kecil | 466 MIB | ~ 852 MB |
| sedang | 1.5 Gib | ~ 2.1 GB |
| besar | 2.9 Gib | ~ 3,9 GB |
whisper.cpp mendukung kuantisasi integer dari model ggml Whisper. Model terkuantisasi membutuhkan lebih sedikit ruang memori dan disk dan tergantung pada perangkat keras dapat diproses lebih efisien.
Berikut adalah langkah -langkah untuk membuat dan menggunakan model terkuantisasi:
# quantize a model with Q5_0 method
make -j quantize
./quantize models/ggml-base.en.bin models/ggml-base.en-q5_0.bin q5_0
# run the examples as usual, specifying the quantized model file
./main -m models/ggml-base.en-q5_0.bin ./samples/gb0.wav Pada perangkat Apple Silicon, inferensi encoder dapat dieksekusi pada Apple Neural Engine (ANE) melalui Core ML. Ini dapat menghasilkan percepatan yang signifikan-lebih dari x3 lebih cepat dibandingkan dengan eksekusi CPU saja. Berikut adalah instruksi untuk menghasilkan model ML inti dan menggunakannya dengan whisper.cpp :
Pasang dependensi Python yang diperlukan untuk pembuatan model inti ML:
pip install ane_transformers
pip install openai-whisper
pip install coremltoolscoremltools beroperasi dengan benar, harap konfirmasi bahwa XCODE diinstal dan jalankan xcode-select --install untuk menginstal alat baris perintah.conda create -n py310-whisper python=3.10 -yconda activate py310-whisper Menghasilkan model inti ML. Misalnya, untuk menghasilkan model base.en , gunakan:
./models/generate-coreml-model.sh base.en Ini akan menghasilkan models/ggml-base.en-encoder.mlmodelc
Bangun whisper.cpp dengan Dukungan Inti ML:
# using Makefile
make clean
WHISPER_COREML=1 make -j
# using CMake
cmake -B build -DWHISPER_COREML=1
cmake --build build -j --config ReleaseJalankan contoh seperti biasa. Misalnya:
$ ./main -m models/ggml-base.en.bin -f samples/jfk.wav
...
whisper_init_state: loading Core ML model from 'models/ggml-base.en-encoder.mlmodelc'
whisper_init_state: first run on a device may take a while ...
whisper_init_state: Core ML model loaded
system_info: n_threads = 4 / 10 | AVX = 0 | AVX2 = 0 | AVX512 = 0 | FMA = 0 | NEON = 1 | ARM_FMA = 1 | F16C = 0 | FP16_VA = 1 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 0 | VSX = 0 | COREML = 1 |
...
Run pertama pada perangkat lambat, karena layanan ANE mengkompilasi model ML inti ke beberapa format khusus perangkat. Lari berikutnya lebih cepat.
Untuk informasi lebih lanjut tentang implementasi inti ML, silakan merujuk ke PR #566.
Pada platform yang mendukung OpenVino, inferensi encoder dapat dieksekusi pada perangkat yang didukung OpenVino termasuk X86 CPU dan Intel GPU (terintegrasi & diskrit).
Ini dapat menghasilkan percepatan yang signifikan dalam kinerja encoder. Berikut adalah instruksi untuk menghasilkan model OpenVino dan menggunakannya dengan whisper.cpp :
Pertama, setup Python Virtual Env. dan instal dependensi Python. Python 3.10 direkomendasikan.
Windows:
cd models
python - m venv openvino_conv_env
openvino_conv_envScriptsactivate
python - m pip install -- upgrade pip
pip install - r requirements - openvino.txtLinux dan MacOS:
cd models
python3 -m venv openvino_conv_env
source openvino_conv_env/bin/activate
python -m pip install --upgrade pip
pip install -r requirements-openvino.txt Menghasilkan model encoder OpenVino. Misalnya, untuk menghasilkan model base.en , gunakan:
python convert-whisper-to-openvino.py --model base.en
Ini akan menghasilkan file model GGML-base.en-encoder-openvino.xml/.bin IR. Disarankan untuk memindahkan ini ke folder yang sama dengan model ggml , karena itu adalah lokasi default yang akan dicari oleh ekstensi OpenVino saat runtime.
Bangun whisper.cpp dengan Dukungan OpenVino:
Unduh paket OpenVino dari halaman rilis. Versi yang disarankan untuk digunakan adalah 2023.0.0.
Setelah mengunduh & mengekstraksi paket ke sistem pengembangan Anda, atur lingkungan yang diperlukan dengan sumber skrip setupvars. Misalnya:
Linux:
source /path/to/l_openvino_toolkit_ubuntu22_2023.0.0.10926.b4452d56304_x86_64/setupvars.shWindows (CMD):
C:PathTow_openvino_toolkit_windows_2023. 0.0 . 10926. b4452d56304_x86_64 setupvars.batDan kemudian membangun proyek menggunakan cmake:
cmake -B build -DWHISPER_OPENVINO=1
cmake --build build -j --config ReleaseJalankan contoh seperti biasa. Misalnya:
$ ./main -m models/ggml-base.en.bin -f samples/jfk.wav
...
whisper_ctx_init_openvino_encoder: loading OpenVINO model from 'models/ggml-base.en-encoder-openvino.xml'
whisper_ctx_init_openvino_encoder: first run on a device may take a while ...
whisper_openvino_init: path_model = models/ggml-base.en-encoder-openvino.xml, device = GPU, cache_dir = models/ggml-base.en-encoder-openvino-cache
whisper_ctx_init_openvino_encoder: OpenVINO model loaded
system_info: n_threads = 4 / 8 | AVX = 1 | AVX2 = 1 | AVX512 = 0 | FMA = 1 | NEON = 0 | ARM_FMA = 0 | F16C = 1 | FP16_VA = 0 | WASM_SIMD = 0 | BLAS = 0 | SSE3 = 1 | VSX = 0 | COREML = 0 | OPENVINO = 1 |
...
Pertama kali dijalankan pada perangkat OpenVino lambat, karena kerangka OpenVino akan mengkompilasi model IR (Representasi Menengah) ke 'Blob' khusus perangkat. Gumpalan khusus perangkat ini akan di-cache untuk menjalankan berikutnya.
Untuk informasi lebih lanjut tentang implementasi inti ML, silakan merujuk ke PR #1037.
Dengan kartu NVIDIA, pemrosesan model dilakukan secara efisien pada GPU melalui cublas dan kernel CUDA khusus. Pertama, pastikan Anda telah menginstal cuda : https://developer.nvidia.com/Cuda-Downloads
Sekarang bangun whisper.cpp dengan dukungan cuda:
make clean
GGML_CUDA=1 make -j
Solusi Cross-Vendor yang memungkinkan Anda untuk mempercepat beban kerja di GPU Anda. Pertama, pastikan driver kartu grafis Anda memberikan dukungan untuk API Vulkan.
Sekarang bangun whisper.cpp dengan dukungan vulkan:
make clean
make GGML_VULKAN=1 -j
Pemrosesan encoder dapat dipercepat pada CPU melalui OpenBlas. Pertama, pastikan Anda telah menginstal openblas : https://www.openblas.net/
Sekarang bangun whisper.cpp dengan dukungan openblas:
make clean
GGML_OPENBLAS=1 make -j
Pemrosesan encoder dapat dipercepat pada CPU melalui antarmuka kompatibel BLAS dari perpustakaan Kernel Matematika Intel. Pertama, pastikan Anda telah menginstal Runtime dan Paket Pengembangan MKL Intel: https://www.intel.com/content/www/us/en/developer/tools/oneapi/onemkl-download.html
Sekarang bangun whisper.cpp dengan dukungan intel mkl blas:
source /opt/intel/oneapi/setvars.sh
mkdir build
cd build
cmake -DWHISPER_MKL=ON ..
WHISPER_MKL=1 make -j
Ascend NPU memberikan akselerasi inferensi melalui inti CANN dan AI.
Pertama, periksa apakah perangkat NPU Ascend Anda didukung:
Perangkat terverifikasi
| Ascend NPU | Status |
|---|---|
| Atlas 300t A2 | Mendukung |
Kemudian, pastikan Anda telah menginstal CANN toolkit . Versi CANN yang terakhir direkomendasikan.
Sekarang bangun whisper.cpp dengan dukungan cann:
mkdir build
cd build
cmake .. -D GGML_CANN=on
make -j
Jalankan contoh inferensi seperti biasa, misalnya:
./build/bin/main -f samples/jfk.wav -m models/ggml-base.en.bin -t 8
Catatan:
Verified devices tabel. Kami memiliki dua gambar Docker yang tersedia untuk proyek ini:
ghcr.io/ggerganov/whisper.cpp:main : Gambar ini menyertakan file utama yang dapat dieksekusi serta curl dan ffmpeg . (Platform: linux/amd64 , linux/arm64 )ghcr.io/ggerganov/whisper.cpp:main-cuda : Sama seperti main tetapi dikompilasi dengan dukungan CUDA. (Platform: linux/amd64 ) # download model and persist it in a local folder
docker run -it --rm
-v path/to/models:/models
whisper.cpp:main " ./models/download-ggml-model.sh base /models "
# transcribe an audio file
docker run -it --rm
-v path/to/models:/models
-v path/to/audios:/audios
whisper.cpp:main " ./main -m /models/ggml-base.bin -f /audios/jfk.wav "
# transcribe an audio file in samples folder
docker run -it --rm
-v path/to/models:/models
whisper.cpp:main " ./main -m /models/ggml-base.bin -f ./samples/jfk.wav " Anda dapat menginstal binari pra-dibangun untuk Whisper.cpp atau membangunnya dari sumber menggunakan Conan. Gunakan perintah berikut:
conan install --requires="whisper-cpp/[*]" --build=missing
Untuk instruksi terperinci tentang cara menggunakan Conan, silakan merujuk ke dokumentasi Conan.
Berikut adalah contoh lain dari menyalin pidato 3:24 menit dalam waktu sekitar setengah menit di MacBook M1 Pro, menggunakan model medium.en :
$ ./main -m models/ggml-medium.en.bin -f samples/gb1.wav -t 8
whisper_init_from_file: loading model from 'models/ggml-medium.en.bin'
whisper_model_load: loading model
whisper_model_load: n_vocab = 51864
whisper_model_load: n_audio_ctx = 1500
whisper_model_load: n_audio_state = 1024
whisper_model_load: n_audio_head = 16
whisper_model_load: n_audio_layer = 24
whisper_model_load: n_text_ctx = 448
whisper_model_load: n_text_state = 1024
whisper_model_load: n_text_head = 16
whisper_model_load: n_text_layer = 24
whisper_model_load: n_mels = 80
whisper_model_load: f16 = 1
whisper_model_load: type = 4
whisper_model_load: mem required = 1720.00 MB (+ 43.00 MB per decoder)
whisper_model_load: kv self size = 42.00 MB
whisper_model_load: kv cross size = 140.62 MB
whisper_model_load: adding 1607 extra tokens
whisper_model_load: model ctx = 1462.35 MB
whisper_model_load: model size = 1462.12 MB
system_info: n_threads = 8 / 10 | AVX = 0 | AVX2 = 0 | AVX512 = 0 | FMA = 0 | NEON = 1 | ARM_FMA = 1 | F16C = 0 | FP16_VA = 1 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 0 | VSX = 0 |
main: processing 'samples/gb1.wav' (3179750 samples, 198.7 sec), 8 threads, 1 processors, lang = en, task = transcribe, timestamps = 1 ...
[00:00:00.000 --> 00:00:08.000] My fellow Americans, this day has brought terrible news and great sadness to our country.
[00:00:08.000 --> 00:00:17.000] At nine o'clock this morning, Mission Control in Houston lost contact with our Space Shuttle Columbia.
[00:00:17.000 --> 00:00:23.000] A short time later, debris was seen falling from the skies above Texas.
[00:00:23.000 --> 00:00:29.000] The Columbia's lost. There are no survivors.
[00:00:29.000 --> 00:00:32.000] On board was a crew of seven.
[00:00:32.000 --> 00:00:39.000] Colonel Rick Husband, Lieutenant Colonel Michael Anderson, Commander Laurel Clark,
[00:00:39.000 --> 00:00:48.000] Captain David Brown, Commander William McCool, Dr. Kultna Shavla, and Ilan Ramon,
[00:00:48.000 --> 00:00:52.000] a colonel in the Israeli Air Force.
[00:00:52.000 --> 00:00:58.000] These men and women assumed great risk in the service to all humanity.
[00:00:58.000 --> 00:01:03.000] In an age when space flight has come to seem almost routine,
[00:01:03.000 --> 00:01:07.000] it is easy to overlook the dangers of travel by rocket
[00:01:07.000 --> 00:01:12.000] and the difficulties of navigating the fierce outer atmosphere of the Earth.
[00:01:12.000 --> 00:01:18.000] These astronauts knew the dangers, and they faced them willingly,
[00:01:18.000 --> 00:01:23.000] knowing they had a high and noble purpose in life.
[00:01:23.000 --> 00:01:31.000] Because of their courage and daring and idealism, we will miss them all the more.
[00:01:31.000 --> 00:01:36.000] All Americans today are thinking as well of the families of these men and women
[00:01:36.000 --> 00:01:40.000] who have been given this sudden shock and grief.
[00:01:40.000 --> 00:01:45.000] You're not alone. Our entire nation grieves with you,
[00:01:45.000 --> 00:01:52.000] and those you love will always have the respect and gratitude of this country.
[00:01:52.000 --> 00:01:56.000] The cause in which they died will continue.
[00:01:56.000 --> 00:02:04.000] Mankind is led into the darkness beyond our world by the inspiration of discovery
[00:02:04.000 --> 00:02:11.000] and the longing to understand. Our journey into space will go on.
[00:02:11.000 --> 00:02:16.000] In the skies today, we saw destruction and tragedy.
[00:02:16.000 --> 00:02:22.000] Yet farther than we can see, there is comfort and hope.
[00:02:22.000 --> 00:02:29.000] In the words of the prophet Isaiah, "Lift your eyes and look to the heavens
[00:02:29.000 --> 00:02:35.000] who created all these. He who brings out the starry hosts one by one
[00:02:35.000 --> 00:02:39.000] and calls them each by name."
[00:02:39.000 --> 00:02:46.000] Because of His great power and mighty strength, not one of them is missing.
[00:02:46.000 --> 00:02:55.000] The same Creator who names the stars also knows the names of the seven souls we mourn today.
[00:02:55.000 --> 00:03:01.000] The crew of the shuttle Columbia did not return safely to earth,
[00:03:01.000 --> 00:03:05.000] yet we can pray that all are safely home.
[00:03:05.000 --> 00:03:13.000] May God bless the grieving families, and may God continue to bless America.
[00:03:13.000 --> 00:03:19.000] [Silence]
whisper_print_timings: fallbacks = 1 p / 0 h
whisper_print_timings: load time = 569.03 ms
whisper_print_timings: mel time = 146.85 ms
whisper_print_timings: sample time = 238.66 ms / 553 runs ( 0.43 ms per run)
whisper_print_timings: encode time = 18665.10 ms / 9 runs ( 2073.90 ms per run)
whisper_print_timings: decode time = 13090.93 ms / 549 runs ( 23.85 ms per run)
whisper_print_timings: total time = 32733.52 ms
Ini adalah contoh naif dalam melakukan inferensi real-time pada audio dari mikrofon Anda. Alat aliran mengambil sampel audio setiap setengah detik dan menjalankan transkripsi secara terus menerus. Info lebih lanjut tersedia dalam edisi #10.
make stream -j
./stream -m ./models/ggml-base.en.bin -t 8 --step 500 --length 5000 Menambahkan argumen --print-colors akan mencetak teks yang ditranskripsikan menggunakan strategi pengkodean warna eksperimental untuk menyoroti kata-kata dengan kepercayaan tinggi atau rendah:
./main -m models/ggml-base.en.bin -f samples/gb0.wav --print-colors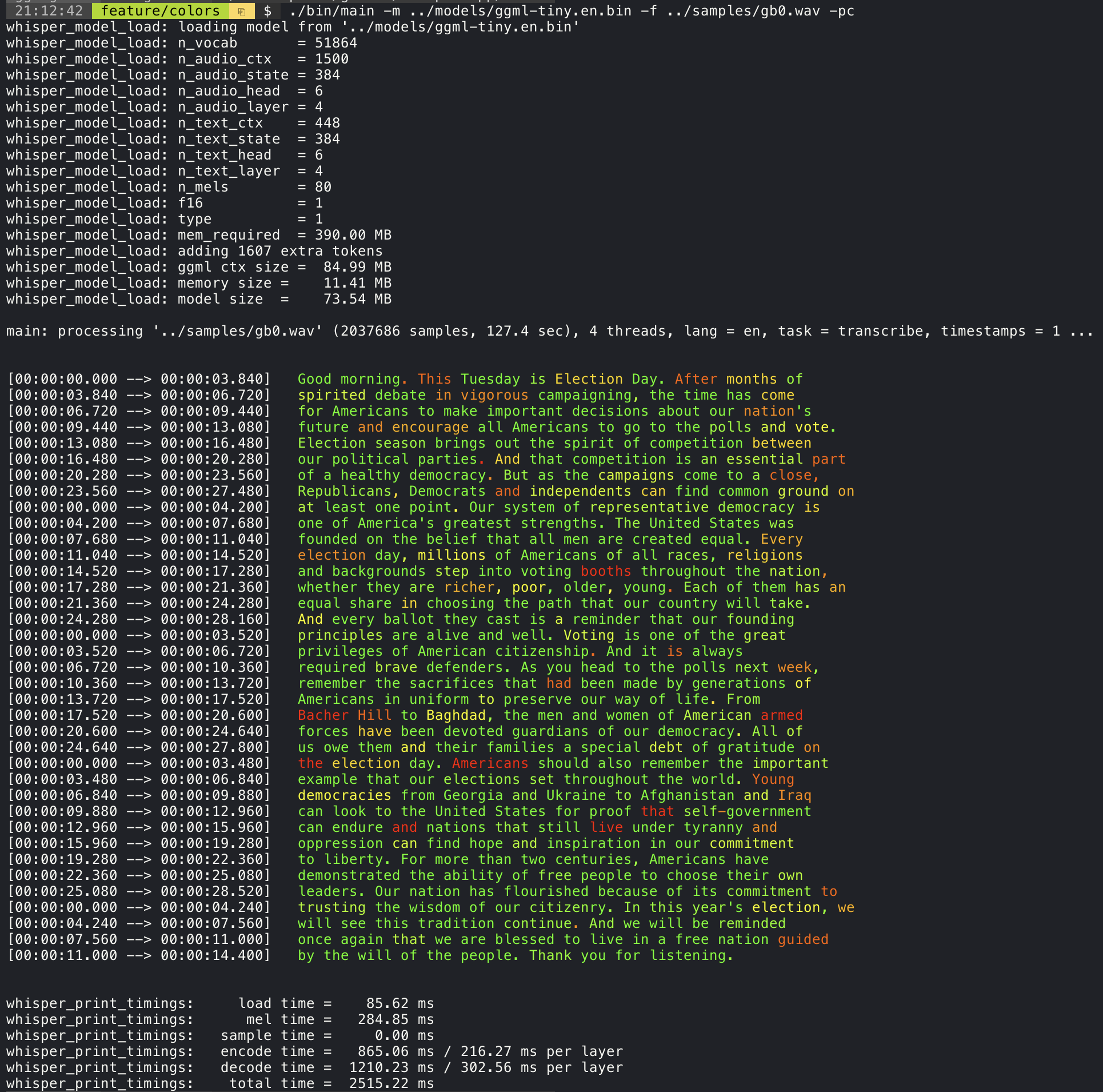
Misalnya, untuk membatasi panjang garis hingga maksimal 16 karakter, cukup tambahkan -ml 16 :
$ ./main -m ./models/ggml-base.en.bin -f ./samples/jfk.wav -ml 16
whisper_model_load: loading model from './models/ggml-base.en.bin'
...
system_info: n_threads = 4 / 10 | AVX2 = 0 | AVX512 = 0 | NEON = 1 | FP16_VA = 1 | WASM_SIMD = 0 | BLAS = 1 |
main: processing './samples/jfk.wav' (176000 samples, 11.0 sec), 4 threads, 1 processors, lang = en, task = transcribe, timestamps = 1 ...
[00:00:00.000 --> 00:00:00.850] And so my
[00:00:00.850 --> 00:00:01.590] fellow
[00:00:01.590 --> 00:00:04.140] Americans, ask
[00:00:04.140 --> 00:00:05.660] not what your
[00:00:05.660 --> 00:00:06.840] country can do
[00:00:06.840 --> 00:00:08.430] for you, ask
[00:00:08.430 --> 00:00:09.440] what you can do
[00:00:09.440 --> 00:00:10.020] for your
[00:00:10.020 --> 00:00:11.000] country.
Argumen --max-len dapat digunakan untuk mendapatkan cap waktu tingkat kata. Cukup gunakan -ml 1 :
$ ./main -m ./models/ggml-base.en.bin -f ./samples/jfk.wav -ml 1
whisper_model_load: loading model from './models/ggml-base.en.bin'
...
system_info: n_threads = 4 / 10 | AVX2 = 0 | AVX512 = 0 | NEON = 1 | FP16_VA = 1 | WASM_SIMD = 0 | BLAS = 1 |
main: processing './samples/jfk.wav' (176000 samples, 11.0 sec), 4 threads, 1 processors, lang = en, task = transcribe, timestamps = 1 ...
[00:00:00.000 --> 00:00:00.320]
[00:00:00.320 --> 00:00:00.370] And
[00:00:00.370 --> 00:00:00.690] so
[00:00:00.690 --> 00:00:00.850] my
[00:00:00.850 --> 00:00:01.590] fellow
[00:00:01.590 --> 00:00:02.850] Americans
[00:00:02.850 --> 00:00:03.300] ,
[00:00:03.300 --> 00:00:04.140] ask
[00:00:04.140 --> 00:00:04.990] not
[00:00:04.990 --> 00:00:05.410] what
[00:00:05.410 --> 00:00:05.660] your
[00:00:05.660 --> 00:00:06.260] country
[00:00:06.260 --> 00:00:06.600] can
[00:00:06.600 --> 00:00:06.840] do
[00:00:06.840 --> 00:00:07.010] for
[00:00:07.010 --> 00:00:08.170] you
[00:00:08.170 --> 00:00:08.190] ,
[00:00:08.190 --> 00:00:08.430] ask
[00:00:08.430 --> 00:00:08.910] what
[00:00:08.910 --> 00:00:09.040] you
[00:00:09.040 --> 00:00:09.320] can
[00:00:09.320 --> 00:00:09.440] do
[00:00:09.440 --> 00:00:09.760] for
[00:00:09.760 --> 00:00:10.020] your
[00:00:10.020 --> 00:00:10.510] country
[00:00:10.510 --> 00:00:11.000] .
Informasi lebih lanjut tentang pendekatan ini tersedia di sini: #1058
Penggunaan Sampel:
# download a tinydiarize compatible model
. / models / download - ggml - model . sh small . en - tdrz
# run as usual, adding the "-tdrz" command-line argument
. / main - f . / samples / a13 . wav - m . / models / ggml - small . en - tdrz . bin - tdrz
...
main : processing './samples/a13.wav' ( 480000 samples , 30.0 sec ), 4 threads , 1 processors , lang = en , task = transcribe , tdrz = 1 , timestamps = 1 ...
...
[ 00 : 00 : 00.000 - - > 00 : 00 : 03.800 ] Okay Houston , we ' ve had a problem here . [ SPEAKER_TURN ]
[ 00 : 00 : 03.800 - - > 00 : 00 : 06.200 ] This is Houston . Say again please . [ SPEAKER_TURN ]
[ 00 : 00 : 06.200 - - > 00 : 00 : 08.260 ] Uh Houston we ' ve had a problem .
[ 00 : 00 : 08.260 - - > 00 : 00 : 11.320 ] We ' ve had a main beam up on a volt . [ SPEAKER_TURN ]
[ 00 : 00 : 11.320 - - > 00 : 00 : 13.820 ] Roger main beam interval . [ SPEAKER_TURN ]
[ 00 : 00 : 13.820 - - > 00 : 00 : 15.100 ] Uh uh [ SPEAKER_TURN ]
[ 00 : 00 : 15.100 - - > 00 : 00 : 18.020 ] So okay stand , by thirteen we ' re looking at it . [ SPEAKER_TURN ]
[ 00 : 00 : 18.020 - - > 00 : 00 : 25.740 ] Okay uh right now uh Houston the uh voltage is uh is looking good um .
[ 00 : 00 : 27.620 - - > 00 : 00 : 29.940 ] And we had a a pretty large bank or so . Contoh utama memberikan dukungan untuk output film gaya karaoke, di mana kata yang saat ini diucapkan disorot. Gunakan argumen -wts dan jalankan skrip bash yang dihasilkan. Ini perlu menginstal ffmpeg .
Berikut adalah beberapa contoh "khas" :
./main -m ./models/ggml-base.en.bin -f ./samples/jfk.wav -owts
source ./samples/jfk.wav.wts
ffplay ./samples/jfk.wav.mp4./main -m ./models/ggml-base.en.bin -f ./samples/mm0.wav -owts
source ./samples/mm0.wav.wts
ffplay ./samples/mm0.wav.mp4./main -m ./models/ggml-base.en.bin -f ./samples/gb0.wav -owts
source ./samples/gb0.wav.wts
ffplay ./samples/gb0.wav.mp4Gunakan skrip skrip/bench-wtss.sh untuk menghasilkan video dalam format berikut:
./scripts/bench-wts.sh samples/jfk.wav
ffplay ./samples/jfk.wav.all.mp4Untuk memiliki perbandingan obyektif dari kinerja inferensi di berbagai konfigurasi sistem, gunakan alat Bench. Alat ini hanya menjalankan bagian enkoder dari model dan mencetak berapa banyak waktu yang dibutuhkan untuk mengeksekusinya. Hasilnya dirangkum dalam masalah gitub berikut:
Hasil benchmark
Selain itu, skrip untuk menjalankan Whisper.cpp dengan model dan file audio yang berbeda disediakan bench.py.
Anda dapat menjalankannya dengan perintah berikut, secara default akan berjalan melawan model standar apa pun di folder model.
python3 scripts/bench.py -f samples/jfk.wav -t 2,4,8 -p 1,2Ini ditulis dalam Python dengan maksud mudah dimodifikasi dan memperpanjang untuk kasus penggunaan benchmarking Anda.
Ini menghasilkan file CSV dengan hasil pembandingan.
ggmlModel asli dikonversi ke format biner khusus. Ini memungkinkan untuk mengemas segala yang dibutuhkan ke dalam satu file:
Anda dapat mengunduh model yang dikonversi menggunakan skrip model/unduh-ggml-model.sh atau secara manual dari sini:
Untuk detail lebih lanjut, lihat model skrip konversi/convert-pt-to-ggml.py atau model/readme.md.
Ada berbagai contoh menggunakan perpustakaan untuk berbagai proyek di folder contoh. Beberapa contoh bahkan diangkut untuk dijalankan di browser menggunakan WebAssembly. Lihatlah!
| Contoh | Web | Keterangan |
|---|---|---|
| utama | Whisper.wasm | Alat untuk menerjemahkan dan menyalin audio menggunakan Whisper |
| bangku | Bench.wasm | Benchmark kinerja Whisper di mesin Anda |
| sungai kecil | stream.wasm | Transkripsi real-time penangkapan mikrofon mentah |
| memerintah | command.wasm | Contoh asisten suara dasar untuk menerima perintah suara dari mikrofon |
| wchess | wchess.wasm | Catur yang dikendalikan oleh suara |
| bicara | bicara.wasm | Bicaralah dengan bot GPT-2 |
| Talk-llama | Berbicara dengan bot llama | |
| Whisper.objc | aplikasi seluler iOS menggunakan whisper.cpp | |
| Whisper.swiftUi | Aplikasi SwiftUi IOS / MacOS menggunakan Whisper.cpp | |
| Whisper.android | Aplikasi Seluler Android Menggunakan Whisper.cpp | |
| Whisper.nvim | Plugin ucapan-ke-teks untuk neovim | |
| menghasilkan-karaoke.sh | Script Pembantu Untuk dengan mudah menghasilkan video karaoke dari Capture Audio Raw | |
| livestream.sh | Transkripsi audio langsung | |
| yt-wsp.sh | Unduh + Transcribe dan/atau Terjemahkan VOD (Asli) | |
| server | Server transkripsi http dengan API seperti OAI |
Jika Anda memiliki umpan balik apa pun tentang proyek ini, jangan ragu untuk menggunakan bagian diskusi dan buka topik baru. Anda dapat menggunakan kategori pertunjukan dan memberi tahu untuk membagikan proyek Anda sendiri yang menggunakan whisper.cpp . Jika Anda memiliki pertanyaan, pastikan untuk memeriksa diskusi pertanyaan yang sering diajukan (#126).


