streaming
v0.9.1
Kami membangun streamingDataSet untuk membuat pelatihan tentang set data besar dari penyimpanan cloud secepat, murah, dan dapat diskalakan mungkin.
Ini dirancang khusus untuk pelatihan multi-node, terdistribusi untuk model besar-memaksimalkan jaminan kebenaran, kinerja, dan kemudahan penggunaan. Sekarang, Anda dapat melatih secara efisien di mana saja, terlepas dari lokasi data pelatihan Anda. Cukup streaming dalam data yang Anda butuhkan, saat Anda membutuhkannya. Untuk mempelajari lebih lanjut tentang mengapa kami membangun streamingDataset, baca blog pengumuman kami.
StreamingDataSet kompatibel dengan tipe data apa pun, termasuk gambar, teks, video, dan data multimodal .
Dengan dukungan untuk penyedia penyimpanan cloud utama (AWS, OCI, GCS, Azure, Databricks, dan toko objek yang kompatibel S3 seperti CloudFlare R2, Coreweave, Backblaze B2, dll. , StreamingDataset dengan mulus berintegrasi ke dalam alur kerja pelatihan Anda yang ada.

Streaming dapat diinstal dengan pip :
PIP menginstal streaming mosaicml
Konversikan dataset mentah Anda menjadi salah satu format streaming yang didukung kami:
Format MDS (Mosaic Data Shard) yang dapat mengkode dan memecahkan kode objek Python apa pun
CSV / TSV
Jsonl
impor numpy sebagai npfrom pil impor imagefrom streaming impor mdswriter# direktori lokal atau jarak jauh untuk menyimpan file output output terkompresi_dir = 'path-to-dataset'# Sebuah bidang input pemetaan kamus ke typescolumns data mereka = {'gambar': 'jpeg' , 'class': 'int'}# kompresi shard, jika anycompression = 'zstd'# simpan sampel sebagai pecahan menggunakan mdswriterwith mdswriter (out = data_dir, kolom = kolom, kompresi = kompresi) sebagai keluar: untuk saya dalam kisaran (10000 ): sampel = {'Image': image.fromArray (np.random.randint (0, 256, (32, 32, 3), np.uint8)), 'kelas': np.random.randint (10),
} out.write (sampel)Unggah dataset streaming Anda ke penyimpanan cloud pilihan Anda (AWS, OCI, atau GCP). Di bawah ini adalah salah satu contoh mengunggah direktori ke ember S3 menggunakan AWS CLI.
$ AWS S3 CP-Rekursif Path-to-Dataset S3: // My-Bucket/Path-to-Dataset
dari torch.utils.data impor dataloader dari streaming streaming impor streamingDataSet# remote path di mana dataset penuh secara terus-menerus distedremote = 's3: // my-bucket/path-to-dataset'# Lokal kerja di mana dataset di-cache selama operasi OperationLocal = '/TMP /PATT-TO-DATASET '# Buat streaming datasetDataSet = streamingDataSet (local = local, remote = remote, shuffle = true)# Mari kita lihat apa yang ada dalam sampel# 1337 ... sampel = dataset [1337] IMG = sampel [' Image [' '] cls = sampel [' class ']# Buat pytorch dataloaderDataLoader = dataloader (dataset)
Memulai pemandu, contoh, referensi API, dan informasi berguna lainnya dapat ditemukan di dokumen kami.
Kami memiliki tutorial end-to-end untuk melatih model di:
CIFAR-10
Facesynthetics
Sintetisnlp
Kami juga memiliki kode starter untuk kumpulan data populer berikut, yang dapat ditemukan di direktori streaming :
| Dataset | Tugas | Membaca | Menulis |
|---|---|---|---|
| Laion-400m | Teks dan gambar | Membaca | Menulis |
| Webvid | Teks dan video | Membaca | Menulis |
| C4 | Teks | Membaca | Menulis |
| Enwiki | Teks | Membaca | Menulis |
| Tumpukan | Teks | Membaca | Menulis |
| Ade20k | Segmentasi gambar | Membaca | Menulis |
| CIFAR10 | Klasifikasi Gambar | Membaca | Menulis |
| KELAPA | Klasifikasi Gambar | Membaca | Menulis |
| Imagenet | Klasifikasi Gambar | Membaca | Menulis |
Untuk memulai pelatihan tentang kumpulan data ini:
Konversi data mentah menjadi format .mds menggunakan skrip yang sesuai dari direktori convert .
Misalnya:
$ python -m streaming.multimodal.convert.webvid - -dalam <csv file> - -out <MDS output directory>
Impor Kelas Dataset Untuk Mulai Melatih Model.
dari streaming.multimodal impor streaminginsidewebvidDataSet = streamingIndewebvid (lokal = lokal, jarak jauh = jarak jauh, shuffle = true)
Bereksperimen dengan mudah dengan campuran dataset dengan Stream . Pengambilan sampel dataset dapat dikontrol secara relatif (proporsi) atau absolut (istilah ulang atau sampel). Selama streaming, dataset yang berbeda dialirkan, dikocok, dan dicampur dengan mulus tepat waktu.
# mix C4, github code, and internal datasets streams = [ Stream(remote='s3://datasets/c4', proportion=0.4), Stream(remote='s3://datasets/github', proportion=0.1), Stream(remote='gcs://datasets/my_internal', proportion=0.5), ] dataset = StreamingDataset( streams=streams, samples_per_epoch=1e8, )
Fitur unik dari solusi kami: Sampel berada dalam urutan yang sama terlepas dari jumlah GPU, node, atau pekerja CPU. Ini membuatnya lebih mudah untuk:
Reproduksi dan debug pelatihan dan longgar rugi
Muat pos pemeriksaan yang dilatih pada 64 GPU dan debug pada 8 GPU dengan reproduktifitas
Lihat gambar di bawah ini - Melatih model pada 1, 8, 16, 32, atau 64 GPU menghasilkan kurva kehilangan yang sama persis (hingga batasan matematika titik mengambang!)
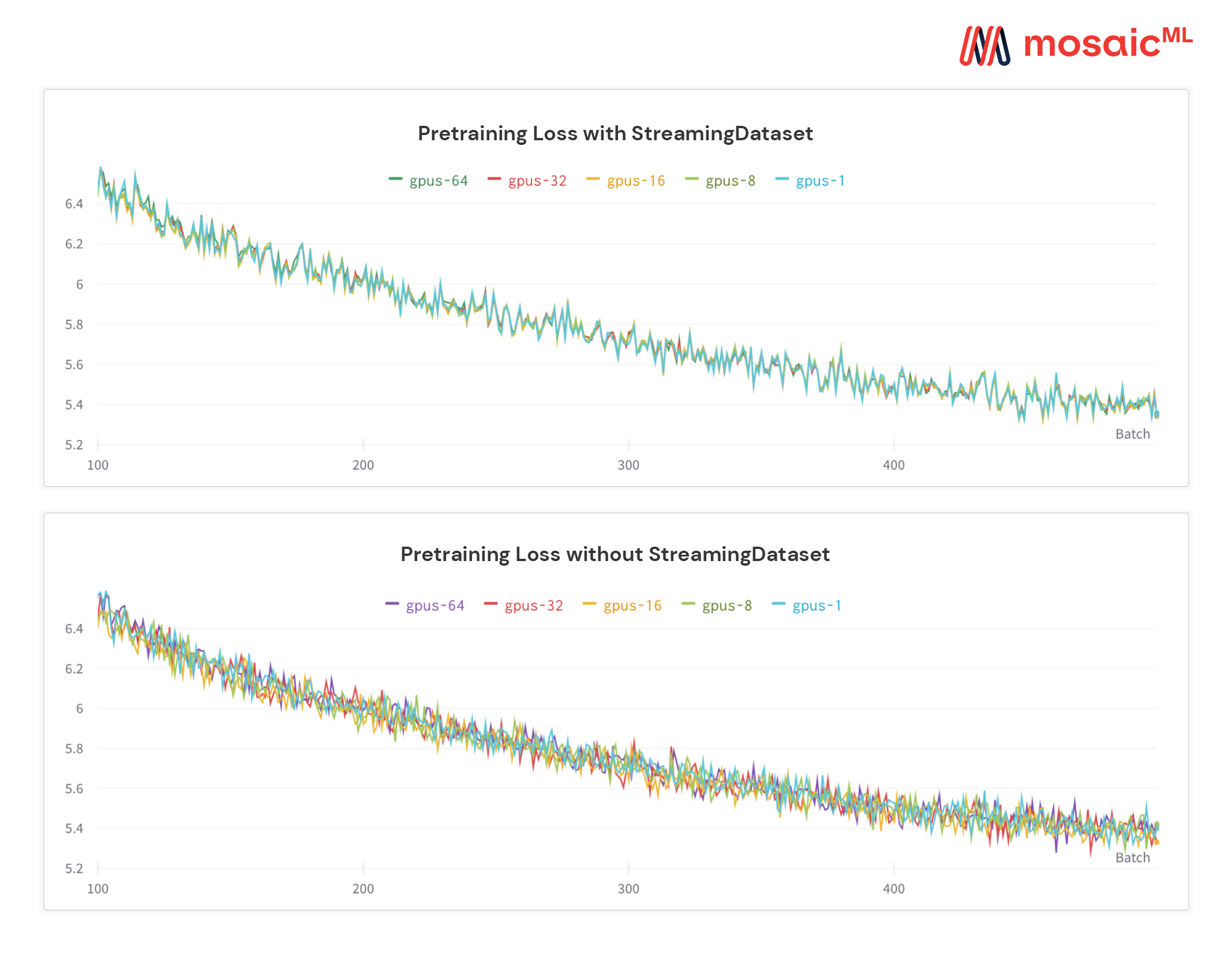
Ini bisa mahal - dan menjengkelkan - untuk menunggu pekerjaan Anda dilanjutkan saat Dataloader Anda berputar setelah kegagalan perangkat keras atau lonjakan kerugian. Berkat pemesanan sampel deterministik kami, StreamingDataset memungkinkan Anda melanjutkan pelatihan dalam hitungan detik, bukan jam, di tengah pelatihan panjang.
Meminimalkan latensi resumsi dapat menghemat ribuan dolar dalam biaya jalan keluar dan waktu komputasi GPU yang menganggur dibandingkan dengan solusi yang ada.
Format MDS kami memotong pekerjaan asing ke tulang, menghasilkan latensi sampel ultra-rendah dan throughput yang lebih tinggi dibandingkan dengan alternatif untuk beban kerja yang dijatuhkan oleh Dataloader.
| Alat | Throughput |
|---|---|
| StreamingDataset | ~ 19000 img/dtk |
| Imagefolder | ~ 18000 img/dtk |
| WebDataset | ~ 16000 img/detik |
Hasil yang ditunjukkan adalah dari pelatihan ImageNet + ResNet-50, dikumpulkan lebih dari 5 pengulangan setelah data di-cache setelah zaman pertama.
Model konvergensi dari menggunakan streamingDataset sama baiknya dengan menggunakan disk lokal, berkat algoritma pengocok kami.
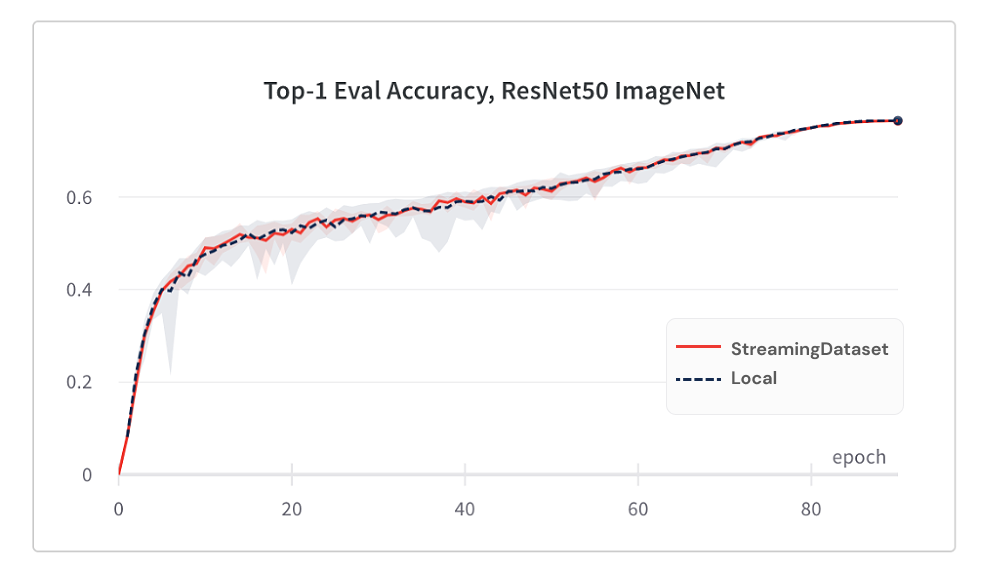
Di bawah ini adalah hasil dari pelatihan ImageNet + ResNet-50, dikumpulkan lebih dari 5 pengulangan.
| Alat | Akurasi Top-1 |
|---|---|
| StreamingDataset | 76,51% +/- 0,09 |
| Imagefolder | 76,57% +/- 0,10 |
| WebDataset | 76,23% +/- 0,17 |
StreamingDataset mengocok di semua sampel yang ditugaskan ke sebuah node, sedangkan solusi alternatif hanya mengocok sampel dalam kumpulan yang lebih kecil (dalam satu proses). Mengocok di kolam yang lebih luas menyebarkan sampel yang berdekatan lebih banyak. Selain itu, algoritma pengocok kami meminimalkan sampel yang dijatuhkan. Kami telah menemukan kedua fitur pengocok ini menguntungkan untuk konvergensi model.
Akses data yang Anda butuhkan saat Anda membutuhkannya.
Bahkan jika sampel belum diunduh, Anda dapat mengakses dataset[i] untuk mendapatkan sampel i . Unduhan akan segera dimulai dan hasilnya akan dikembalikan ketika selesai - mirip dengan dataset pytorch gaya peta dengan sampel bernomor secara berurutan dan dapat diakses dalam urutan apa pun.
dataset = streamingDataset (...) sampel = dataset [19543]
StreamingDataset akan dengan senang hati mengulangi sejumlah sampel. Anda tidak perlu menghapus sampel selamanya sehingga dataset dapat dibagi atas sejumlah perangkat yang dipanggang. Sebaliknya, setiap zaman pilihan sampel yang berbeda diulang (tidak ada yang dijatuhkan) sehingga setiap perangkat memproses jumlah yang sama.
dataset = streamingDataSet (...) dl = datasoader (dataset, num_workers = ...)
Hapus secara dinamis baru -baru ini Shards digunakan untuk menjaga penggunaan disk di bawah batas yang ditentukan. Ini diaktifkan dengan mengatur argumen streamingDataset cache_limit . Lihat Panduan Mengerap untuk lebih detail.
dataset = StreamingDataset( cache_limit='100gb', ... )
Berikut adalah beberapa proyek dan eksperimen yang menggunakan streamingDataset. Punya sesuatu untuk ditambahkan? Email [email protected] atau bergabunglah dengan Slack komunitas kami.
Biomedlm: Model bahasa besar spesifik domain untuk biomedis oleh mosaicml dan stanford crfm
Model Difusi Mosaik: Pelatihan Difusi Stabil dari Biaya Gores <$ 160K
Mosaic LLMS: Kualitas GPT-3 untuk <$ 500k
Mosaic Resnet: Pelatihan penglihatan komputer yang sangat cepat dengan resnet dan komposer mosaik
DEEPLABV3 MOSAIC: 5x pelatihan segmentasi gambar yang lebih cepat dengan resep mosaicml
… Lainnya akan datang! Pantau terus!
Kami menyambut setiap kontribusi, permintaan tarik, atau masalah.
Untuk mulai berkontribusi, lihat halaman kontribusi kami.
PS: Kami sedang merekrut!
Jika Anda menyukai proyek ini, beri kami bintang dan periksa proyek kami yang lain:
Komposer - Perpustakaan Pytorch modern yang membuat pelatihan jaringan saraf yang dapat diskalakan dan efisien mudah
Contoh MosaiCML - Contoh referensi untuk pelatihan model ML dengan cepat dan akurasi tinggi - menampilkan kode starter untuk model bahasa GPT / besar, difusi stabil, Bert, resnet -50, dan deeplabv3
MosaiCML Cloud -Platform pelatihan kami yang dibangun untuk meminimalkan biaya pelatihan untuk LLM, model difusi, dan model besar lainnya-menampilkan orkestrasi multi-cloud, penskalaan multi-node yang mudah, dan optimisasi di bawah tuduhan untuk mempercepat waktu pelatihan
@misc{mosaicml2022streaming,
author = {The Mosaic ML Team},
title = {streaming},
year = {2022},
howpublished = {url{<https://github.com/mosaicml/streaming/>}},
} 

