Kembangkan REST API untuk melakukan terjemahan mesin menggunakan model SEQ2SEQ. Penyebaran model dilakukan dengan menggunakan platform Google Can.
Proyek dibuat dengan:
Data untuk proyek ini tersedia sebagai file teks pada sumber data, di mana setiap baris memiliki kalimat di Kannada dan terjemahannya dalam bahasa Inggris dengan pembatas ruang. Kami secara manual memverifikasi secara acak untuk memastikan bahwa setiap contoh masuk akal.
Pertama, kami membangun model dekoder encoder, dengan mekanisme perhatian menggunakan Gru RNN. Pelatihan dilakukan dengan menggunakan skrip Python yang tersedia di sini
Bangun aplikasi Flask yang dapat diakses dari mesin lokal di alamat http://127.0.0.1:5000/predict.
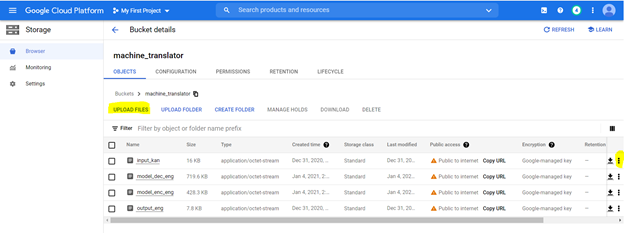
Kami akan menggunakan skrip untuk melatih model. Setelah melatih model, kami akan menyimpan bobot model dalam file .PT dan menyimpan di Google Cloud Storage. Kami juga membangun kamus kosa kata dengan mengindeks setiap kata ke angka dan acar. File acar ini juga disimpan dalam file penyimpanan. Anda dapat mengaksesnya di sini setelah file -file ini ada, penyebaran dapat dilakukan mengikuti langkah -langkah di bawah ini
Kami akan mengunggah file pada ember penyimpanan. Untuk membuat ember menggunakan opsi berikut seperti yang disorot dengan spesifikasi berikut
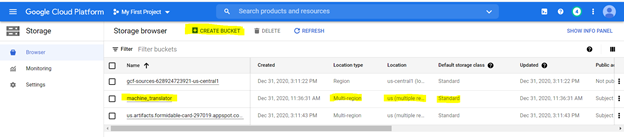
Untuk membuat fungsi cloud, telusuri untuk itu di platform GCP dan gunakan opsi yang disorot untuk membuat fungsi,
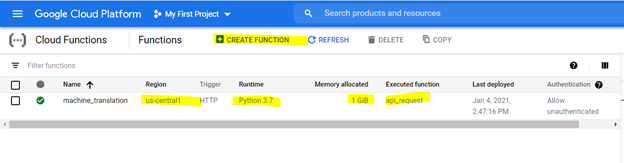
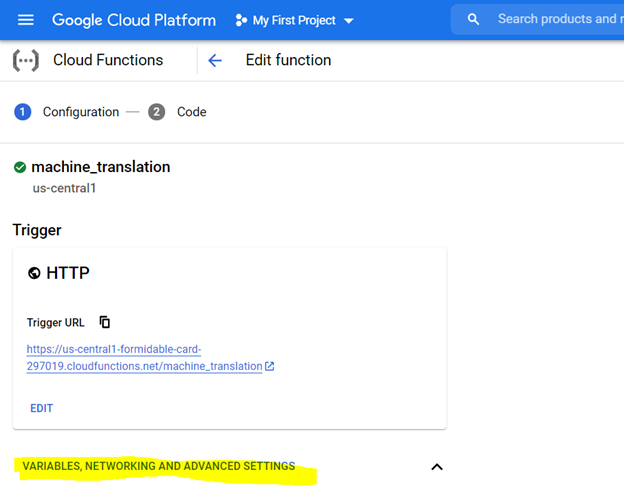
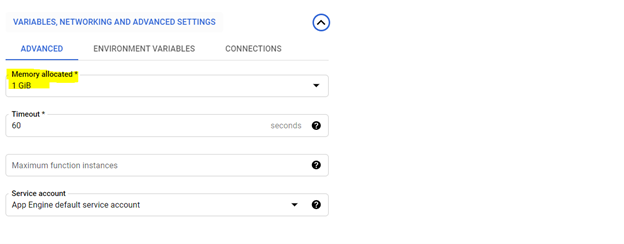
*Alokasi 1 GIB memori direkomendasikan. Setelah diatur, klik 'Next' dan sebarkan kode pada konsol fungsi cloud.
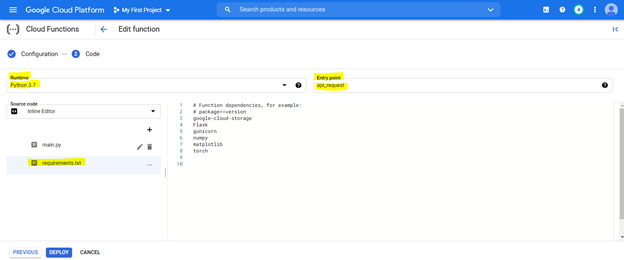
Untuk menggunakan kode, pertama -tama konfigurasikan konsol dengan pengaturan yang disorot di bawah ini dan persiapkan lingkungan menggunakan file persyaratan (ini setara dengan PIP menginstal {library}) seperti yang dijelaskan di bawah ini,
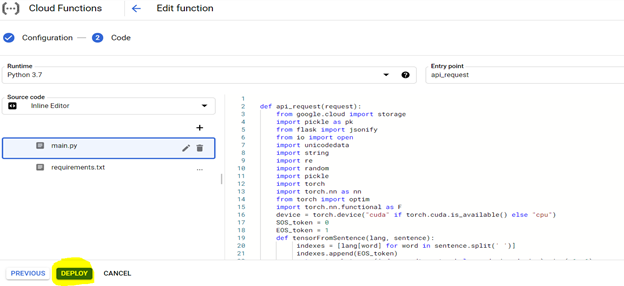

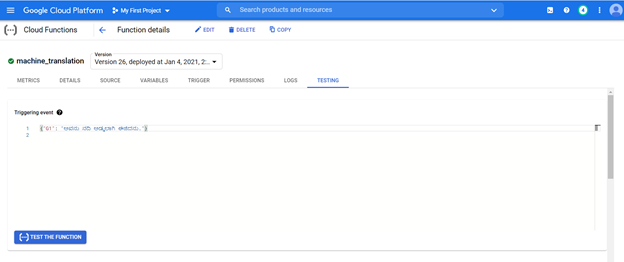

Model yang digunakan dapat diakses dari URL dari sistem apa pun untuk menerjemahkan kalimat Kannada ke bahasa Inggris.


