
Implementasi resmi GFT, model fondasi lintas tugas lintas domain pada grafik. Logo ini dihasilkan oleh Dall · E 3.
Ditulis oleh Zehong Wang, Zheyuan Zhang, Nitesh v Chawla, Chuxu Zhang, dan Yanfang Ye.
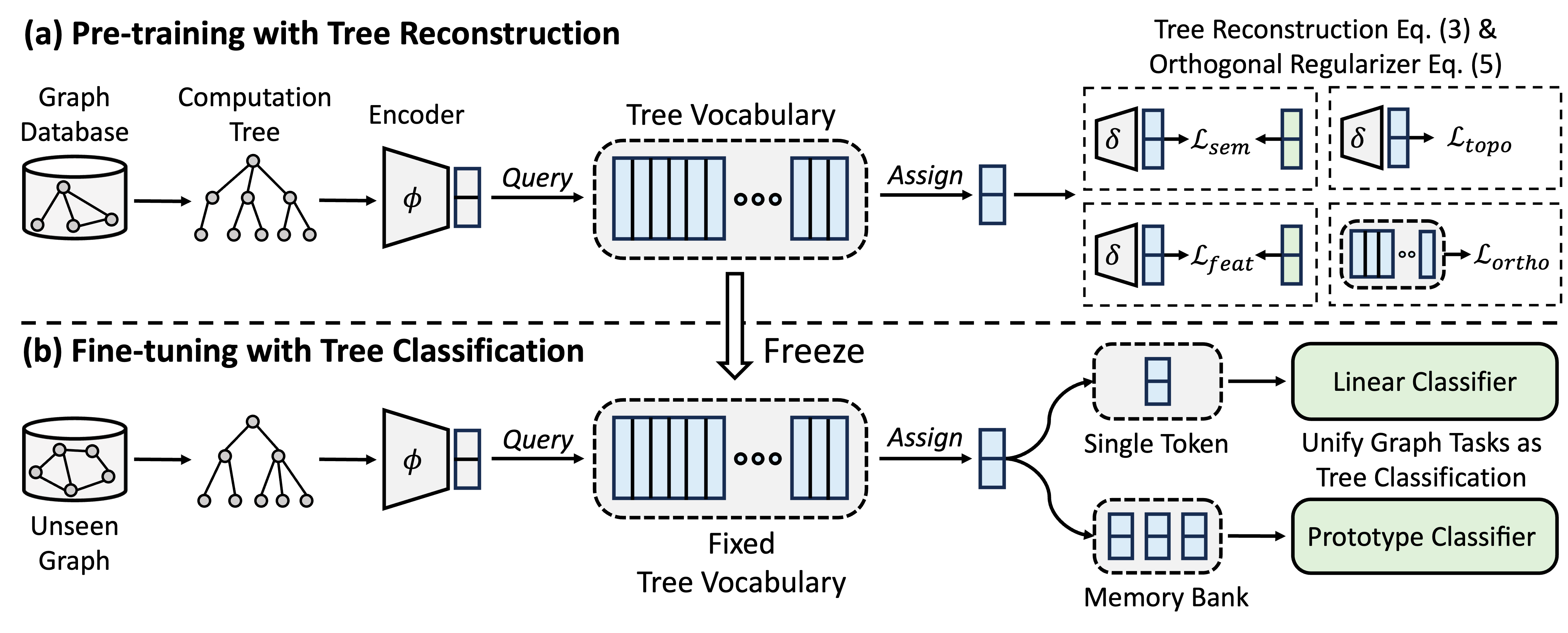
GFT adalah model yayasan grafik lintas domain dan lintas-tugas, yang memperlakukan pohon perhitungan sebagai pola yang dapat ditransfer untuk mendapatkan kosakata pohon yang dapat ditransfer. Selain itu, GFT menyediakan kerangka kerja terpadu untuk menyelaraskan tugas-tugas yang berhubungan dengan grafik, memungkinkan model grafik tunggal, misalnya, GNN, untuk secara bersama-sama menangani tugas tingkat simpul, tingkat tepi, dan tingkat grafik.
Selama pra-pelatihan, model mengkodekan pengetahuan umum dari database grafik menjadi kosakata pohon melalui tugas rekonstruksi pohon. Dalam fine-tuning, kosakata pohon yang dipelajari diterapkan untuk menyatukan tugas-tugas terkait grafik sebagai tugas klasifikasi pohon, mengadaptasi pengetahuan umum yang diperoleh dengan tugas-tugas tertentu.
Anda dapat menggunakan Conda untuk menginstal lingkungan. Harap jalankan skrip berikut. Kami menjalankan semua percobaan pada GPU A40 48G tunggal, namun GPU dengan memori 24G cukup untuk menangani semua dataset dengan mini-batch.
conda env create -f environment.yml
conda activate GFT
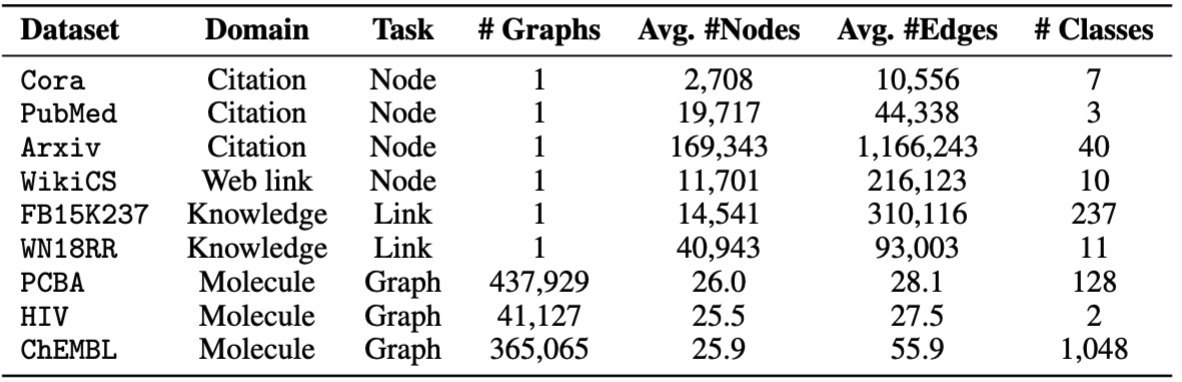
Kami menggunakan set data yang disediakan oleh OFA. Anda dapat menjalankan pretrain.py untuk secara otomatis mengunduh dataset, yang akan diunduh ke /data secara default. Pipa akan secara otomatis preprocess dataset dengan mengonversi deskripsi tekstual ke embeddings tekstual.
Atau, Anda dapat mengunduh set data preproses kami dan unzip pada folder /data .
Kode GFT disajikan dalam folder /GFT . Strukturnya adalah sebagai berikut.
└── GFT
├── pretrain.py
├── finetune.py
├── dataset
│ ├── ...
│ └── process_datasets.py
├── model
│ ├── encoder.py
│ ├── vq.py
│ ├── pt_model.py
│ └── ft_model.py
├── task
│ ├── node.py
│ ├── link.py
│ └── graph.py
└── utils
├── args.py
├── loader.py
└── ...
Anda dapat menjalankan pretrain.py untuk pretraining pada berbagai grafik dan finetune.py untuk adaptasi ke tugas hilir tertentu dengan finetuning dasar atau pembelajaran beberapa shot.
Untuk mereproduksi hasilnya, kami memberikan hyper-parameter terperinci untuk pretraining dan finetuning, dipelihara dalam config/pretrain.yaml dan config/finetune.yaml , masing-masing. Untuk memanfaatkan hiper-parameter default, kami memberikan perintah --use_params untuk pretrain dan finetune.
# Pretraining with default hyper-parameters
python GFT/pretrain.py --use_params
# Finetuning on Cora with default hyper-parameters
python GFT/finetune.py --use_params --dataset cora
# Few-shot learning on Cora with default hyper-parameters
python GFT/finetune.py --use_params --dataset cora --setting few_shot
Untuk finetuning, kami menyediakan delapan dataset, termasuk cora , pubmed , wikics , arxiv , WN18RR , FB15K237 , chemhiv , dan chempcba .
Atau, Anda dapat menjalankan skrip untuk mereproduksi eksperimen.
# Pretraining with default hyper-parameters
sh script/pretrain.sh
# Finetuning on all datasets with default hyper-parameters
sh script/finetune.sh
# Few-shot learning on all datasets with default hyper-parameters
sh script/few_shot.sh
CATATAN: Model pretrained akan disimpan di ckpts/pretrain_model/ secara default.
# The basic command for pretraining GFT
python GFT/pretrain.py
Saat Anda menjalankan pretrain.py , Anda dapat menyesuaikan set data pretraining dan hyper-parameter.
Anda dapat menggunakan --pretrain_dataset (atau --pt_data ) untuk mengatur set data pretrain yang digunakan dan bobot yang sesuai. Konfigurasi data yang telah ditentukan sebelumnya ada di config/pt_data.yaml , dengan struktur berikut.
all:
cora: 5
pubmed: 5
arxiv: 5
wikics: 5
WN18RR: 5
FB15K237: 10
chemhiv: 1
chemblpre: 0.1
chempcba: 0.1
...
Dalam kasus di atas, all adalah nama pengaturan, yang berarti semua dataset digunakan dalam pretraining. Untuk setiap dataset, ada pasangan nilai kunci, di mana kuncinya adalah nama dataset dan nilainya adalah bobot pengambilan sampel. Misalnya, cora: 5 berarti dataset cora akan diambil sampelnya 5 kali dalam satu zaman tunggal. Anda dapat merancang kombinasi dataset Anda sendiri untuk pretraining GFT.
Anda dapat menyesuaikan fase pretraining dengan mengubah hyper-parameter encoder, kuantisasi vektor, pelatihan model.
--pretrain_dataset : Tunjukkan dataset pretraining. Sama dengan hal di atas.--use_params : Gunakan hiper-parameter yang telah ditentukan sebelumnya.--seed : Benih yang digunakan untuk pretraining.--hidden_dim : Dimensi di lapisan tersembunyi GNNs.--num_layers : Lapisan GNN.--activation : Fungsi aktivasi.--backbone : THE BACKBONE GNN.--normalize : Lapisan normalisasi.--dropout : Dropout dari Layer GNN.--code_dim : Dimensi setiap kode dalam kosakata.--codebook_size : Jumlah kode dalam kosakata.--codebook_head : Jumlah kepala codebook. Jika angkanya lebih besar dari 1, Anda akan bersama -sama menggunakan beberapa kosa kata.--codebook_decay : Tingkat pembusukan kode.--commit_weight : Berat dari istilah komitmen.--pretrain_epochs : Jumlah zaman.--pretrain_lr : Tingkat pembelajaran.--pretrain_weight_decay : Berat reguler L2.--pretrain_batch_size : ukuran batch.--feat_p : Tingkat korupsi fitur.--edge_p : Tingkat korupsi tepi/struktur.--topo_recon_ratio : Rasio tepi harus direkonstruksi.--feat_lambda : Berat kehilangan fitur.--topo_lambda : Berat dari kehilangan topologi.--topo_sem_lambda : Berat dari kehilangan topologi dalam fitur tepi rekonstruksi.--sem_lambda : Berat kerugian semantik.--sem_encoder_decay : Tingkat pembaruan momentum untuk enkoder semantik. # The basic command for adapting GFT on downstream tasks via finetuning.
python GFT/finetune.py
Anda dapat mengatur --dataset untuk menunjukkan dataset hilir, dan --use_params untuk menggunakan hyper-parameter yang telah ditentukan sebelumnya untuk setiap dataset. Hyper-parameter lain yang dapat Anda tunjukkan disajikan sebagai berikut.
Untuk grafik dengan 1 pemisahan yang telah ditentukan sebelumnya, Anda dapat --repeat untuk melakukan beberapa percobaan.
--hidden_dim : Dimensi di lapisan tersembunyi GNNs.--num_layers : Lapisan GNN.--activation : Fungsi aktivasi.--backbone : THE BACKBONE GNN.--normalize : Lapisan normalisasi.--dropout : Dropout dari Layer GNN.--code_dim : Dimensi setiap kode dalam kosakata.--codebook_size : Jumlah kode dalam kosakata.--codebook_head : Jumlah kepala codebook. Jika angkanya lebih besar dari 1, Anda akan bersama -sama menggunakan beberapa kosa kata.--codebook_decay : Tingkat pembusukan kode.--commit_weight : Berat dari istilah komitmen.--finetune_epochs : jumlah zaman.--finetune_lr : Tingkat pembelajaran.--early_stop : Epoch stop awal maksimum.--batch_size : Jika diatur ke 0, lakukan pelatihan grafik penuh. --lambda_proto : Berat dari prototipe classifier dalam finetuning.
--lambda_act : Berat classifier linier dalam finetuning.
--trade_off : Pertukaran antara menggunakan prototipe berkelas atau menggunakan classifier linier dalam inferensi.
Anda dapat menambahkan --no_lin_clf atau --no_proto_clf untuk menghindari menggunakan classifier linier atau prototipe classifier, masing -masing. Perhatikan kedua istilah ini adalah konflik, karena Anda harus menggunakan setidaknya satu classifier.
# The basic command for adaptation GFT on downstream tasks via few-shot learning.
python GFT/finetune.py --setting few_shot
Anda dapat mengatur --dataset untuk menunjukkan dataset hilir, dan --use_params untuk menggunakan hyper-parameter yang telah ditentukan sebelumnya untuk setiap dataset. Hyper-parameter lain yang dapat Anda tunjukkan disajikan sebagai berikut.
Hyper-parameter yang didedikasikan untuk pembelajaran beberapa shot adalah
--n_train : Jumlah instance pelatihan per kelas untuk finetuning model. Perhatikan bahwa n_train kecil mencapai kinerja yang diinginkan --n_task : Jumlah tugas sampel.--n_way : Jumlah cara.--n_query : Ukuran kueri diatur per cara.--n_shot : Ukuran dukungan set per cara.--hidden_dim : Dimensi di lapisan tersembunyi GNNs.--num_layers : Lapisan GNN.--activation : Fungsi aktivasi.--backbone : THE BACKBONE GNN.--normalize : Lapisan normalisasi.--dropout : Dropout dari Layer GNN.--code_dim : Dimensi setiap kode dalam kosakata.--codebook_size : Jumlah kode dalam kosakata.--codebook_head : Jumlah kepala codebook. Jika angkanya lebih besar dari 1, Anda akan bersama -sama menggunakan beberapa kosa kata.--codebook_decay : Tingkat pembusukan kode.--commit_weight : Berat dari istilah komitmen.--finetune_epochs : jumlah zaman.--finetune_lr : Tingkat pembelajaran.--early_stop : Epoch stop awal maksimum.--batch_size : Jika diatur ke 0, lakukan pelatihan grafik penuh. --lambda_proto : Berat dari prototipe classifier dalam finetuning.
--lambda_act : Berat classifier linier dalam finetuning.
--trade_off : Pertukaran antara menggunakan prototipe berkelas atau menggunakan classifier linier dalam inferensi.
Anda dapat menambahkan --no_lin_clf atau --no_proto_clf untuk menghindari menggunakan classifier linier atau prototipe classifier, masing -masing. Perhatikan kedua istilah ini adalah konflik, karena Anda harus menggunakan setidaknya satu classifier.
Hasil eksperimen dapat bervariasi karena inisialisasi acak selama pretraining. Kami memberikan hasil eksperimen menggunakan benih acak yang berbeda (yaitu, 1-5) dalam pretraining untuk menunjukkan dampak potensial dari inisialisasi acak.
| Cora | PubMed | Wiki-CS | Arxiv | WN18RR | FB15K237 | HIV | PCBA | Rata-rata | |
|---|---|---|---|---|---|---|---|---|---|
| Benih = 1 | 78,58 ± 0,90 | 77,55 ± 1,54 | 79,38 ± 0,57 | 72,24 ± 0,16 | 91,56 ± 0,33 | 89,67 ± 0,35 | 72.69 ± 1,93 | 78,24 ± 0,23 | 79.99 |
| Benih = 2 | 78.27 ± 1.26 | 76.41 ± 1.36 | 79,36 ± 0,62 | 72,13 ± 0,24 | 91,72 ± 0,19 | 89,66 ± 0,31 | 71.62 ± 2.45 | 78,20 ± 0,33 | 79.67 |
| Benih = 3 | 78.16 ± 1.62 | 76.28 ± 1.37 | 79,32 ± 0,65 | 72,13 ± 0,30 | 91,57 ± 0,44 | 89,78 ± 0,23 | 71.58 ± 2.28 | 78.12 ± 0,37 | 79.62 |
| Benih = 4 | 78.42 ± 1.37 | 75,76 ± 1,58 | 79,44 ± 0,62 | 72,36 ± 0,34 | 91,70 ± 0,24 | 89,73 ± 0,21 | 72.57 ± 2.46 | 78,34 ± 0,27 | 79.79 |
| Benih = 5 | 78,56 ± 1,62 | 76.49 ± 2.00 | 79,27 ± 0,55 | 72.18 ± 0,26 | 91,47 ± 0,39 | 89,80 ± 0,19 | 72,27 ± 0,93 | 78,31 ± 0,34 | 79.79 |
| Dilaporkan | 78.62 ± 1.21 | 77.19 ± 1,99 | 79,39 ± 0,42 | 71,93 ± 0,12 | 91,91 ± 0,34 | 89,72 ± 0,20 | 72.67 ± 1.38 | 77,90 ± 0,64 | 79.92 |
Untuk lebih memastikan reproduktifitas, kami menyediakan pos pemeriksaan seed = 1 di tautan ini. Kami memilih ini karena kinerja rata -rata terbaik. Anda dapat membuka ritsleting file yang diunduh di path ckpts/pretrain_model/ , dan mengatur --pt_seed 1 saat menggunakan finetune.py untuk memanfaatkan pos pemeriksaan yang disediakan dengan hati -hati.
Silakan hubungi [email protected] atau buka masalah jika Anda memiliki pertanyaan.
Jika Anda menemukan repo berguna untuk penelitian Anda, silakan kutip kertas asli dengan benar.
@inproceedings { wang2024gft ,
title = { GFT: Graph Foundation Model with Transferable Tree Vocabulary } ,
author = { Wang, Zehong and Zhang, Zheyuan and Chawla, Nitesh V and Zhang, Chuxu and Ye, Yanfang } ,
booktitle = { The Thirty-eighth Annual Conference on Neural Information Processing Systems } ,
year = { 2024 } ,
url = { https://openreview.net/forum?id=0MXzbAv8xy }
}Repositori ini didasarkan pada basis kode OFA, PYG, OGB, dan VQ. Terima kasih atas berbagi mereka!


