vision_transformer
1.0.0
Di repositori ini kami merilis model dari makalah
Model-model tersebut dilatih sebelumnya pada dataset Imagenet dan Imagenet-21K. Kami menyediakan kode untuk menyempurnakan model yang dirilis dalam Jax/Flax.
Model-model dari basis kode ini awalnya dilatih di https://github.com/google-research/big_vision/ di mana Anda dapat menemukan kode yang lebih canggih (misalnya pelatihan multi-host), serta beberapa skrip pelatihan asli (misalnya konfigurasi EG /vit_i21k.py untuk pra-pelatihan vit, atau configs/transfer.py untuk mentransfer model).
Daftar isi:
Di bawah Colabs berjalan dengan GPU, dan TPU (8 core, paralelisme data).
Colab pertama menunjukkan kode jax transformator visi dan mixer MLP. Colab ini memungkinkan Anda untuk mengedit file dari repositori secara langsung di UI Colab dan telah beranotasi sel Colab yang memandu Anda melalui kode langkah demi langkah, dan memungkinkan Anda berinteraksi dengan data.
https://colab.research.google.com/github/google-research/vision_transformer/blob/main/vit_jax.ipynb
Colab kedua memungkinkan Anda untuk menjelajahi transformator penglihatan> 50k dan pos pemeriksaan hibrida yang digunakan untuk menghasilkan data dari makalah ketiga "Cara melatih Vit Anda? ...". Colab menyertakan kode untuk mengeksplorasi dan memilih pos pemeriksaan, dan untuk melakukan inferensi baik menggunakan kode JAX dari repo ini, dan juga menggunakan perpustakaan timm Pytorch yang populer yang dapat secara langsung memuat pos pemeriksaan ini juga. Perhatikan bahwa beberapa model juga tersedia langsung dari TF-Hub: Sayakpaul/Collections/Vision_Transformer (Kontribusi Eksternal oleh Sayak Paul).
Colab kedua juga memungkinkan Anda menyempurnakan pos pemeriksaan pada dataset TFDS dan dataset Anda sendiri dengan contoh dalam file JPEG individual (opsional langsung membaca dari Google Drive).
https://colab.research.google.com/github/google-research/vision_transformer/blob/main/vit_jax_augreg.ipynb
CATATAN : Untuk saat ini (6/20/21) Google Colab hanya mendukung GPU tunggal (NVIDIA TESLA T4), dan TPU (saat ini TPUV2-8) dilampirkan secara tidak langsung ke Colab VM dan berkomunikasi melalui jaringan lambat, yang mengarah ke cantik Kecepatan pelatihan yang buruk. Anda biasanya ingin mengatur mesin khusus jika Anda memiliki jumlah data yang tidak sepele untuk disempurnakan. Untuk detailnya lihat bagian Cloud yang berjalan.
Pastikan Anda memiliki Python>=3.10 diinstal pada mesin Anda.
Instal Jax dan Python Dependency dengan menjalankan:
# If using GPU:
pip install -r vit_jax/requirements.txt
# If using TPU:
pip install -r vit_jax/requirements-tpu.txt
Untuk versi JAX yang lebih baru, ikuti instruksi yang disediakan di repositori yang sesuai yang ditautkan di sini. Perhatikan bahwa instruksi instalasi untuk CPU, GPU dan TPU sedikit berbeda.
Instal Flaxformer, ikuti instruksi yang disediakan di repositori yang sesuai yang ditautkan di sini.
Untuk detail lebih lanjut, lihat bagian yang berjalan di cloud di bawah ini.
Anda dapat menjalankan fine-tuning model yang diunduh pada dataset yang Anda minati. Semua model berbagi antarmuka baris perintah yang sama.
Misalnya untuk menyempurnakan vit-b/16 (pra-terlatih di imagenet21k) di cifar10 (perhatikan bagaimana kami menentukan b16,cifar10 sebagai argumen ke konfigurasi, dan bagaimana kami menginstruksikan kode untuk mengakses model langsung dari ember GCS GCS Alih -alih pertama kali mengunduhnya ke direktori lokal):
python -m vit_jax.main --workdir=/tmp/vit- $( date +%s )
--config= $( pwd ) /vit_jax/configs/vit.py:b16,cifar10
--config.pretrained_dir= ' gs://vit_models/imagenet21k 'Untuk menyempurnakan mixer-b/16 (pra-terlatih di imagenet21k) di cifar10:
python -m vit_jax.main --workdir=/tmp/vit- $( date +%s )
--config= $( pwd ) /vit_jax/configs/mixer_base16_cifar10.py
--config.pretrained_dir= ' gs://mixer_models/imagenet21k ' Kertas "Cara Melatih Vit? ..." Ditambahkan> 50 ribu pos pemeriksaan yang dapat Anda selesaikan dengan konfigurasi configs/augreg.py . Ketika Anda hanya menentukan nama model (nilai config.name dari configs/model.py ), maka pos pemeriksaan I21K terbaik dengan akurasi validasi hulu (yang disarankan "Checkpoint, lihat bagian 4.5 dari kertas) dipilih. Untuk memutuskan model mana yang ingin Anda gunakan, lihat Gambar 3 di koran. Dimungkinkan juga untuk memilih pos pemeriksaan yang berbeda (lihat Colab vit_jax_augreg.ipynb ) dan kemudian tentukan nilai dari kolom filename atau adapt_filename , yang sesuai dengan nama file tanpa .npz dari gs://vit_models/augreg Directory.
python -m vit_jax.main --workdir=/tmp/vit- $( date +%s )
--config= $( pwd ) /vit_jax/configs/augreg.py:R_Ti_16
--config.dataset=oxford_iiit_pet
--config.base_lr=0.01 Saat ini, kode akan secara otomatis mengunduh dataset CIFAR-10 dan CIFAR-100. Dataset publik atau khusus lainnya dapat dengan mudah diintegrasikan, menggunakan perpustakaan Dataset TensorFlow. Perhatikan bahwa Anda juga perlu memperbarui vit_jax/input_pipeline.py untuk menentukan beberapa parameter tentang dataset yang ditambahkan.
Perhatikan bahwa kode kami menggunakan semua GPU/TPU yang tersedia untuk menyempurnakan.
Untuk melihat daftar terperinci dari semua bendera yang tersedia, jalankan python3 -m vit_jax.train --help .
Catatan tentang memori:
--config.accum_steps=8 -sebagai alternatif, Anda juga dapat mengurangi --config.batch=512 (dan mengurangi --config.base_lr yang sesuai).--config.shuffle_buffer=50000 . by Alexey Dosovitskiy*†, Lucas Beyer*, Alexander Kolesnikov*, Dirk Weissenborn*, Xiaohua Zhai*, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit and Neil Houlsby*†.
(*) Kontribusi teknis yang sama, (†) Penasihat yang sama.
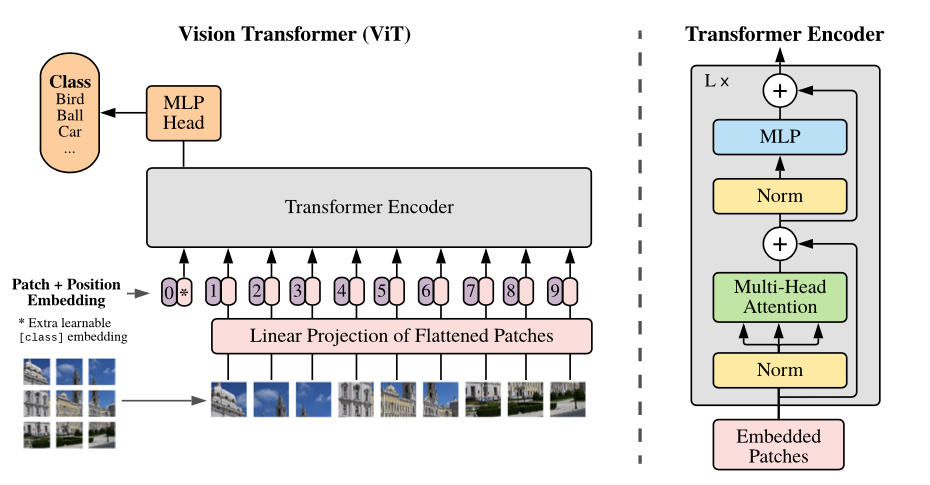
Tinjauan model: Kami membagi gambar menjadi tambalan ukuran tetap, secara linear menanamkan masing-masing, menambah posisi embeddings, dan memberi makan urutan vektor yang dihasilkan ke encoder transformator standar. Untuk melakukan klasifikasi, kami menggunakan pendekatan standar untuk menambahkan "token klasifikasi" tambahan yang dapat dipelajari ke urutan.
Kami menyediakan berbagai model VIT di berbagai ember GCS. Model dapat diunduh dengan misalnya:
wget https://storage.googleapis.com/vit_models/imagenet21k/ViT-B_16.npz
Model FileNames (tanpa ekstensi .npz ) sesuai dengan config.model_name di vit_jax/configs/models.py
gs://vit_models/imagenet21k -Model yang dilatih sebelumnya di ImageNet-21K.gs://vit_models/imagenet21k+imagenet2012 -Model pra-terlatih di ImageNet-21k dan disesuaikan di ImageNet.gs://vit_models/augreg -MODEL YANG DITERIMA DI IMACENET-21K, Menerapkan jumlah augreg yang bervariasi. Peningkatan kinerja.gs://vit_models/sam - Model yang dilatih sebelumnya di ImageNet dengan SAM.gs://vit_models/gsam - Model pra -terlatih di ImageNet dengan GSAM.Kami merekomendasikan menggunakan pos pemeriksaan berikut, dilatih dengan augreg yang memiliki metrik pra-pelatihan terbaik:
| Model | Pos pemeriksaan pra-terlatih | Ukuran | Pos Pemeriksaan Fine-Tuned | Resolusi | Img/dtk | Akurasi imagenet |
|---|---|---|---|---|---|---|
| L/16 | gs://vit_models/augreg/L_16-i21k-300ep-lr_0.001-aug_strong1-wd_0.1-do_0.0-sd_0.0.npz | 1243 MIB | gs://vit_models/augreg/L_16-i21k-300ep-lr_0.001-aug_strong1-wd_0.1-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.01-res_384.npz | 384 | 50 | 85,59% |
| B/16 | gs://vit_models/augreg/B_16-i21k-300ep-lr_0.001-aug_medium1-wd_0.1-do_0.0-sd_0.0.npz | 391 MIB | gs://vit_models/augreg/B_16-i21k-300ep-lr_0.001-aug_medium1-wd_0.1-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.03-res_384.npz | 384 | 138 | 85,49% |
| S/16 | gs://vit_models/augreg/S_16-i21k-300ep-lr_0.001-aug_light1-wd_0.03-do_0.0-sd_0.0.npz | 115 MIB | gs://vit_models/augreg/S_16-i21k-300ep-lr_0.001-aug_light1-wd_0.03-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.03-res_384.npz | 384 | 300 | 83,73% |
| R50+L/32 | gs://vit_models/augreg/R50_L_32-i21k-300ep-lr_0.001-aug_medium1-wd_0.1-do_0.1-sd_0.1.npz | 1337 MIB | gs://vit_models/augreg/R50_L_32-i21k-300ep-lr_0.001-aug_medium1-wd_0.1-do_0.1-sd_0.1--imagenet2012-steps_20k-lr_0.01-res_384.npz | 384 | 327 | 85,99% |
| R26+S/32 | gs://vit_models/augreg/R26_S_32-i21k-300ep-lr_0.001-aug_light1-wd_0.1-do_0.0-sd_0.0.npz | 170 MIB | gs://vit_models/augreg/R26_S_32-i21k-300ep-lr_0.001-aug_light1-wd_0.1-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.01-res_384.npz | 384 | 560 | 83,85% |
| Ti/16 | gs://vit_models/augreg/Ti_16-i21k-300ep-lr_0.001-aug_none-wd_0.03-do_0.0-sd_0.0.npz | 37 MIB | gs://vit_models/augreg/Ti_16-i21k-300ep-lr_0.001-aug_none-wd_0.03-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.03-res_384.npz | 384 | 610 | 78,22% |
| B/32 | gs://vit_models/augreg/B_32-i21k-300ep-lr_0.001-aug_light1-wd_0.1-do_0.0-sd_0.0.npz | 398 MIB | gs://vit_models/augreg/B_32-i21k-300ep-lr_0.001-aug_light1-wd_0.1-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.01-res_384.npz | 384 | 955 | 83,59% |
| S/32 | gs://vit_models/augreg/S_32-i21k-300ep-lr_0.001-aug_none-wd_0.1-do_0.0-sd_0.0.npz | 118 MIB | gs://vit_models/augreg/S_32-i21k-300ep-lr_0.001-aug_none-wd_0.1-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.01-res_384.npz | 384 | 2154 | 79,58% |
| R+ti/16 | gs://vit_models/augreg/R_Ti_16-i21k-300ep-lr_0.001-aug_none-wd_0.03-do_0.0-sd_0.0.npz | 40 mib | gs://vit_models/augreg/R_Ti_16-i21k-300ep-lr_0.001-aug_none-wd_0.03-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.03-res_384.npz | 384 | 2426 | 75,40% |
Hasil dari Vit Paper asli (https://arxiv.org/abs/2010.11929) telah direplikasi menggunakan model dari gs://vit_models/imagenet21k :
| model | dataset | Dropout = 0,0 | Dropout = 0,1 |
|---|---|---|---|
| R50+VIT-B_16 | CIFAR10 | 98.72%, 3.9h (A100), TB.Dev | 98,94%, 10.1h (v100), tb.dev |
| R50+VIT-B_16 | CIFAR100 | 90,88%, 4.1h (A100), TB.Dev | 92,30%, 10.1h (v100), tb.dev |
| R50+VIT-B_16 | imagenet2012 | 83.72%, 9.9h (A100), TB.Dev | 85.08%, 24.2h (v100), tb.dev |
| VIT-B_16 | CIFAR10 | 99,02%, 2.2h (A100), TB.Dev | 98.76%, 7.8h (v100), tb.dev |
| VIT-B_16 | CIFAR100 | 92,06%, 2.2h (A100), TB.Dev | 91.92%, 7.8h (v100), tb.dev |
| VIT-B_16 | imagenet2012 | 84.53%, 6.5h (A100), TB.Dev | 84.12%, 19.3h (v100), tb.dev |
| VIT-B_32 | CIFAR10 | 98,88%, 0,8h (A100), TB.Dev | 98.75%, 1.8h (v100), tb.dev |
| VIT-B_32 | CIFAR100 | 92,31%, 0,8h (A100), TB.Dev | 92.05%, 1.8h (v100), tb.dev |
| VIT-B_32 | imagenet2012 | 81.66%, 3.3h (A100), TB.Dev | 81.31%, 4.9h (v100), tb.dev |
| VIT-L_16 | CIFAR10 | 99.13%, 6.9h (A100), TB.Dev | 99.14%, 24.7h (v100), tb.dev |
| VIT-L_16 | CIFAR100 | 92.91%, 7.1h (A100), TB.Dev | 93.22%, 24.4h (v100), tb.dev |
| VIT-L_16 | imagenet2012 | 84.47%, 16.8h (A100), TB.Dev | 85.05%, 59.7h (v100), tb.dev |
| VIT-L_32 | CIFAR10 | 99,06%, 1,9h (A100), TB.Dev | 99,09%, 6.1h (v100), tb.dev |
| VIT-L_32 | CIFAR100 | 93.29%, 1.9h (A100), TB.Dev | 93,34%, 6,2h (v100), tb.dev |
| VIT-L_32 | imagenet2012 | 81.89%, 7.5H (A100), TB.Dev | 81.13%, 15.0h (v100), tb.dev |
Kami juga ingin menekankan bahwa hasil berkualitas tinggi dapat dicapai dengan jadwal pelatihan yang lebih pendek dan mendorong pengguna kode kami untuk bermain dengan hyper-parameter untuk akurasi trade-off dan anggaran komputasi. Beberapa contoh untuk dataset CIFAR-10/100 disajikan dalam tabel di bawah ini.
| hulu | model | dataset | Total_steps / Warmup_Steps | ketepatan | waktu waktu dinding | link |
|---|---|---|---|---|---|---|
| imagenet21k | VIT-B_16 | CIFAR10 | 500 /50 | 98,59% | 17m | Tensorboard.dev |
| imagenet21k | VIT-B_16 | CIFAR10 | 1000 /100 | 98,86% | 39m | Tensorboard.dev |
| imagenet21k | VIT-B_16 | CIFAR100 | 500 /50 | 89,17% | 17m | Tensorboard.dev |
| imagenet21k | VIT-B_16 | CIFAR100 | 1000 /100 | 91,15% | 39m | Tensorboard.dev |
Oleh Ilya Tolstikhin*, Neil Houlsby*, Alexander Kolesnikov*, Lucas Beyer*, Xiaohua Zhai, Thomas Unterthiner, Jessica Yung, Andreas Steiner, Daniel Keysers, Jakob Uszkoreit, Mario Lucic, Alexey Dosovitskiy.
(*) Kontribusi yang sama.
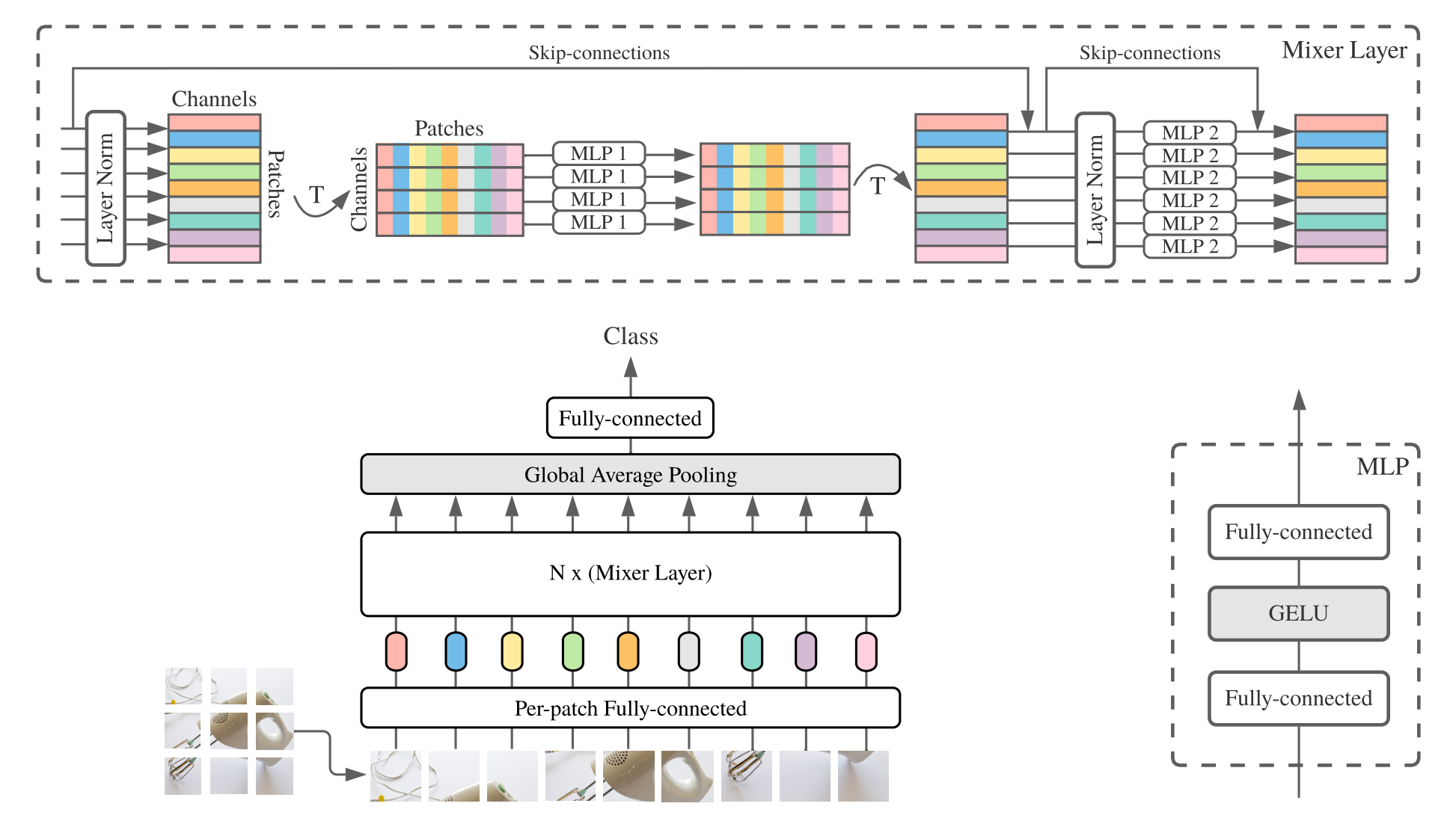
MLP-Mixer ( mixer untuk singkat) terdiri dari embeddings linier per-patch, lapisan mixer, dan kepala classifier. Lapisan mixer berisi satu MLP pencampur token dan satu MLP pencampur saluran, masing-masing terdiri dari dua lapisan yang sepenuhnya terhubung dan gelu nonlinier. Komponen lain termasuk: Skip-Connection, Dropout, dan Linear Classifier Head.
Untuk instalasi ikuti langkah yang sama seperti di atas.
Kami menyediakan model Mixer-B/16 dan Mixer-L/16 yang telah dilatih sebelumnya pada dataset Imagenet dan ImageNet-21K. Detail dapat ditemukan pada Tabel 3 kertas mixer. Semua model dapat ditemukan di:
https://console.cloud.google.com/storage/mixer_models/
Perhatikan bahwa model-model ini juga tersedia langsung dari TF-Hub: Sayakpaul/Collections/MLP-Mixer (Kontribusi Eksternal oleh Sayak Paul).
Kami menjalankan kode penyetelan di Google Cloud Machine dengan empat V100 GPU dengan parameter adaptasi default dari repositori ini. Inilah hasilnya:
| hulu | model | dataset | ketepatan | wall_clock_time | link |
|---|---|---|---|---|---|
| Imagenet | Mixer-B/16 | CIFAR10 | 96,72% | 3.0h | Tensorboard.dev |
| Imagenet | Mixer-L/16 | CIFAR10 | 96,59% | 3.0h | Tensorboard.dev |
| Imagenet-21k | Mixer-B/16 | CIFAR10 | 96,82% | 9.6h | Tensorboard.dev |
| Imagenet-21k | Mixer-L/16 | CIFAR10 | 98,34% | 10.0h | Tensorboard.dev |
Untuk detailnya, lihat Posting Blog Google AI Lit: Menambahkan Pemahaman Bahasa ke Model Gambar, atau Baca Kertas CVPR "Lit: Transfer Zero-Shot dengan Tuning Teks Terkunci-Image" (https://arxiv.org/abs/2111.07991 ).
Kami menerbitkan model transformator B/16-base dengan akurasi Zeroshot Imagenet sebesar 72,1%, dan model L/16-besar dengan akurasi Zeroshot Imagenet sebesar 75,7%. Untuk detail lebih lanjut tentang model ini, silakan merujuk ke kartu model LIT.
Kami menyediakan demo dalam browser dengan encoder teks kecil untuk penggunaan interaktif (model terkecil bahkan harus dijalankan pada ponsel modern):
https://google-research.github.io/vision_transformer/lit/
Dan akhirnya seekor colab untuk menggunakan model JAX dengan encoder gambar dan teks:
https://colab.research.google.com/github/google-research/vision_transformer/blob/main/lit.ipynb
Perhatikan bahwa belum ada model di atas yang mendukung input multi-bahasa, tetapi kami sedang mengerjakan penerbitan model tersebut dan akan memperbarui repositori ini setelah tersedia.
Repositori ini hanya berisi kode evaluasi untuk model LIT. Anda dapat menemukan kode pelatihan di repositori big_vision :
https://github.com/google-research/big_vision/tree/main/big_vision/configs/proj/image_text
Hasil zeroshot yang diharapkan dari model_cards/lit.md (perhatikan bahwa evaluasi zeroshot sedikit berbeda dari evaluasi yang disederhanakan di colab):
| Model | B16B_2 | L16l |
|---|---|---|
| Imagenet Zero-shot | 73,9% | 75,7% |
| Imagenet V2 Zero-shot | 65,1% | 66,6% |
| CIFAR100 Zero-shot | 79,0% | 80,5% |
| Pet37 Zero-shot | 83,3% | 83,3% |
| Resisc45 Zero-shot | 25,3% | 25,6% |
| MS-COCO Captions Retrieval gambar-ke-teks | 51,6% | 48,5% |
| MS-COCO Captions Pengambilan teks-ke-gambar | 31,8% | 31,1% |
Meskipun di atas Colabs cukup berguna untuk memulai, Anda biasanya ingin berlatih di mesin yang lebih besar dengan akselerator yang lebih kuat.
Anda dapat menggunakan perintah berikut untuk mengatur VM dengan GPU di Google Cloud:
# Set variables used by all commands below.
# Note that project must have accounting set up.
# For a list of zones with GPUs refer to
# https://cloud.google.com/compute/docs/gpus/gpu-regions-zones
PROJECT=my-awesome-gcp-project # Project must have billing enabled.
VM_NAME=vit-jax-vm-gpu
ZONE=europe-west4-b
# Below settings have been tested with this repository. You can choose other
# combinations of images & machines (e.g.), refer to the corresponding gcloud commands:
# gcloud compute images list --project ml-images
# gcloud compute machine-types list
# etc.
gcloud compute instances create $VM_NAME
--project= $PROJECT --zone= $ZONE
--image=c1-deeplearning-tf-2-5-cu110-v20210527-debian-10
--image-project=ml-images --machine-type=n1-standard-96
--scopes=cloud-platform,storage-full --boot-disk-size=256GB
--boot-disk-type=pd-ssd --metadata=install-nvidia-driver=True
--maintenance-policy=TERMINATE
--accelerator=type=nvidia-tesla-v100,count=8
# Connect to VM (after some minutes needed to setup & start the machine).
gcloud compute ssh --project $PROJECT --zone $ZONE $VM_NAME
# Stop the VM after use (only storage is billed for a stopped VM).
gcloud compute instances stop --project $PROJECT --zone $ZONE $VM_NAME
# Delete VM after use (this will also remove all data stored on VM).
gcloud compute instances delete --project $PROJECT --zone $ZONE $VM_NAMEAtau, Anda dapat menggunakan perintah serupa berikut untuk mengatur Cloud VM dengan TPU yang dilampirkan (di bawah perintah di bawah yang disalin dari tutorial TPU):
PROJECT=my-awesome-gcp-project # Project must have billing enabled.
VM_NAME=vit-jax-vm-tpu
ZONE=europe-west4-a
# Required to set up service identity initially.
gcloud beta services identity create --service tpu.googleapis.com
# Create a VM with TPUs directly attached to it.
gcloud alpha compute tpus tpu-vm create $VM_NAME
--project= $PROJECT --zone= $ZONE
--accelerator-type v3-8
--version tpu-vm-base
# Connect to VM (after some minutes needed to setup & start the machine).
gcloud alpha compute tpus tpu-vm ssh --project $PROJECT --zone $ZONE $VM_NAME
# Stop the VM after use (only storage is billed for a stopped VM).
gcloud alpha compute tpus tpu-vm stop --project $PROJECT --zone $ZONE $VM_NAME
# Delete VM after use (this will also remove all data stored on VM).
gcloud alpha compute tpus tpu-vm delete --project $PROJECT --zone $ZONE $VM_NAME Dan kemudian ambil repositori dan ketergantungan instalasi (termasuk jaxlib dengan dukungan TPU) seperti biasa:
git clone --depth=1 --branch=master https://github.com/google-research/vision_transformer
cd vision_transformer
# optional: install virtualenv
pip3 install virtualenv
python3 -m virtualenv env
. env/bin/activateJika Anda terhubung ke VM dengan GPU terlampir, instal JAX dan dependensi lainnya dengan perintah berikut:
pip install -r vit_jax/requirements.txtJika Anda terhubung ke VM dengan TPU terlampir, instal JAX dan dependensi lainnya dengan perintah berikut:
pip install -r vit_jax/requirements-tpu.txtInstal Flaxformer, ikuti instruksi yang disediakan di repositori yang sesuai yang ditautkan di sini.
Untuk GPU dan TPU, periksa apakah Jax dapat terhubung ke akselerator yang terpasang dengan perintah:
python -c ' import jax; print(jax.devices()) 'Dan akhirnya menjalankan salah satu perintah yang disebutkan dalam bagian yang menyempurnakan model.
@article{dosovitskiy2020vit,
title={An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale},
author={Dosovitskiy, Alexey and Beyer, Lucas and Kolesnikov, Alexander and Weissenborn, Dirk and Zhai, Xiaohua and Unterthiner, Thomas and Dehghani, Mostafa and Minderer, Matthias and Heigold, Georg and Gelly, Sylvain and Uszkoreit, Jakob and Houlsby, Neil},
journal={ICLR},
year={2021}
}
@article{tolstikhin2021mixer,
title={MLP-Mixer: An all-MLP Architecture for Vision},
author={Tolstikhin, Ilya and Houlsby, Neil and Kolesnikov, Alexander and Beyer, Lucas and Zhai, Xiaohua and Unterthiner, Thomas and Yung, Jessica and Steiner, Andreas and Keysers, Daniel and Uszkoreit, Jakob and Lucic, Mario and Dosovitskiy, Alexey},
journal={arXiv preprint arXiv:2105.01601},
year={2021}
}
@article{steiner2021augreg,
title={How to train your ViT? Data, Augmentation, and Regularization in Vision Transformers},
author={Steiner, Andreas and Kolesnikov, Alexander and and Zhai, Xiaohua and Wightman, Ross and Uszkoreit, Jakob and Beyer, Lucas},
journal={arXiv preprint arXiv:2106.10270},
year={2021}
}
@article{chen2021outperform,
title={When Vision Transformers Outperform ResNets without Pretraining or Strong Data Augmentations},
author={Chen, Xiangning and Hsieh, Cho-Jui and Gong, Boqing},
journal={arXiv preprint arXiv:2106.01548},
year={2021},
}
@article{zhuang2022gsam,
title={Surrogate Gap Minimization Improves Sharpness-Aware Training},
author={Zhuang, Juntang and Gong, Boqing and Yuan, Liangzhe and Cui, Yin and Adam, Hartwig and Dvornek, Nicha and Tatikonda, Sekhar and Duncan, James and Liu, Ting},
journal={ICLR},
year={2022},
}
@article{zhai2022lit,
title={LiT: Zero-Shot Transfer with Locked-image Text Tuning},
author={Zhai, Xiaohua and Wang, Xiao and Mustafa, Basil and Steiner, Andreas and Keysers, Daniel and Kolesnikov, Alexander and Beyer, Lucas},
journal={CVPR},
year={2022}
}
Dalam urutan kronologis terbalik:
2022-08-18: Menambahkan model LIT-B16B_2 yang dilatih untuk 60k langkah (lit_b16b: 30k) tanpa kepala linier di sisi gambar (lit_b16b: 768) dan memiliki kinerja yang lebih baik.
2022-06-09: Menambahkan model VIT dan mixer yang dilatih dari awal menggunakan GSAM di ImageNet tanpa augmentasi data yang kuat. VIT yang dihasilkan mengungguli yang memiliki ukuran serupa yang dilatih menggunakan ADAMW Optimizer atau algoritma SAM asli, atau dengan augmentasi data yang kuat.
2022-04-14: Model tambahan dan Colab untuk model LIT.
2021-07-29: Menambahkan model Augreg Vit-B/8 (3 pemeriksaan hulu dan adaptasi dengan resolusi = 224).
2021-07-02: Menambahkan kertas "When Vision Transformers mengungguli Resnets ..."
2021-07-02: Menambahkan SAM (Minimalisasi Aware-Sharpness) Optimalisasi Vit dan MLP-Mixer Checkpoints.
2021-06-20: Menambahkan kertas "Cara Melatih Vit? ...", dan Colab baru untuk mengeksplorasi> 50k pos pemeriksaan yang sudah terlatih dan disesuaikan yang disebutkan di koran.
2021-06-18: Repositori ini ditulis ulang untuk menggunakan Flax Linen API dan ml_collections.ConfigDict untuk konfigurasi.
2021-05-19: Dengan publikasi kertas "Cara Melatih Vit? , dan disesuaikan dengan Imagenet, Pets37, Kitti-Distance, CIFAR-100, dan RESISC45. Lihat vit_jax_augreg.ipynb untuk menavigasi harta karun model ini! Misalnya, Anda dapat menggunakan Colab itu untuk mengambil nama file dari pos pemeriksaan yang disarankan pra-terlatih dan disesuaikan dari kolom i21k_300 pada Tabel 3 di koran.
2020-12-01: Menambahkan model hibrida R50+VIT-B/16 (Vit-B/16 di atas tulang punggung ResNet-50). Ketika pretrained di ImageNet21K, model ini mencapai hampir kinerja model L/16 dengan kurang dari setengah biaya finetuning komputasi. Perhatikan bahwa "R50" agak dimodifikasi untuk varian B/16: resnet-50 asli memiliki blok [3,4,6,3], masing-masing mengurangi resolusi gambar dengan faktor dua. Dalam kombinasi dengan batang resnet ini akan menghasilkan pengurangan 32x sehingga bahkan dengan ukuran tambalan (1,1) varian Vit-B/16 tidak dapat diwujudkan lagi. Untuk alasan ini kami malah menggunakan blok [3,4,9] untuk varian R50+B/16.
2020-11-09: Menambahkan model VIT-L/16.
2020-10-29: Menambahkan model VIT-B/16 dan VIT-L/16 pretrained di ImageNet-21K dan kemudian disesuaikan dengan ImagEnet pada resolusi 224x224 (bukan default 384x384). Model-model ini memiliki akhiran "-224" dalam namanya. Mereka diharapkan untuk mencapai akurasi 81,2% dan 82,7% masing-masing.
Rilis open source disiapkan oleh Andreas Steiner.
Catatan: Repositori ini bercabang dan dimodifikasi dari Google-Research/Big_Transfer.
Ini bukan produk Google resmi.


