GroundingDINO
Grounding DINO SwinB

Ide-CVR, Ide-Research
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, Lei Zhang ? .
[ Paper ] [ Demo ] [ BibTex ]
Implementasi Pytorch dan model pretrained untuk membumikan Dino. Untuk detailnya, lihat Dino Grounding Paper: Menikah dengan Dino dengan Pra-Pelatihan Dibumi untuk Deteksi Open-Set Object .
2023/07/18 : Kami merilis Semantic-Sam, model segmentasi gambar universal untuk memungkinkan segmen dan mengenali apa pun di setiap granularitas yang diinginkan. Kode dan pos pemeriksaan tersedia!2023/06/17 : Kami memberikan contoh untuk mengevaluasi dino grounding pada kinerja coco zero-shot.2023/04/15 : Lihat CV dalam bacaan liar untuk mereka yang tertarik dengan pengakuan set terbuka!2023/04/08 : Kami melepaskan demo untuk menggabungkan dino grounding dengan gligen untuk edit gambar yang lebih terkendali.2023/04/08 : Kami melepaskan demo untuk menggabungkan dino grounding dengan difusi stabil untuk edit gambar.2023/04/06 : Kami membangun demo baru dengan menikahi grounddino dengan segmen-apa saja bernama ground-secegment-anything bertujuan untuk mendukung segmentasi di grounddino.2023/03/28 : Video YouTube tentang grounding dino dan Deteksi Dasar Deteksi Prompt Engineering. [Skalskip]2023/03/28 : Tambahkan demo pada ruang wajah memeluk!2023/03/27 : Mendukung mode CPU-only. Sekarang model dapat berjalan pada mesin tanpa GPU.2023/03/25 : Demo untuk pembumian Dino tersedia di Colab. [Skalskip]2023/03/22 : Kode tersedia sekarang! Menikah dengan Dino dan Gligen
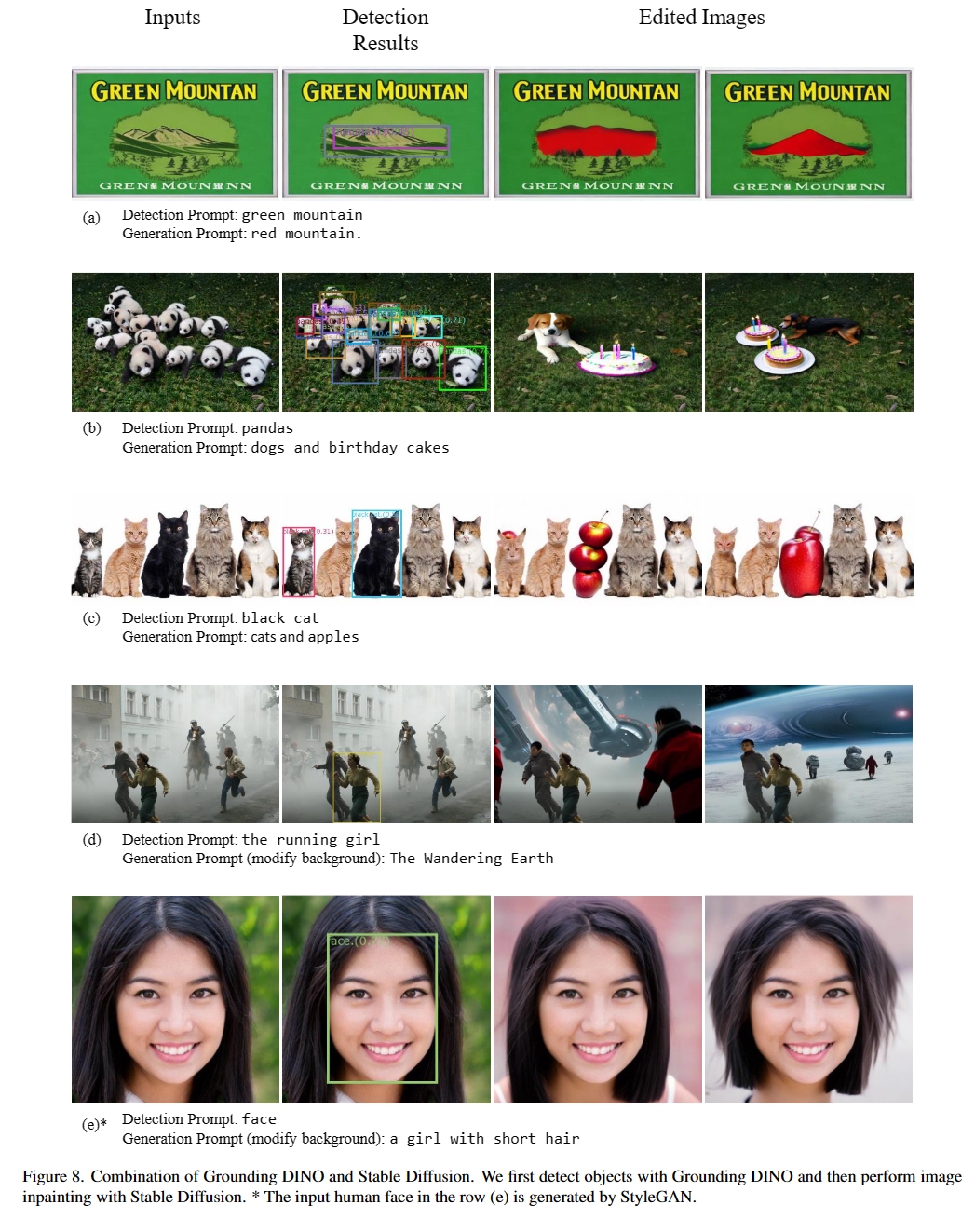
Menikah dengan Dino dan Gligen (image, text) sebagai input.900 (secara default). Setiap kotak memiliki skor kesamaan di semua kata input. (Seperti yang ditunjukkan pada gambar di bawah ini.)box_threshold .text_threshold seperti label yang diprediksi.dogs dalam kalimat two dogs with a stick. , Anda dapat memilih kotak dengan kesamaan teks tertinggi dengan dogs sebagai output akhir.. untuk dino grounding. 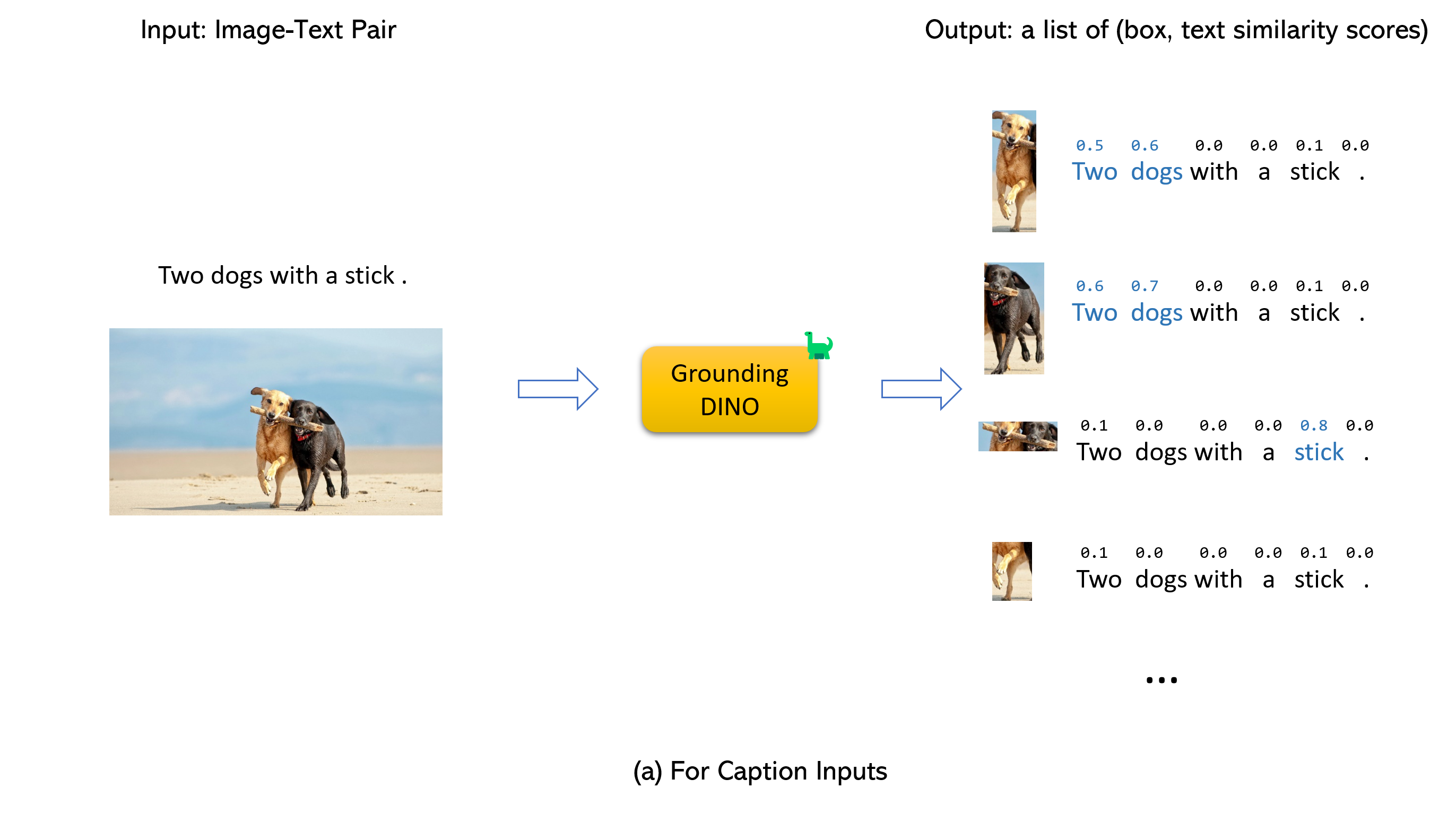
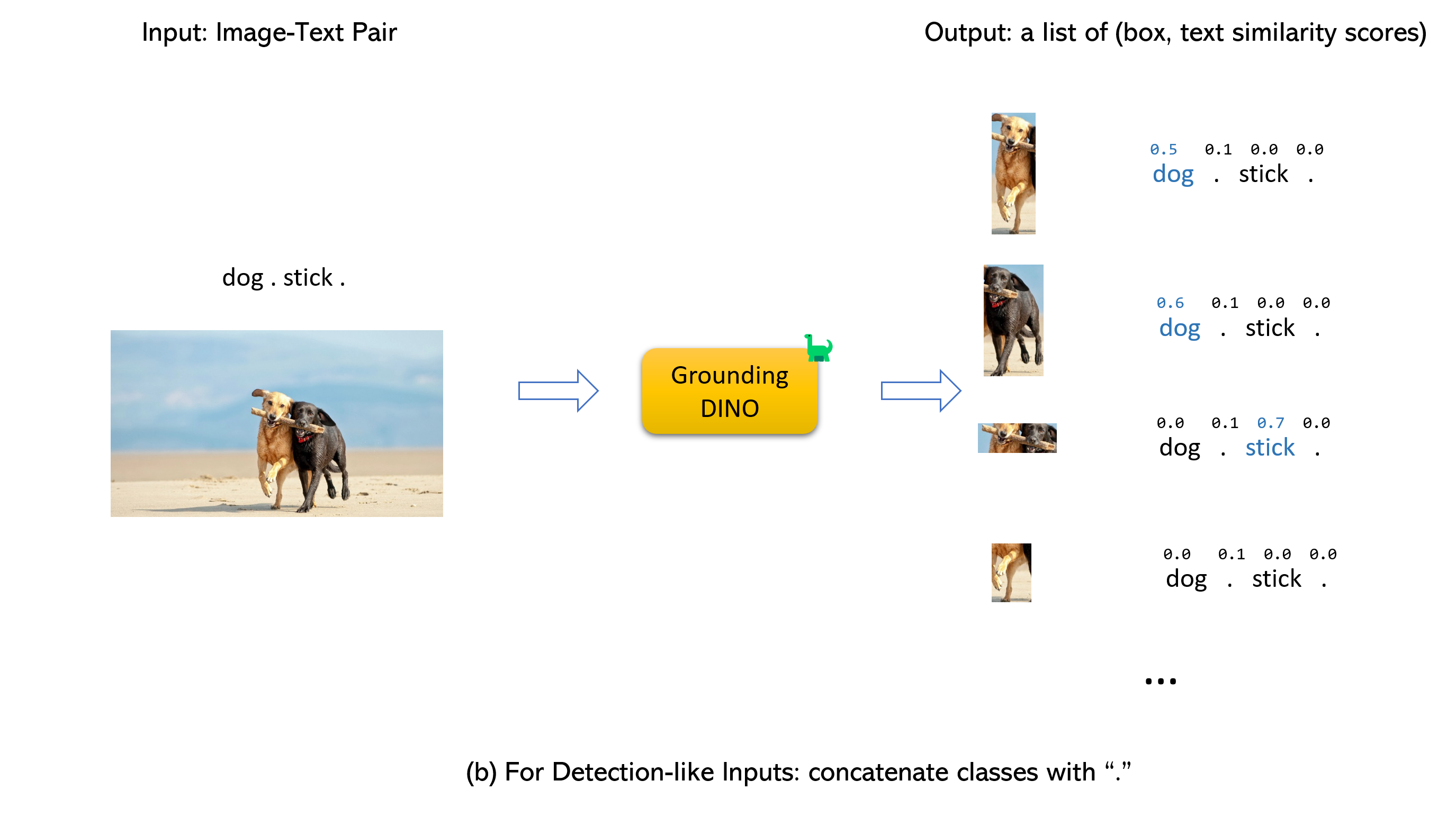
Catatan:
CUDA_HOME diatur. Ini akan dikompilasi di bawah mode CPU saja jika tidak ada CUDA yang tersedia.Harap pastikan mengikuti langkah -langkah instalasi secara ketat, jika tidak program dapat menghasilkan:
NameError: name ' _C ' is not definedJika ini terjadi, silakan menginstal ulang grounddino dengan menyulap git dan melakukan semua langkah instalasi lagi.
echo $CUDA_HOMEJika tidak mencetak apa pun, maka itu berarti Anda belum mengatur jalur/
Jalankan ini sehingga variabel lingkungan akan ditetapkan di bawah shell saat ini.
export CUDA_HOME=/path/to/cuda-11.3Perhatikan versi CUDA harus selaras dengan runtime CUDA Anda, karena mungkin ada beberapa CUDA secara bersamaan.
Jika Anda ingin mengatur cuda_home secara permanen, simpan menggunakannya:
echo ' export CUDA_HOME=/path/to/cuda ' >> ~ /.bashrcSetelah itu, sumber file Bashrc dan periksa cuda_home:
source ~ /.bashrc
echo $CUDA_HOMEDalam contoh ini, /path/to/cuda-11.3 harus diganti dengan jalur di mana toolkit CUDA Anda diinstal. Anda dapat menemukan ini dengan mengetik NVCC mana di terminal Anda:
Misalnya, jika outputnya/usr/local/cuda/bin/nvcc, maka:
export CUDA_HOME=/usr/local/cudaInstalasi:
1. Tepuk gudang grounddino dari GitHub.
git clone https://github.com/IDEA-Research/GroundingDINO.git cd GroundingDINO/pip install -e .mkdir weights
cd weights
wget -q https://github.com/IDEA-Research/GroundingDINO/releases/download/v0.1.0-alpha/groundingdino_swint_ogc.pth
cd ..Periksa ID GPU Anda (hanya jika Anda menggunakan GPU)
nvidia-smi Ganti {GPU ID} , image_you_want_to_detect.jpg , dan "dir you want to save the output" dengan nilai yang sesuai dalam perintah berikut
CUDA_VISIBLE_DEVICES={GPU ID} python demo/inference_on_a_image.py
-c groundingdino/config/GroundingDINO_SwinT_OGC.py
-p weights/groundingdino_swint_ogc.pth
-i image_you_want_to_detect.jpg
-o " dir you want to save the output "
-t " chair "
[--cpu-only] # open it for cpu modeJika Anda ingin menentukan frasa yang akan dideteksi, berikut adalah demo:
CUDA_VISIBLE_DEVICES={GPU ID} python demo/inference_on_a_image.py
-c groundingdino/config/GroundingDINO_SwinT_OGC.py
-p ./groundingdino_swint_ogc.pth
-i .asset/cat_dog.jpeg
-o logs/1111
-t " There is a cat and a dog in the image . "
--token_spans " [[[9, 10], [11, 14]], [[19, 20], [21, 24]]] "
[--cpu-only] # open it for cpu mode Token_spans menentukan posisi awal dan akhir dari suatu frasa. Misalnya, frasa pertama adalah [[9, 10], [11, 14]] . "There is a cat and a dog in the image ."[9:10] = 'a' , "There is a cat and a dog in the image ."[11:14] = 'cat' . Oleh karena itu mengacu pada frasa a cat . Demikian pula, [[19, 20], [21, 24]] mengacu pada frasa a dog .
Lihat demo/inference_on_a_image.py untuk lebih jelasnya.
Berlari dengan Python:
from groundingdino . util . inference import load_model , load_image , predict , annotate
import cv2
model = load_model ( "groundingdino/config/GroundingDINO_SwinT_OGC.py" , "weights/groundingdino_swint_ogc.pth" )
IMAGE_PATH = "weights/dog-3.jpeg"
TEXT_PROMPT = "chair . person . dog ."
BOX_TRESHOLD = 0.35
TEXT_TRESHOLD = 0.25
image_source , image = load_image ( IMAGE_PATH )
boxes , logits , phrases = predict (
model = model ,
image = image ,
caption = TEXT_PROMPT ,
box_threshold = BOX_TRESHOLD ,
text_threshold = TEXT_TRESHOLD
)
annotated_frame = annotate ( image_source = image_source , boxes = boxes , logits = logits , phrases = phrases )
cv2 . imwrite ( "annotated_image.jpg" , annotated_frame )Web UI
Kami juga menyediakan kode demo untuk mengintegrasikan Dino landasan dengan UI Web Clashio. Lihat demo/gradio_app.py untuk lebih jelasnya.
Notebook
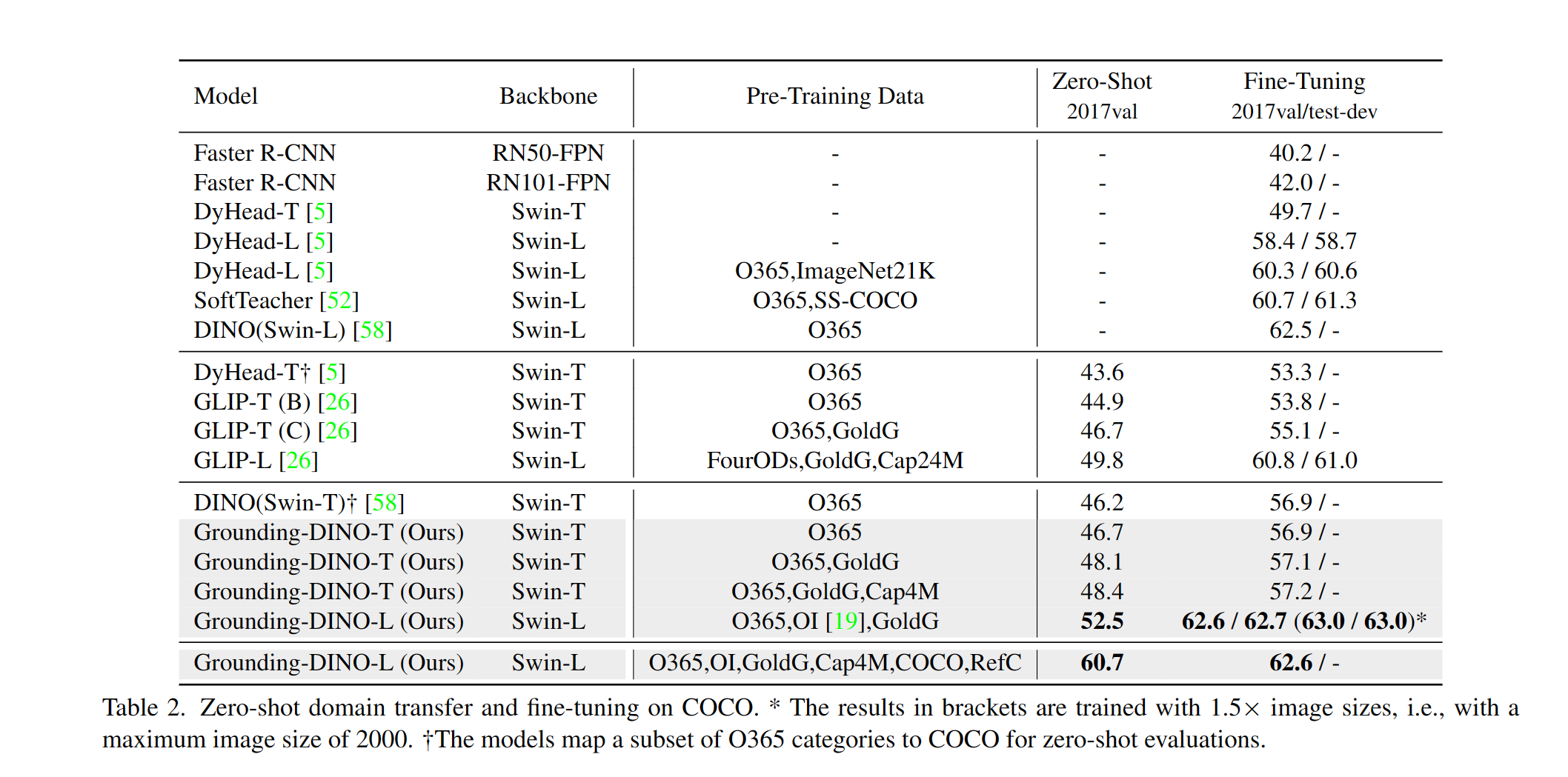
Kami memberikan contoh untuk mengevaluasi kinerja Dino Zero-shot yang membumikan di Coco. Hasilnya harus 48,5 .
CUDA_VISIBLE_DEVICES=0
python demo/test_ap_on_coco.py
-c groundingdino/config/GroundingDINO_SwinT_OGC.py
-p weights/groundingdino_swint_ogc.pth
--anno_path /path/to/annoataions/ie/instances_val2017.json
--image_dir /path/to/imagedir/ie/val2017| nama | tulang punggung | Data | kotak ap di coco | Pos pemeriksaan | Konfigurasi | |
|---|---|---|---|---|---|---|
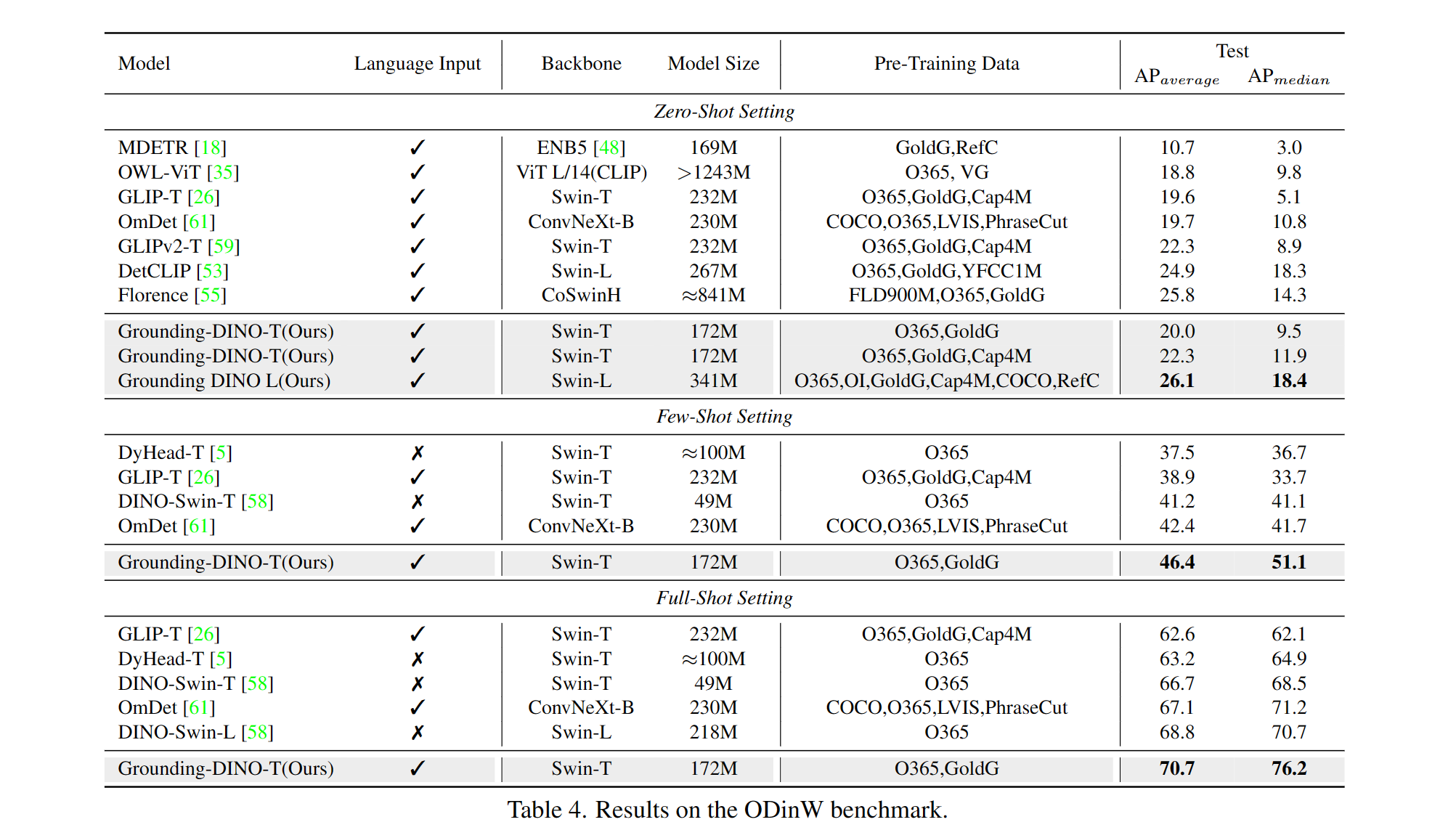
| 1 | Landingdino-t | Swin-t | O365, Goldg, Cap4m | 48.4 (Zero-shot) / 57.2 (fine-tune) | Tautan github | Tautan HF | link |
| 2 | Landingdino-b | Swin-b | Coco, O365, Goldg, Cap4m, OpenImage, Odinw-35, Refcoco | 56.7 | Tautan github | Tautan HF | link |

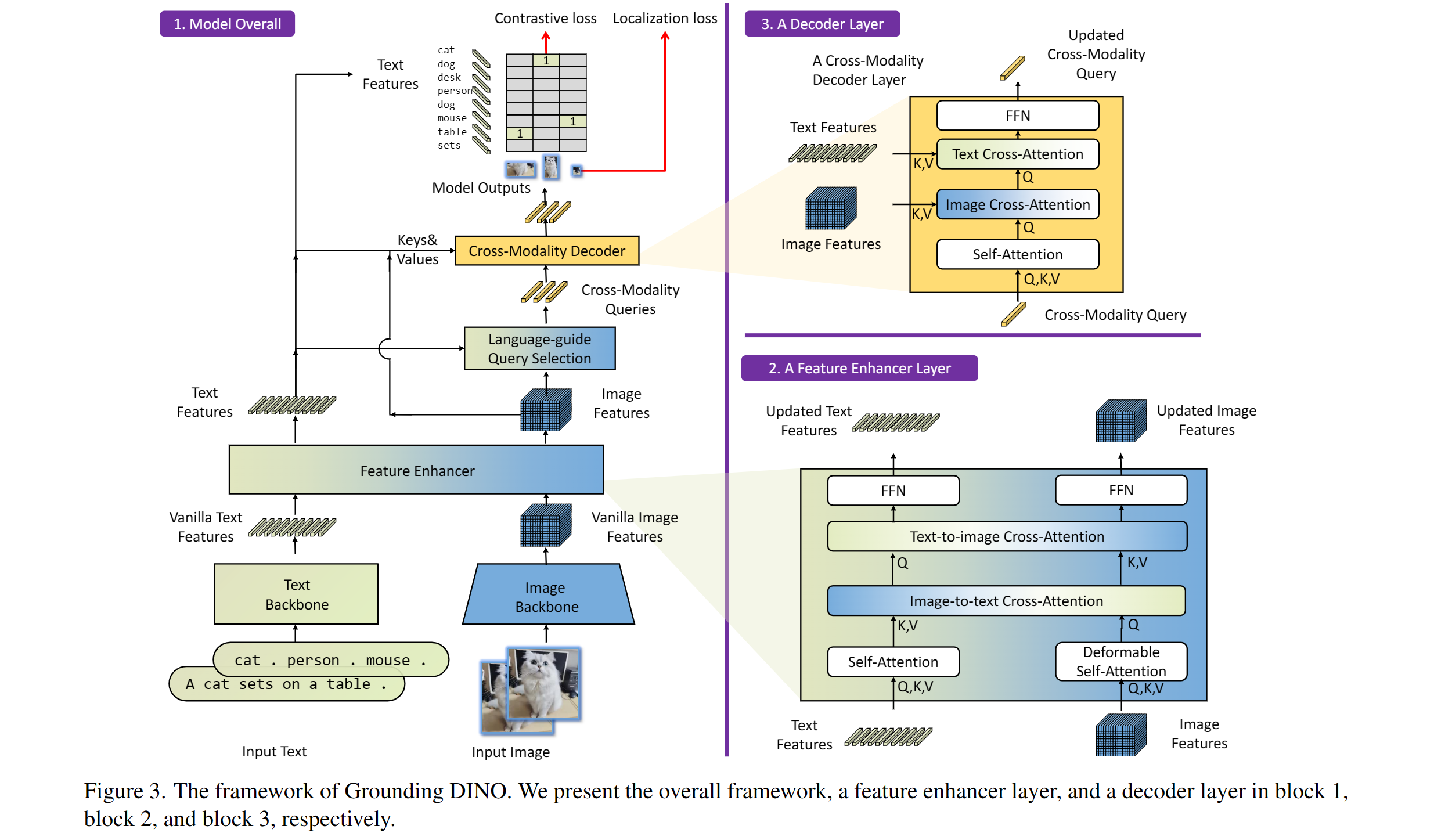
Termasuk: tulang punggung teks, tulang punggung gambar, penambah fitur, pilihan kueri yang dipandu bahasa, dan dekoder lintas-modalitas.
Model kami terkait dengan Dino dan Glip. Terima kasih atas pekerjaan hebat mereka!
Kami juga berterima kasih kepada pekerjaan yang hebat sebelumnya termasuk detr, detr yang dapat dideformasi, SMCA, detr bersyarat, anchor detr, detr dinamis, dab-det, dn-det, dll. Pekerjaan terkait lebih banyak tersedia di transformator deteksi yang luar biasa. Toolbox Detrex baru juga tersedia.
Terima kasih difusi dan gligen yang stabil untuk model mereka yang luar biasa.
Jika Anda menemukan pekerjaan kami bermanfaat untuk penelitian Anda, silakan pertimbangkan mengutip entri Bibtex berikut.
@article { liu2023grounding ,
title = { Grounding dino: Marrying dino with grounded pre-training for open-set object detection } ,
author = { Liu, Shilong and Zeng, Zhaoyang and Ren, Tianhe and Li, Feng and Zhang, Hao and Yang, Jie and Li, Chunyuan and Yang, Jianwei and Su, Hang and Zhu, Jun and others } ,
journal = { arXiv preprint arXiv:2303.05499 } ,
year = { 2023 }
}

