Koleksi yang luar biasa untuk LLM dalam bahasa Cina
Kumpulkan dan sortir LLM Cina terkait
Karena penampilan Model Bahasa Besar (LLM) yang diwakili oleh ChatGPT, karena kemampuannya yang luar biasa untuk Kecerdasan Buatan Universal (AGI) yang luar biasa, ia telah memicu gelombang penelitian dan aplikasi di bidang pemrosesan bahasa alami. Terutama setelah open source LLM skala kecil yang dapat berjalan dengan ChatGLM, LLAMA dan pemain sipil lainnya dapat dijalankan, ada banyak kasus aplikasi minimal yang disesuaikan dengan minimal LLM atau berdasarkan LLM. Proyek ini bertujuan untuk mengumpulkan dan memilah model open source, aplikasi, set data, dan tutorial yang terkait dengan LLM Cina.
Jika proyek ini dapat membantu Anda sedikit, tolong izinkan saya sedikit ~
Pada saat yang sama, Anda juga dipersilakan untuk berkontribusi pada model open source yang tidak populer, aplikasi, set data, dll. Dari proyek ini. Berikan informasi gudang baru, silakan mulai PR, dan berikan informasi terkait seperti tautan gudang, jumlah bintang, profil, pengarahan dan informasi terkait lainnya sesuai dengan format proyek ini
Ikhtisar Detail Model Basis Umum:
Basis
Sertakan model
Ukuran parameter model
Nomor token jejak
Pelatihan maksimal
Apakah akan mengkomersialkan
Chatglm
ChatGLM/2/3/4 Basis & Obrolan
6b
1t/1.4
2K/32K
Penggunaan komersial
Llama
Llama/2/3 basis & obrolan
7b/8b/13b/33b/70b
1t/2t
2K/4K
Sebagian dikomersialkan
Baichuan
BAICHUAN/2 BASE & CHAT
7b/13b
1.2t/1.4t
4K
Penggunaan komersial
Qwen
Qwen/1.5/2/2.5 Base & Chat & VL
7b/14b/32b/72b/110b
2.2t/3t/18t
8K/32K
Penggunaan komersial
Bunga
Bunga
1b/7b/176b-mt
1.5t
2k
Penggunaan komersial
Aquila
Aquila/2 Base/Chat
7b/34b
-
2k
Penggunaan komersial
Internet
Internet
7b/20b
-
200k
Penggunaan komersial
Mixtrac
Pangkalan & obrolan
8x7b
-
32k
Penggunaan komersial
Yi
Pangkalan & obrolan
6b/9b/34b
3t
200k
Penggunaan komersial
Deepseek
Pangkalan & obrolan
1.3b/7b/33b/67b
-
4K
Penggunaan komersial
Xverse
Pangkalan & obrolan
7b/13b/65b/a4.2b
2.6t/3.2t
8K/16K/256K
Penggunaan komersial
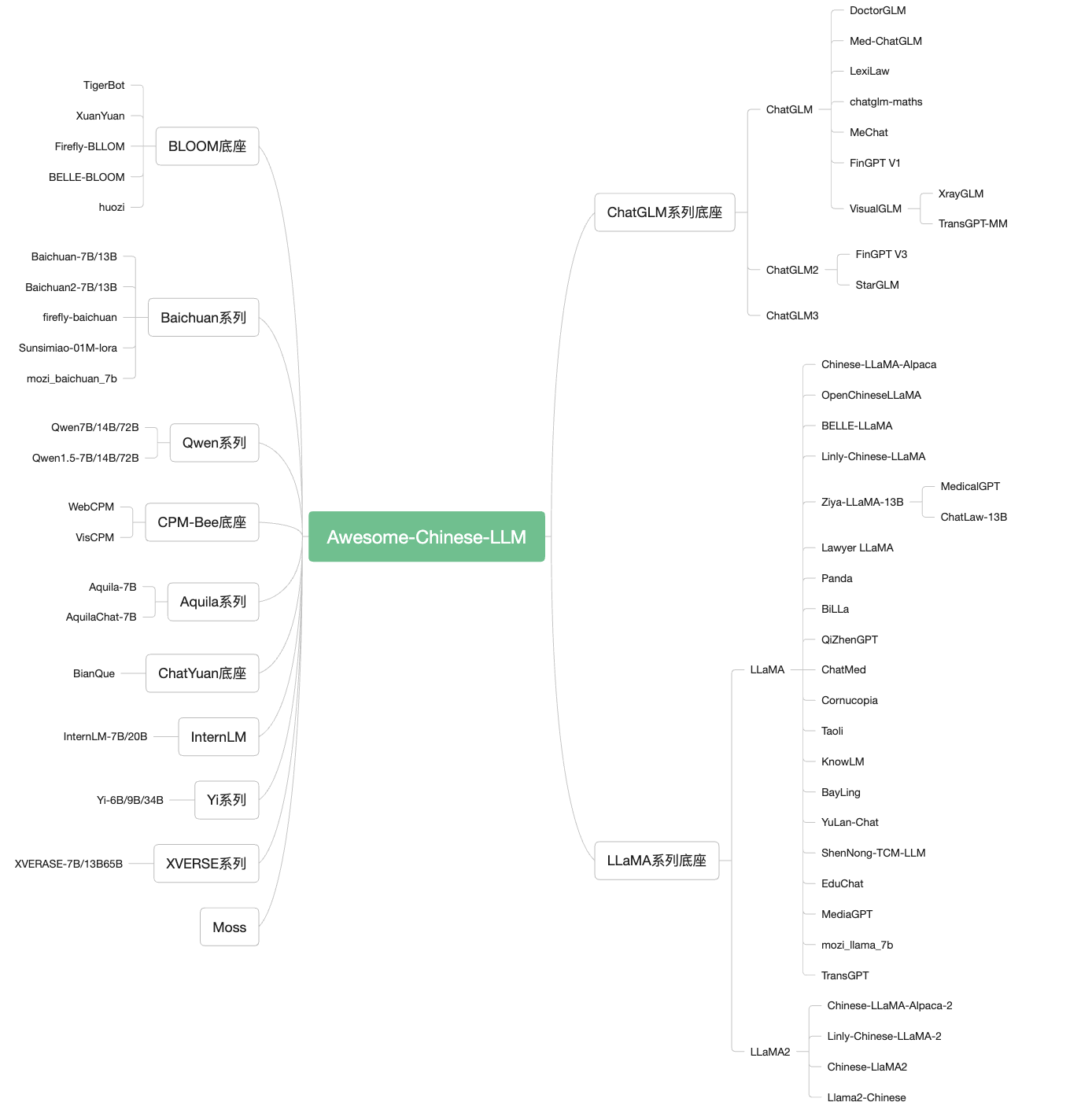
Daftar isi
Daftar isi
1. Model
1.1 Model teks LLM
1.2 Model LLM multi -keluarga
2. Aplikasi
2.1 Penyaringan di bidang vertikal
Perawatan Medis
hukum
keuangan
mendidik
Sains dan Teknologi
E -Commerce
Keamanan Jaringan
pertanian
2.2 Aplikasi Langchain
2.3 Aplikasi Lainnya
3. Kumpulan data
Kumpulan data pra -pelatihan
Kumpulan data SFT
Kumpulan data preferensi
4. LLM Pelatihan Fine -uning Framework
5. Kerangka kerja penempatan penempatan llm
6. Evaluasi LLM
7. Tutorial LLM
Pengetahuan Dasar LLM
Minta Tutorial Teknik
Tutorial Aplikasi LLM
LLM Tutorial Combat Aktual
8. Gudang Terkait
Sejarah Bintang
1. Model
1.1 Model teks LLM
Chatglm:
Alamat: https://github.com/thudm/chatglm-6b
PENDAHULUAN: Salah satu model basis open source paling efektif di bidang Cina, mengoptimalkan tanya jawab dan dialog T&J Cina. Setelah pelatihan dwibahasa sekitar 1T pengidentifikasi, ditambah dengan teknologi seperti mengawasi tuning, umpan balik, dan umpan balik dari umpan balik manusia untuk memperkuat pembelajaran
Chatglm2-6b
Alamat: https://github.com/thudm/chatglm2-6b
PENDAHULUAN: Berdasarkan versi generasi kedua dari model dialog China dan Inggris Open ChatGLM-6B, telah memperkenalkan fungsi target hibrida GLM berdasarkan dialog model yang diawetkan dan ambang batas penyebaran yang rendah, yang telah dipertahankan -Praining dari simbol identifikasi Inggris di T dan penyelarasan preferensi manusia; penggunaan komersial.
Chatglm3-6b
Alamat: https://github.com/thudm/chatglm3
Pendahuluan: ChatGLM3-6B adalah model open source dalam seri ChatGLM3. : ChatGLM3- 6B's Basic Model ChatGLM3-6B-BASE menggunakan lebih banyak data pelatihan, lebih banyak langkah pelatihan penuh, dan strategi pelatihan yang lebih masuk akal;同时原生支持工具调用( Panggilan Fungsi )、代码执行( Interpreter Kode )和 Agen 任务等复杂场景;更全面的开源序列 : 除了对话模型 chatglm3-6b 外 , 还开源了基础模型 chatglm3-6b-base 、长文本Model dialog chatglm3-6b-32k. Bobot di atas sepenuhnya terbuka untuk penelitian akademik, dan penggunaan komersial gratis juga diizinkan setelah mengisi kuesioner.
GLM-4
Alamat: https://github.com/thudm/glm-4
Pendahuluan Singkat: GLM-4-9B adalah versi open source dari model pra-pelatihan generasi terbaru yang diluncurkan oleh Smart Spectrum AI. Dalam penilaian set data seperti semantik, matematika, penalaran, kode, dan pengetahuan, GLM-4-9B dan versi preferensi manusianya dari GLM-4-9B-CHAT semuanya menunjukkan kinerja yang sangat baik di luar esensi Llama-3-8b Essence Selain beberapa putaran dialog, GLM-4-9B-CHAT juga memiliki fungsi canggih seperti penjelajahan web, eksekusi kode, panggilan alat khusus (panggilan fungsi) dan penalaran teks panjang (dukungan untuk konteks maksimum 128k). Generasi ini telah menambahkan dukungan multi -bahasa, mendukung 26 bahasa termasuk Jepang, Korea, dan Jerman. Kami juga meluncurkan model GLM-4-9B-CHAT-1M yang mendukung panjang kontekstual 1M (sekitar 2 juta karakter Cina) dan model multi-mode GLM-4V-9B berdasarkan GLM-4-9B. GLM-4V-9B memiliki kemampuan dialog multibahasa multibahasa multibahasa di bawah resolusi tinggi 1120 * 1120. Dalam banyak aspek evaluasi multi-modal seperti kemampuan komprehensif Cina dan Inggris yang komprehensif, penalaran persepsi, pengenalan teks, pemahaman bagan, GLM-4V -9b mengekspresikan kinerja yang sangat baik dari melampaui GPT-4-turbo-2024-04-09, Gemini 1.0 Pro, Qwen-VL-Max, dan Claude 3 Opus.
QWEN/QWEN1.5/QWEN2/QWEN2.5
Alamat: https://github.com/qwenlm
Pendahuluan: Tongyi Qianwen adalah serangkaian model model Tongyi Qianwen yang dikembangkan oleh Alibaba Cloud, termasuk skala parameter 1,8 miliar (1,8b), 7 miliar (7b), 14 miliar (14B), 72 miliar (72B), 1100 dan dan 1100 100 juta (110b). Model dari setiap skala termasuk model dasar QWEN dan model dialog. Set data mencakup berbagai jenis data seperti teks dan kode. Secara efektif hubungi plug -in dan tingkatkan ke Essence Agen
PENDAHULUAN: Teknologi Shangtang, Laboratorium Shanghai AI dan Universitas Cina Hong Kong, Universitas Fudan, dan Universitas Shanghai Jiaotong merilis 100 miliar parameter tingkat model bahasa besar "beasiswa". Dilaporkan bahwa "Scholar PU" memiliki 104 miliar parameter, dan dilatih berdasarkan "set data berkualitas tinggi multi -bahasa yang mengandung 1,6 triliun token".
Internet
Alamat: https://github.com/internlm/internlm
PENDAHULUAN: Teknologi Shangtang, Laboratorium Shanghai AI dan Universitas Cina Hong Kong, Universitas Fudan, dan Universitas Shanghai Jiaotong merilis 100 miliar parameter tingkat model bahasa besar "Internlm2". Internlm2 telah membuat kemajuan besar dalam digital, kode, dialog, dan penciptaan, dan kinerja komprehensif telah mencapai tingkat terkemuka model open source. Internlm2 berisi dua model: 7b dan 20b. 7B memberikan model yang ringan namun unik untuk penelitian dan aplikasi ringan.
PENDAHULUAN: Model bahasa pra -pelatihan skala besar yang dikembangkan oleh Baichuan Intelligent Development. Berdasarkan struktur transformator, model parameter 7 miliar yang dilatih pada sekitar 1,2 triliun token mendukung bilingual bahasa Cina dan Inggris, dan panjang jendela konteks adalah 4096. Benchmark otoritas Cina dan Inggris standar (C-eval/MMLU) memiliki efek terbaik dengan ukuran yang sama.
Pendahuluan: Baichuan-13b adalah model bahasa skala besar yang berisi 13 miliar parameter setelah Baichuan-7b setelah Baichuan-7b. Proyek ini menerbitkan dua versi: Baichuan-13b-base dan Baichuan-13b-CHAT.
Baichuan2
Alamat: https://github.com/baichuan-inc/baichuan2
PENDAHULUAN: Generasi baru model bahasa besar open source yang diluncurkan oleh Baichuan Intelligence menggunakan 2,6 triliun token untuk berlatih dengan corpus berkualitas tinggi. .
Xverse-7b
Alamat: https://github.com/xverse- ai/xverse-7b
PENDAHULUAN: Model bahasa besar yang didukung oleh teknologi Shenzhen Yuanxiang mendukung model multi -bahasa, mendukung panjang konteks 8K, dan menggunakan data berkualitas tinggi dan beragam dari 2,6 triliun token untuk melatih model. Rusia, dan Barat. Ini juga mencakup model versi kuantitatif GGUF dan GPTQ, yang mendukung penalaran pada llama.cpp dan VLLM pada sistem MacOS/Linux/Windows.
Xverse-13b
Alamat: https://github.com/xverse- ai/xverse-13b
PENDAHULUAN: Model bahasa besar yang didukung oleh teknologi Shenzhen Yuanxiang yang mendukung model multi -bahasa, mendukung panjang konteks 8K (panjang konteks), dan menggunakan data berkualitas tinggi dan beragam seperti 3,2 triliun token untuk melatih sepenuhnya model. sebagai Inggris, Rusia, dan Barat. Termasuk model dialog urutan panjang XVerse-13b-256K. Ini juga mencakup model versi kuantitatif GGUF dan GPTQ, yang mendukung penalaran pada llama.cpp dan VLLM pada sistem MacOS/Linux/Windows.
Xverse-65b
Alamat: https://github.com/xverse- ai/xverse-65b
Pendahuluan: Model bahasa besar yang didukung oleh teknologi Shenzhen Yuanxiang mendukung model multi -bahasa, mendukung panjang konteks 16K, dan menggunakan data berkualitas tinggi dan beragam dari 2,6 triliun token untuk melatih model untuk melatih sepenuhnya model Bahasa seperti Inggris, Rusia, dan Barat. Termasuk model Xverse-65b-2 pra-pelatihan tambahan dengan pra-pelatihan tambahan. Ini juga mencakup model versi kuantitatif GGUF dan GPTQ, yang mendukung penalaran pada llama.cpp dan VLLM pada sistem MacOS/Linux/Windows.
PENDAHULUAN: Model bahasa besar, yang mendukung multi -bahasa yang dikembangkan secara independen oleh teknologi Shenzhen Yuanxiang. Mendukung lebih dari 40 bahasa seperti Cina, Inggris, Rusia, dan Barat.
SKYWORK
Alamat: https://github.com/skyworkai/skywork
Pendahuluan: Proyek ini terbuka untuk model seri Tiangong. Model basa skywork-13b spesifik, model skywork-13b-chat, model skywork-13b-math, model skywork-13b-mm, dan model versi kuantitatif dari masing-masing model untuk mendukung pengguna untuk menyebarkan dan bernalar di penyebaran kartu grafis konsumen dan dan penalaran esensi
Yi
Alamat: https://github.com/01- ai/yi
Pendahuluan Singkat: Proyek ini terbuka untuk model-model seperti Yi-6b dan Yi-34b. Dokumen dengan lebih dari 1000 halaman.
PENDAHULUAN: Model bahasa Llama & Alpaca yang besar+penyebaran CPU/GPU lokal berdasarkan Llama asli, kosa kata Cina diperluas dan data Cina digunakan untuk pelatihan pra -pelatihan sekunder.
PENDAHULUAN: Proyek ini didasarkan pada LLAMA-2 komersial untuk pengembangan kedua. -Beli beberapa putaran untuk beradaptasi dengan berbagai skenario aplikasi dan interaksi dialog multi-putaran. Pada saat yang sama, kami juga mempertimbangkan solusi adaptasi Cina yang lebih cepat: China-LaLama2-SFT-V0: Gunakan data penyesuaian instruksi China open source yang ada atau data dialog untuk secara langsung menyempurnakan LLAMA-2 (baru-baru ini akan menjadi open source).
PENDAHULUAN: Berdasarkan Llama-7b, basis model bahasa besar yang dihasilkan oleh pelatihan pra-pelatihan inkremental dataset Cina, dibandingkan dengan llama asli, model ini telah sangat meningkat dalam hal pemahaman Cina dan kemampuan menghasilkan. .
Belle:
Alamat: https://github.com/lianjiaatech/belle
PENDAHULUAN: Open Source untuk serangkaian model berdasarkan optimasi Bloomz dan Llama. Algoritma pelatihan tentang kinerja model.
Panda:
Alamat: https://github.com/dandelionllm/pandallmm
Pendahuluan: Open Source didasarkan pada llama -7b, -13b, -33b, -65b untuk model bahasa pra -pelatihan berkelanjutan di bidang Cina, dan menggunakan hampir 15 juta data untuk pra -pelatihan sekunder.
Robin (Robin):
Alamat: https://github.com/optimalscale/lmflow
PENDAHULUAN Singkat: Robin (Robin) adalah model bilingual bahasa Cina -Inggris yang dikembangkan oleh tim LMFLOW dari Universitas Sains dan Teknologi Tiongkok. Hanya model generasi kedua Robin yang diperoleh dengan data data 180 ribu yang baik -baik -baik saja, mencapai tempat pertama pada daftar huggingface. LMFLOW mendukung pengguna untuk dengan cepat melatih model yang dipersonalisasi.
PENDAHULUAN: Fengshenbang-LM (Big Model of God) adalah model besar sistem open source yang didominasi oleh Computing Cognitive Institute Idea dan Pusat Penelitian Bahasa Alami. , copywriting, kuis akal sehat, dan komputasi matematika. Selain model seri Jiangziya, proyek ini juga terbuka untuk model -model seperti seri Taiyi dan Erlang God.
Billa:
Alamat: https://github.com/neutralzz/billa
PENDAHULUAN Singkat: Proyek ini adalah sumber terbuka model Llama Bilingual Bilingual Bahasa Inggris dengan kemampuan penalaran yang ditingkatkan. Karakteristik utama dari model ini adalah: sangat meningkatkan kemampuan pemahaman Cina dari Llama, dan meminimalkan kerusakan pada kemampuan bahasa Inggris dari llama asli sebanyak mungkin; Tugas pemahaman model untuk menyelesaikan logika tugas;
LUMUT:
Alamat: https://github.com/openlmlab/moss
PENDAHULUAN: Model bahasa dialog open source bilingual Cina dan Inggris dan beberapa plugin. Pelatihan preferensi, ia memiliki instruksi dialog, pelatihan plug -dalam dan pelatihan preferensi manusia.
PENDAHULUAN: Ini mencakup serangkaian proyek sumber terbuka dari model bahasa Cina besar, yang berisi serangkaian model bahasa berdasarkan model open source yang ada (Moss, LLAMA), instruksi untuk set data fine -tune.
Linly:
Alamat: https://github.com/cvi-szu/linly
PENDAHULUAN: Menyediakan model dialog Cina Linly-Chatflow, Model Dasar China Linly-Chinese-Llama dan data pelatihannya. Model Dasar Cina didasarkan pada Llama, menggunakan pelatihan bertahap paralel Cina dan Cina dan Inggris. Proyek ini merangkum data instruksi multi-bahasa saat ini, melakukan instruksi skala besar untuk mengikuti model Cina untuk mengikuti pelatihan, dan mewujudkan model dialog linly-chatflow.
Firefly:
Alamat: https://github.com/yangjianxin1/firefly
PENDAHULUAN: Firefly adalah proyek model bahasa Cina terbuka. Sebagai Baichuan Baichuan, Ziya, Bloom, Llama, dll. Memegang lora dan model dasar untuk menggabungkan bobot, yang lebih nyaman untuk bernalar.
Chatyuan
Alamat: https://github.com/clue- ai/chatyuan
PENDAHULUAN: Serangkaian model bahasa dialog fungsional yang didukung oleh Yuanyu Intelligent, yang mendukung dialog bilingual Sino -Buthish, dioptimalkan dalam data yang baik -fine, pembelajaran yang ditingkatkan umpan balik manusia, rantai berpikir, dll.
Chatrwkv:
Alamat: https://github.com/blinkdl/chatrwkv
Pendahuluan: Open Source Serangkaian model obrolan (termasuk bahasa Inggris dan Cina) berdasarkan arsitektur RWKV, model yang diterbitkan termasuk Raven, Novel-Chneng, Novel-CH dan Novel-Chneng-Chnpro, dapat secara langsung mengobrol dan bermain puisi, novel dan lainnya kreasi. termasuk model 7b dan 14b.
CPM-BEE
Alamat: https://github.com/openbmbmb/cpm-hee
PENDAHULUAN Singkat: Penggunaan komersial open source penuh, yang diijinkan sebesar 10 miliar parameter model pangkalan Cina dan Inggris. Ini mengadopsi arsitektur regresi transformator untuk melakukan pra-pelatihan pada corpus berkualitas tinggi dalam triliun, dan memiliki kemampuan dasar yang kuat. Pengembang dan peneliti dapat beradaptasi dengan berbagai skenario berdasarkan model dasar CPM-BEE untuk membuat model aplikasi di bidang tertentu.
Tigerbot
Alamat: https://github.com/tigerresearch/tigerbot
Pendahuluan: Model Bahasa Skala Besar (LLM) dengan multi-bahasa dan multi-tugas (LLM), open source mencakup model: Tigerbot-7b, Tigerbot-7b-Base, TigerBot-180B, pelatihan dasar dan kode penalaran, 100G data pra-pelatihan, mencakup keuangan dan hukum bidang ensiklopedia dan API.
PENDAHULUAN: Diterbitkan oleh Zhiyuan Research Institute, Model Bahasa Aquila mewarisi keunggulan desain arsitektur GPT-3, Llama, dll., Mengganti sekelompok operator yang lebih efisien untuk dicapai, didesain ulang Tokenizer Bilingual Cina dan Inggris, meningkatkan paralizer bmtrain BMTRAIN Tiongkok dan Inggris, meningkatkan BMTRAIN PARALLEL BMTRAIN Tiongkok dan Inggris, meningkatkan BMTRAIN PALALLEL BMTRAIN MINA dan Bahasa Inggris, meningkatkan BMTRAIN PALALLEL BMTRAIN MINA dan Inggris, meningkatkan BMTRAIN BMTRAIN PARALLEL MADAAN DAN INGGRIS BRIAN, UPGRADED BMTRAIN PALOLEL BMTRAIN Tiongkok dan Inggris, meningkatkan BMTRAIN BMTRAIN Tiongkok dan Inggris dan Inggris Metode pelatihan, mulai dari 0 berdasarkan corpus berkualitas tinggi Cina dan Inggris. Ini juga merupakan model bahasa open source skala besar pertama yang mendukung pengetahuan bilingual Sino -Buthish, mendukung perjanjian lisensi komersial, dan memenuhi kebutuhan kepatuhan data domestik.
Aquila2
Alamat: https://github.com/flagai-open/aquila2
PENDAHULUAN: Diterbitkan oleh Zhiyuan Research Institute, Aquila2 Series, termasuk model bahasa dasar Aquila2-7B, Aquila2-34B dan Aquila2-70b-Expr, Model Dialog Aquilachat2-7B, AquilAchat2-34B dan AQUILACHAT2-70B-70B-7B-70B-70B-70B-70B-70B-70B-70B-70B-70B-70B-70 -7b-16k dan aquilachat2-34b-16.
Anima
Alamat: https://github.com/lyogavin/anima
PENDAHULUAN: Sumber terbuka model bahasa Cina 33B berbasis Qlora yang dikembangkan oleh AI Ten Technology. Berdasarkan evaluasi turnamen peringkat ELO lebih baik.
Knowlm
Alamat: https://github.com/zjunlp/knowlm
Pendahuluan: Proyek Knowlm bertujuan untuk menerbitkan kerangka kerja model besar sumber terbuka dan bobot model yang sesuai untuk membantu mengurangi masalah kekeliruan pengetahuan, termasuk kesulitan pengetahuan tentang model besar dan potensi kesalahan serta prasangka. Fase pertama dari proyek ini merilis ekstraksi berbasis Llama dari analisis intelijen model besar, menggunakan corpus Cina dan Inggris untuk lebih lanjut melatih llama (13B), dan mengoptimalkan tugas ekstraksi pengetahuan berdasarkan teknologi instruksi konversi grafik pengetahuan.
Bayling
Alamat: https://github.com/ictnlp/bayling
PENDAHULUAN: Model universal skala besar dengan peningkatan perataan bahasa silang dikembangkan oleh tim perawatan bahasa alami Institute of Computing Technology of the China Academy of Sciences. Bayling menggunakan llama sebagai model dasar, mengeksplorasi metode instruksi yang baik dengan tugas terjemahan interaktif sebagai inti. . Dalam evaluasi terjemahan multi -bahasa, terjemahan interaktif, tugas universal, dan ujian standar, Bai Ling menunjukkan kinerja yang lebih baik dalam bahasa Cina/Inggris. Bai Ling menyediakan versi demo online untuk dialami semua orang.
Yulan-chaat
Alamat: https://github.com/ruc-gsai/yulan- chat
Pendahuluan: Yulan-Chat adalah model bahasa besar yang dikembangkan oleh Renmin University of China GSAI peneliti. Ini dikembangkan dengan baik -tune berdasarkan llama dan memiliki instruksi bahasa Inggris dan Cina berkualitas tinggi. Yulan-Chat dapat mengobrol dengan pengguna, mengikuti instruksi bahasa Inggris atau Cina dengan baik, dan dapat digunakan pada GPU (A800-80G atau RTX3090) setelah kuantifikasi.
Polylm
Alamat: https://github.com/damo-nlp-mt/polylm
PENDAHULUAN Singkat: Model multi -bahasa yang dilatih dari awal 640 miliar kata, termasuk ukuran dua model (1.7b dan 13b). Polylm mencakup Cina, Inggris, Rusia, Barat, Prancis, Portugis, Jerman, Italia, HE, Bo, Bobo, Ashi, Ibrani, Jepang, Korea Selatan, Thailand, Vietnam, Indonesia dan jenis lainnya, terutama lebih ramah dengan bahasa Asia.
Huozi
Alamat: https://github.com/hitcir/huozi
PENDAHULUAN: Model bahasa pra -pelatihan skala besar dari model bahasa pra -pelatihan skala besar yang dikembangkan oleh Harbin Institute of Nature Language Treatment Research Institute. Model ini didasarkan pada model parameter 7 miliar dari struktur mekar, yang mendukung bilingual Cina dan Inggris. kumpulan data.
Yayi
Alamat: https://github.com/weenge-research/yayi
PENDAHULUAN: Model yang elegan diatur dalam data lapangan berkualitas tinggi dari bidang berkualitas tinggi dari jutaan struktur buatan. dan tata kelola kota. Dari iterasi inisialisasi pra -pelatihan pra -pelatihan, kami secara bertahap meningkatkan kemampuan dasar Cina dan kemampuan analisis lapangan, dan meningkatkan beberapa putaran dialog dan beberapa kemampuan plug -in. Pada saat yang sama, setelah ratusan pengujian internal pengguna, optimasi umpan balik buatan terus menerus telah terus meningkat, yang selanjutnya meningkatkan kinerja dan keamanan model. Open Source of China Optimization Model Berdasarkan Llama 2, mengeksplorasi praktik terbaru yang cocok untuk misi Cina di banyak bidang Cina.
Yayi2
Alamat: https://github.com/weenge-research/yayi2
Pendahuluan: Yayi 2 adalah generasi baru model bahasa besar open source yang dikembangkan oleh Zhongke Wenge, termasuk versi basis dan obrolan dengan skala parameter 30B. Yayi2-30b adalah model bahasa besar berdasarkan transformator, menggunakan korpus multi-bahasa berkualitas tinggi dan multi-bahasa lebih dari 2 triliun token untuk pra-pelatihan. Menanggapi skenario aplikasi pada bidang umum dan spesifik, kami telah menggunakan jutaan instruksi untuk melakukan fine -fine, dan pada saat yang sama, kami menggunakan umpan balik manusia untuk memperkuat metode pembelajaran untuk lebih menyelaraskan model dan nilai -nilai manusia. Model open source ini adalah model dasar yayi2-30b.
Yuan-2.0
Alamat: https://github.com/ieit-yuan/yuan-2.0
PENDAHULUAN: Proyek ini terbuka untuk generasi baru model bahasa dasar yang dirilis oleh Inspur Information. Dan menyediakan skrip yang relevan untuk layanan pra -pelatihan, baik -fine, dan penalaran. Sumber 2.0 didasarkan pada Sumber 1.0, menggunakan data pra -pelatihan berkualitas tinggi dan set data yang baik untuk membuat model memiliki pemahaman yang lebih kuat dalam semantik, matematika, penalaran, kode, dan pengetahuan.
PENDAHULUAN: Proyek ini melakukan tabel ekspansi Cina pra-pelatihan berdasarkan model ahli hibrida mixtral-8x7b. Efisiensi pengkodean Cina dari model ini secara signifikan ditingkatkan daripada model aslinya. Pada saat yang sama, melalui pelatihan pra -tambahan pada korpus open source skala besar, model ini memiliki generasi Cina yang kuat dan kemampuan pemahaman.
Bluelm
Alamat: https: //github.com/vivo-jlab/bluelm
PENDAHULUAN: Bluelm adalah model bahasa pra -pelatihan skala besar yang dikembangkan secara independen oleh Vivo AI Global Research Institute. Model (obrolan).
PENDAHULUAN: ORONSTAR-YI-34B-CHAT adalah model Yi-34b berbasis Helion Starry berdasarkan sumber terbuka 10.000 hal. Pengalaman interaktif untuk pengguna komunitas model besar.
Minicpm
Menambahkan
PENDAHULUAN: MiniCPM adalah serangkaian model sisi samping yang biasa dibuka oleh intelijen dinding mie dan laboratorium perawatan bahasa alami Universitas Tsinghua. parameter.
Mengzi3
Alamat: https://github.com/langboat/mengzi3
Pendahuluan: Model Mengzi3 8b/13b didasarkan pada arsitektur LLAMA, dengan pemilihan corpus dari halaman web, ensiklopedia, sosial, media, berita, dan set data sumber terbuka berkualitas tinggi. Dengan melanjutkan pelatihan corpus multi -bahasa pada triliun token, kemampuan model Cina luar biasa dan memperhitungkan kemampuan multi -bahasa.
1.2 Model LLM multi -keluarga
Visualglm-6b
Alamat: https://github.com/thudm/visualglm-6b
PENDAHULUAN: Sumber terbuka, model bahasa multi-mode yang mendukung gambar, Cina, dan bahasa Inggris. Mengandalkan pasangan grafis Cina berkualitas tinggi 30m dari kumpulan data Cogview, pra -pelatihan dengan grafik bahasa Inggris yang disaring dengan 300m.
COGVLM
Alamat: https://github.com/thudm/cogvlm
Pendahuluan Singkat: Model Bahasa Visual Open Source yang kuat (VLM). COGVLM-17B memiliki 10 miliar parameter visual dan 7 miliar parameter bahasa. COGVLM-17B telah mencapai kinerja SOTA dalam 10 tes benchmark lintas modular klasik. COGVLM dapat secara akurat menggambarkan gambar, dan hampir tidak ada halusinasi yang muncul.
PENDAHULUAN: Model Multi -Mode yang dikembangkan berdasarkan Proyek Model Llama & Alpaca Cina. VisualCla menambahkan modul pengkodean gambar ke model Llama/Alpaca Cina, sehingga model LLAMA dapat menerima informasi visual. Atas dasar ini, grafik Tiongkok digunakan untuk pelatihan pre -modal pada data. Instruksi mode saat ini adalah open source visualcla-7b-v0.1.
Llasm
Alamat: https://github.com/linksoul- ai/llasm
PENDAHULUAN Singkat: Model dialog open source dan komersial pertama yang mendukung dialog multi-modal Dual-Voice-Text China dan Inggris. Input suara yang nyaman akan sangat meningkatkan pengalaman model besar dengan teks sebagai input, sambil menghindari proses yang membosankan berdasarkan solusi ASR dan kemungkinan kesalahan yang dapat diperkenalkan. Saat ini open source llasm-chinese-llama-2-7b, llasm-baichuan-7b dan model dan set data lainnya.
Viscpm
Menambahkan
PENDAHULUAN: Seri open source multi-mode dan seri model besar, mendukung dialog multi-mode bilingual Cina dan Inggris (model VISCPM-CHAT) dan kemampuan teks ke grafik (model viscpm-paint). VISCPM didasarkan pada puluhan miliar parameter, pelatihan model bahasa skala besar CPM-BEE (10b), dan mengintegrasikan encoder visual (Q-former) dan decoder visual (difusi-UNET) untuk mendukung input dan output dari sinyal visual.得益于CPM-Bee基座优秀的双语能力,VisCPM可以仅通过英文多模态数据预训练,泛化实现优秀的中文多模态能力。
Introduction: The project is open to the field of Chinese long text instructions with a multi-scale psychological counseling field with a multi-round dialogue data combined instruction to fine-tune the psychological health model (Soulchat). Fully tune the full number of parameters .
Introduction: WingPT is a large model based on the GPT-based medical vertical field. Based on the Qwen-7B1 as the basic pre-training model, it has continued pre-training in this technology, instructions fine-tuning. -7B-Chat model.
简介:MemFree 是一个开源的Hybrid AI 搜索引擎,可以同时对您的个人知识库(如书签、笔记、文档等)和互联网进行搜索, 为你提供最佳答案。MemFree 支持自托管的极速无服务器向量数据库,支持自托管的极速Local Embedding and Rerank Service,支持一键部署。
Data set description: The scholar · Wanjuan 1.0 is the first open source version of the scholar · Wanjuan multi -modal language library, including three parts: text data set, graphic data set, and video data set. The total amount of data exceeds 2TB . 目前,书生·万卷1.0已被应用于书生·多模态、书生·浦语的训练。通过对高质量语料的“消化”,书生系列模型在语义理解、知识问答、视觉理解、视觉问答等各类生成式任务表现出的优异性能。
Data set description: Unified rich IFT data (such as COT data, still expands continuously), multiple training efficiency methods (such as Lora, P-Tuning), and multiple LLMS, three interfaces on three levels to create convenient researchers LLM-IFT research platform.
Data set description: Data sets are renovated with the true psychological mutual assistance QA for multiple rounds of psychological health support through ChatGPT. Dialogue themes, vocabulary and chapters are more rich and diverse, and are more in line with the application scenarios of multi -round dialog.
偏好数据集
CValues
地址:https://github.com/X-PLUG/CValues
数据集说明:该项目开源了数据规模为145k的价值对齐数据集,该数据集对于每个prompt包括了拒绝&正向建议(safe and reponsibility) > 拒绝为主(safe) > 风险回复(unsafe)三种类型,可用于增强SFT模型的安全性或用于训练reward模型。
简介:一个中文版的大模型入门教程,围绕吴恩达老师的大模型系列课程展开,主要包括:吴恩达《ChatGPT Prompt Engineering for Developers》课程中文版,吴恩达《Building Systems with the ChatGPT API》课程中文版,吴恩达《LangChain for LLM Application Development》课程中文版等。
Introduction: ChatGPT burst into fire, which has opened a key step leading to AGI. This project aims to summarize the open source calories of those ChatGPTs, including large text models, multi -mode and large models, etc., providing some convenience for everyone .
简介:This repo aims at recording open source ChatGPT, and providing an overview of how to get involved, including: base models, technologies, data, domain models, training pipelines, speed up techniques, multi-language, multi-modal, and more to go.
简介:This repo record a list of totally open alternatives to ChatGPT.
Awesome-LLM:
地址:https://github.com/Hannibal046/Awesome-LLM
简介:This repo is a curated list of papers about large language models, especially relating to ChatGPT. It also contains frameworks for LLM training, tools to deploy LLM, courses and tutorials about LLM and all publicly available LLM checkpoints and APIs.