Huawei UK University Challenge Competition 2021
1.0.0

Presenter Tim: Kahraman Kostas
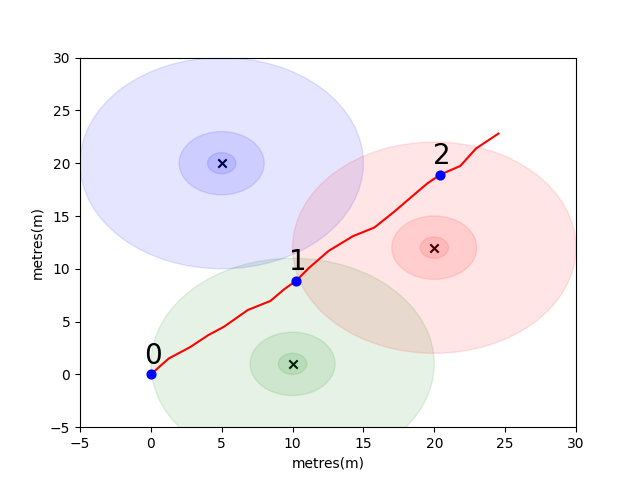
Untuk memulai Anda, kami telah mengumpulkan masalah sederhana untuk memperkenalkan beberapa konsep penentuan posisi indoor utama. Pertimbangkan lingkungan berikut: Pengguna bepergian di ruang terbuka di hadapan 3 penghasil wifi (kami menyebut data yang dibuat oleh pengguna ini lintasan). Setiap emitor memiliki alamat MAC yang unik. Pengguna dilengkapi dengan smartphone yang secara berkala akan memindai lingkungan WiFi dan merekam RSSI dari masing -masing Mac yang terdeteksi (dalam DB).
Untuk model ini kami telah menggunakan model propagasi ruang-bebas-log standar untuk masing-masing emitor. Ini adalah model sederhana yang bekerja dengan baik di ruang bebas, tetapi rusak di lingkungan indoor nyata dengan dinding dan hambatan lain yang dapat memantul sinyal di sekitar dengan cara yang lebih kompleks. Secara umum kami berharap untuk melihat penurunan tajam pada RSSI dari jarak karena energi tetap dari antena pemancar tersebar di area yang meningkat saat gelombang merambat. Dalam diagram di bawah setiap lingkaran menunjukkan setetes 10dB.
Pengguna berjalan di timur laut dari titik (0,0) dan ada telepon yang membuat tiga pemindaian lingkungan. Data yang direkam pada setiap pemindaian ditunjukkan di bawah ini.
scan 0 -> {'green': -60, 'blue': -66, 'red': -67}
scan 1 -> {'green': -58, 'blue': -61, 'red': -60}
scan 2 -> {'green': -66, 'blue': -62, 'red': -59}
Sifat -sifat kompleks dan unik lokal dari lingkungan WiFi membuatnya sangat berguna untuk sistem penentuan posisi dalam ruangan. Misalnya dalam scan 1 di bawah ini mengukur data pada kira -kira centroid dari tiga emitor dan tidak ada tempat lain di lingkungan ini di mana orang dapat mengambil bacaan yang akan mendaftarkan nilai RSSI yang serupa. Mengingat serangkaian pemindaian atau "sidik jari" dari lintasan independen, kami tertarik untuk menghitung seberapa mirip mereka dalam ruang wifi karena ini merupakan indikasi seberapa dekat mereka dalam ruang nyata.
Tantangan pertama Anda adalah menulis fungsi untuk menghitung jarak Euclidean dan metrik jarak Manhattan antara masing -masing pemindaian dalam lintasan sampel yang kami perkenalkan di atas. Menggunakan data dari lintasan tunggal adalah cara yang baik untuk menguji kualitas metrik kesamaan karena kami bisa mendapatkan perkiraan yang cukup akurat dari jarak yang sebenarnya menggunakan data dari unit pengukuran interial ponsel (IMU) yang digunakan oleh perhitungan mati pejalan kaki pejalan kaki pejalan kaki pejalan kaki pejalan kaki (PDR) modul.
def euclidean ( fp1 , fp2 ):
raise NotImplementedError
def manhattan ( fp1 , fp2 ):
raise NotImplementedError # solution of the above functions
from scipy . spatial import distance
def euclidean ( fp1 , fp2 ):
fp1 = list ( fp1 . values ())
fp2 = list ( fp2 . values ())
return distance . euclidean ( fp1 , fp2 )
def manhattan ( fp1 , fp2 ):
fp1 = list ( fp1 . values ())
fp2 = list ( fp2 . values ())
return distance . cityblock ( fp1 , fp2 ) import json
import numpy as np
import matplotlib . pyplot as plt
from metrics import eval_dist_metric
with open ( "intro_trajectory_1.json" ) as f :
traj = json . load ( f )
## Pre-calculate the pair indexes we are interested in
keys = []
for fp1 in traj [ 'fps' ]:
for fp2 in traj [ 'fps' ]:
# only calculate the upper triangle
if fp1 [ 'step_index' ] > fp2 [ 'step_index' ]:
keys . append (( fp1 [ 'step_index' ], fp2 [ 'step_index' ]))
## Get the distances from PDR
true_d = {}
for step1 in traj [ 'steps' ]:
for step2 in traj [ 'steps' ]:
key = ( step1 [ 'step_index' ], step2 [ 'step_index' ])
if key in keys :
true_d [ key ] = abs ( step1 [ 'di' ] - step2 [ 'di' ])
euc_d = {}
man_d = {}
for fp1 in traj [ 'fps' ]:
for fp2 in traj [ 'fps' ]:
key = ( fp1 [ 'step_index' ], fp2 [ 'step_index' ])
if key in keys :
euc_d [ key ] = euclidean ( fp1 [ 'profile' ], fp2 [ 'profile' ])
man_d [ key ] = manhattan ( fp1 [ 'profile' ], fp2 [ 'profile' ])
print ( "Euclidean Average Error" )
print ( f' { eval_dist_metric ( euc_d , true_d ):.2f } ' )
print ( "Manhattan Average Error" )
print ( f' { eval_dist_metric ( man_d , true_d ):.2f } ' ) Euclidean Average Error
9.29
Manhattan Average Error
4.90
Jika Anda menerapkan fungsi dengan benar, Anda seharusnya melihat bahwa kesalahan rata -rata untuk metrik Euclidean adalah 9.29 sementara Manhattan hanya 4.90 . Jadi untuk data ini, jarak Manhattan adalah perkiraan jarak yang lebih baik.
Ini tentu saja model yang sangat sederhana. Memang, tidak ada hubungan langsung antara nilai -nilai RSSI dan jarak ruang bebas dengan cara ini. Biasanya, ketika kami membuat estimasi kami sendiri untuk jarak, kami akan menggunakan jarak PDR yang diketahui dari dalam lintasan agar sesuai dengan skor numerik dengan perkiraan jarak fisik.
Untuk tantangan utama Anda, kami ingin Anda mengembangkan metrik Anda sendiri untuk memperkirakan jarak dunia nyata antara dua pemindaian, hanya berdasarkan sidik jari wifi mereka. Kami akan memberi Anda data crowdsourced nyata yang dikumpulkan pada awal tahun 2021 dari satu mal. Data akan berisi sidik jari 114661 dan jarak 879824 antara pemindaian. Jarak akan menjadi perkiraan terbaik kami tentang jarak sebenarnya yang diberikan informasi tambahan yang akan kami pertimbangkan.
Kami akan memberikan satu set tes pasangan sidik jari dan Anda perlu menulis fungsi yang memberi tahu kami seberapa jauh mereka.
Fungsi ini bisa sesederhana variasi pada salah satu metrik yang kami perkenalkan di atas atau serumit solusi pembelajaran mesin penuh yang belajar untuk menimbang alamat MAC yang berbeda (atau kombinasi alamat MAC) secara berbeda dalam situasi yang berbeda.
Beberapa poin akhir yang perlu dipertimbangkan:
Data dirakit sebagai tiga file untuk Anda.
task1_fingerprints.json berisi semua informasi sidik jari untuk masalah tersebut. Itu adalah masing -masing entri merupakan pemindaian nyata dari wifi emitter di area mal. Anda akan menemukan bahwa alamat MAC yang sama akan ada di banyak sidik jari.
task1_train.csv berisi pasangan pelatihan yang valid untuk membantu Anda merancang/melatih algoritma Anda. Setiap pasangan id1-id2 memiliki jarak kebenaran tanah berlabel (dalam meter) dan setiap ID sesuai dengan sidik jari dari task1_fingerprints.json .
task1_test.csv adalah format yang sama dengan task1_train.csv tetapi tidak memiliki perpindahan yang disertakan. Inilah yang kami ingin Anda prediksi menggunakan informasi sidik jari mentah.
import csv
import json
import os
from tqdm import tqdm
path_to_data = "for_contestants"
with open ( os . path . join ( path_to_data , "task1_fingerprints.json" )) as f :
fps = json . load ( f )
with open ( os . path . join ( path_to_data , "task1_train.csv" )) as f :
train_data = []
train_h = csv . DictReader ( f )
for pair in tqdm ( train_h ):
train_data . append ([ pair [ 'id1' ], pair [ 'id2' ], float ( pair [ 'displacement' ])])
with open ( os . path . join ( path_to_data , "task1_test.csv" )) as f :
test_h = csv . DictReader ( f )
test_ids = []
for pair in tqdm ( test_h ):
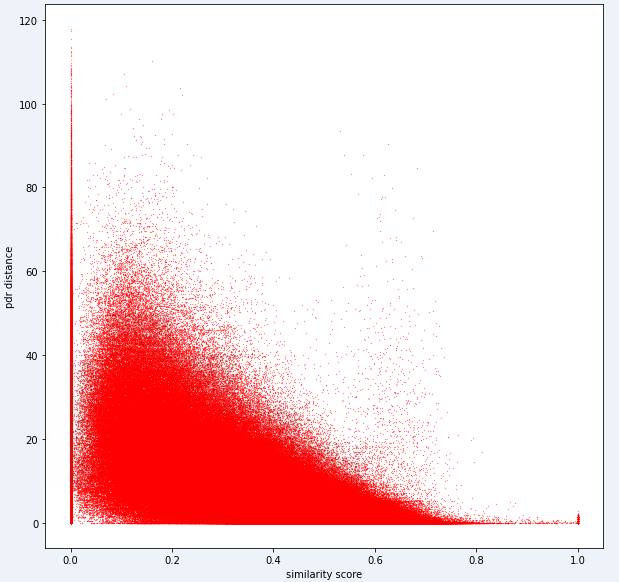
test_ids . append ([ pair [ 'id1' ], pair [ 'id2' ]])Pada akhirnya, model yang ideal harus dapat menemukan pemetaan yang tepat antara ruang sidik jari yang sangat dimensi (1 sidik jari dapat berisi banyak pengukuran) dan ruang jarak 1 dimensi. Dapat berguna untuk memplot jarak PDR (dari data pelatihan) terhadap beberapa metrik kesamaan yang dihitung untuk melihat apakah metrik mengungkapkan tren yang jelas. Kesamaan tinggi harus berkorelasi dengan jarak rendah.
Di bawah ini adalah metrik satu jarak yang kami gunakan secara internal untuk tugas ini. Anda dapat melihat bahwa bahkan untuk metrik ini, kami memiliki banyak kebisingan.
Karena tingkat kebisingan ini, metrik penilaian kami untuk Tugas 1 akan bias terhadap presisi atas penarikan
Pengajuan Anda harus menggunakan ID yang tepat dari file test1_test.csv dan harus mengisi kolom perpindahan ketiga (saat ini kosong) dengan perkiraan jarak Anda (dalam meter) untuk pasangan sidik jari itu.
def my_distance_function ( fp1 , fp2 ):
raise NotImplementedError output_data = [[ "id1" , "id2" , "displacement" ]]
for id1 , id2 in tqdm ( test_ids ):
fp1 = fps [ id1 ]
fp2 = fps [ id2 ]
distance_estimate = my_distance_function ( fp1 , fp2 )
output_data . append ([ id1 , id2 , distance_estimate ])
with open ( "MySubmission.csv" , "w" , newline = '' ) as f :
writer = csv . writer ( f )
writer . writerows ( output_data )Langkah -langkah dalam tugas pertama dapat diringkas sebagai berikut.
Langkah -langkah ini diilustrasikan pada gambar di bawah ini.

Kami menggunakan Python 3.6.5 untuk membuat file aplikasi. Kami menyertakan beberapa modul tambahan yang tidak termasuk dalam file contoh yang diberikan pada awal kompetisi. Modul -modul ini dapat terdaftar sebagai:
| Molulat | Tugas |
|---|---|
| Tensorflow | Pembelajaran yang mendalam |
| Panda | Analisis Data |
| SCIPY | Komputasi Jarak |
Kami mulai dengan pemasangan modul ini sebagai langkah pertama.
## 1.1 Installing modules
!p ip install tensorflow == 2.6 . 2
!p ip install scipy
!p ip install pandas Pada langkah ini, kami memperbaiki benih acak terkait yang akan digunakan untuk mendapatkan hasil yang dapat diulang. Dengan cara ini, kami telah memberikan jalur deterministik di mana kami mendapatkan hasil yang sama dalam setiap proses. Namun, menurut pengamatan kami, hasil yang diperoleh dengan komputer yang berbeda mungkin sedikit berbeda (± 1%)
## 1.2 Setting Random Seeds
seed_value = 0
import os
os . environ [ 'PYTHONHASHSEED' ] = str ( seed_value )
import random
random . seed ( seed_value )
import numpy as np
np . random . seed ( seed_value )
import tensorflow as tf
tf . random . set_seed ( seed_value )
import tensorflow as tf
session_conf = tf . compat . v1 . ConfigProto ( intra_op_parallelism_threads = 1 , inter_op_parallelism_threads = 1 )
sess = tf . compat . v1 . Session ( graph = tf . compat . v1 . get_default_graph (), config = session_conf ) Di bagian ini, kami memuat data yang akan kami gunakan. Kami mengambil kode dan penjelasan dari file sampel yang diberikan ( Task1-IPS-Challenge-2021.ipynb ).
task1_fingerprints.json berisi semua informasi sidik jari untuk masalah tersebut. Itu adalah masing -masing entri merupakan pemindaian nyata dari wifi emitter di area mal. Anda akan menemukan bahwa alamat MAC yang sama akan ada di banyak sidik jari.
task1_train.csv berisi pasangan pelatihan yang valid untuk membantu Anda merancang/melatih algoritma Anda. Setiap pasangan id1-id2 memiliki jarak kebenaran tanah berlabel (dalam meter) dan setiap ID sesuai dengan sidik jari dari task1_fingerprints.json .
task1_test.csv adalah format yang sama dengan task1_train.csv tetapi tidak memiliki perpindahan yang disertakan.
## 1.3 Loading the data
import csv
import json
import os
from tqdm import tqdm
path_to_data = "for_contestants"
with open ( os . path . join ( path_to_data , "task1_fingerprints.json" )) as f :
fps = json . load ( f )
with open ( os . path . join ( path_to_data , "task1_train.csv" )) as f :
train_data = []
train_h = csv . DictReader ( f )
for pair in tqdm ( train_h ):
train_data . append ([ pair [ 'id1' ], pair [ 'id2' ], float ( pair [ 'displacement' ])])
with open ( os . path . join ( path_to_data , "task1_test.csv" )) as f :
test_h = csv . DictReader ( f )
test_ids = []
for pair in tqdm ( test_h ):
test_ids . append ([ pair [ 'id1' ], pair [ 'id2' ]]) 879824it [05:16, 2778.31it/s]
5160445it [01:00, 85269.27it/s]
Pada langkah ini, kami melakukan ekstraksi fitur menggunakan dua fungsi. Fungsi feature_extraction_file cukup menarik nilai yang relevan dari sidik jari (berpasangan) dari file JSON dan mengirimkannya ke fungsi feature_extraction untuk melakukan perhitungan.
Dalam fungsi feature_extraction , jika kedua sidik jari ini berbeda satu sama lain dalam hal ukuran dan perangkat yang dikandungnya, semua perangkat yang termasuk dalam dua sidik jari disatukan untuk membentuk urutan umum tanpa mengulangi. Di setiap array, kami membuat dua array ini identik (dalam hal perangkat yang mereka sertakan) dengan menetapkan nilai 0 ke perangkat yang tidak sesuai. Proses ini dijelaskan dengan contoh pada gambar berikut.
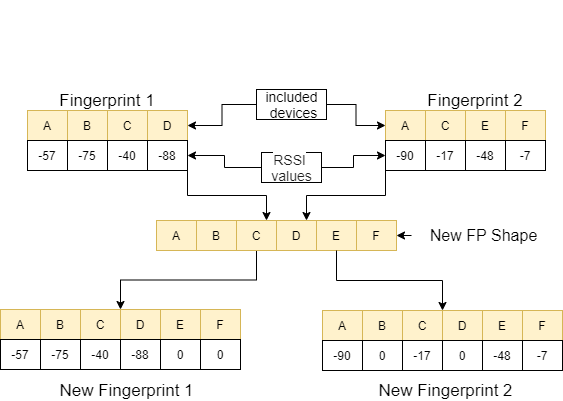
Jarak antara kedua sidik jari ini, yang dibuat serupa, dihitung menggunakan 11 metode berbeda [1]. Metode ini adalah:
Kemudian, nilai -nilai ini diarahkan ke fungsi feature_extraction_file dan disimpan sebagai file CSV dalam fungsi ini. Dengan kata lain, sidik jari dari berbagai ukuran berubah menjadi file CSV 11-fitur sebagai hasil dari proses ini. Model yang akan digunakan dilatih dan diuji dengan fitur yang baru dibuat ini.
## 1.4 Feature Extraction
def feature_extraction_file ( data , name , flag ):
features = [[ "braycurtis" ,
"canberra" ,
"chebyshev" ,
"cityblock" ,
"correlation" ,
"cosine" ,
"euclidean" ,
"jensenshannon" ,
"minkowski" ,
"sqeuclidean" ,
"wminkowski" , "real" ]]
for i in tqdm (( data ), position = 0 , leave = True ):
fp1 = fps [ i [ 0 ]]
fp2 = fps [ i [ 1 ]]
feature = feature_extraction ( fp1 , fp2 )
if flag :
feature . append ( i [ 2 ])
else : feature . append ( 0 )
features . append ( feature )
with open ( name , "w" , newline = '' ) as f :
writer = csv . writer ( f )
writer . writerows ( features )
#print(features) ## 1.4 Feature Extraction
def feature_extraction ( fp1 , fp2 ):
mac = set ( list ( fp1 . keys ()) + list ( fp2 . keys ()))
mac = { i : 0 for i in mac }
f1 = mac . copy ()
f2 = mac . copy ()
for key in fp1 :
f1 [ key ] = fp1 [ key ]
for key in fp2 :
f2 [ key ] = fp2 [ key ]
f1 = list ( f1 . values ())
f2 = list ( f2 . values ())
braycurtis = scipy . spatial . distance . braycurtis ( f1 , f2 )
canberra = scipy . spatial . distance . canberra ( f1 , f2 )
chebyshev = scipy . spatial . distance . chebyshev ( f1 , f2 )
cityblock = scipy . spatial . distance . cityblock ( f1 , f2 )
correlation = scipy . spatial . distance . correlation ( f1 , f2 )
cosine = scipy . spatial . distance . cosine ( f1 , f2 )
euclidean = scipy . spatial . distance . euclidean ( f1 , f2 )
jensenshannon = scipy . spatial . distance . jensenshannon ( f1 , f2 )
minkowski = scipy . spatial . distance . minkowski ( f1 , f2 )
sqeuclidean = scipy . spatial . distance . sqeuclidean ( f1 , f2 )
wminkowski = scipy . spatial . distance . wminkowski ( f1 , f2 , 1 , np . ones ( len ( f1 )))
output_data = [ braycurtis ,
canberra ,
chebyshev ,
cityblock ,
correlation ,
cosine ,
euclidean ,
jensenshannon ,
minkowski ,
sqeuclidean ,
wminkowski ]
output_data = [ 0 if x != x else x for x in output_data ]
return output_data Dalam tugas ini, ada pemindaian sidik jari yang memiliki sinyal RRSI dari lingkungan pemancar wifi di mal. First Challange ingin kita memperkirakan jarak antara dua pemindaian sidik jari yang merupakan tugas regresi. Kami menggunakan Ann (jaringan saraf buatan) yang terinspirasi oleh jaringan saraf biologis. Ann terdiri dari tiga lapisan; Lapisan input, lapisan tersembunyi (lebih dari satu) dan lapisan output. JST dimulai dengan lapisan input yang mencakup data pelatihan (dengan fitur), meneruskan data ke lapisan tersembunyi pertama di mana data dihitung oleh bobot lapisan tersembunyi pertama. Di lapisan tersembunyi, ada iterasi perhitungan bobot pada input dan kemudian menerapkannya fungsi aktivasi [2]. Karena masalah kita adalah regresi, lapisan terakhir kita adalah neuron output tunggal: outputnya adalah diprediksi jarak antara pasangan pemindaian sidik jari. Lapisan tersembunyi pertama kami memiliki 64 dan yang kedua memiliki 128 neuron. Semua arsitektur model ini dibagikan sebagai berikut. 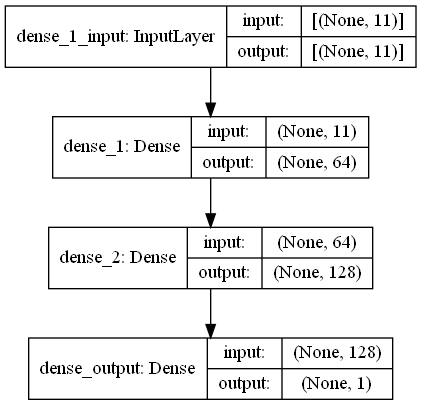
Kami melakukan pembelajaran mendalam menggunakan dua fungsi. Fungsi create_model membentuk data pelatihan untuk melatih model dan menentukan struktur model. Fungsi model_features menghasilkan model dengan struktur yang ditentukan. Model yang dibuat disimpan untuk digunakan setelah dilatih oleh fungsi create_model .
## 1.5 Model
import scipy . spatial
import pandas as pd
import numpy as np
import matplotlib . pyplot as plt
from tensorflow import keras
from tensorflow . keras . models import Sequential
from tensorflow . keras . layers import Dense
#from keras.utils.vis_utils import plot_model
% matplotlib inline
def model_features ( i , ii ):
model = Sequential ()
model . add ( Dense ( i , input_shape = ( 11 , ), activation = 'relu' , name = 'dense_1' ))
model . add ( Dense ( ii , activation = 'relu' , name = 'dense_2' ))
model . add ( Dense ( 1 , activation = 'linear' , name = 'dense_output' ))
model . compile ( optimizer = 'adam' , loss = 'mse' , metrics = [ 'mae' ])
model . summary ()
#plot_model(model, to_file='model_plot.png', show_shapes=True, show_layer_names=True)
#print(model.get_config())
return model
def create_model ( name ):
df = pd . read_csv ( name )
df . replace ([ np . inf , - np . inf ], np . nan , inplace = True )
df = df . fillna ( 0 )
X = df [ df . columns [ 0 : - 1 ]]
X_train = np . array ( X )
y_train = np . array ( df [ df . columns [ - 1 ]])
model = model_features ( 64 , 128 )
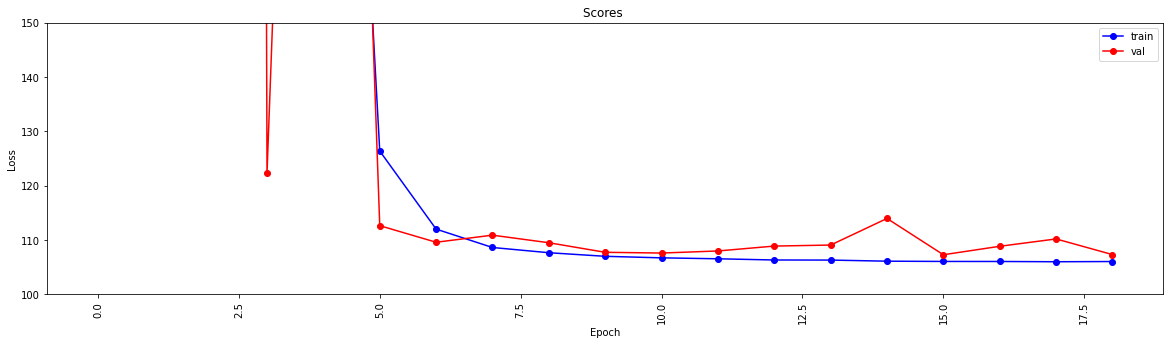
history = model . fit ( X_train , y_train , epochs = 19 , validation_split = 0.5 ) #,batch_size=1)
loss = history . history [ 'loss' ]
val_loss = history . history [ 'val_loss' ]
my_xticks = list ( range ( len ( loss )))
plt . figure ( figsize = ( 20 , 5 ))
plt . plot ( my_xticks , loss , linestyle = '-' , marker = 'o' , color = 'b' , label = "train" )
plt . plot ( my_xticks , val_loss , linestyle = '-' , marker = 'o' , color = 'r' , label = "val" )
plt . title ( "Scores " )
plt . legend ( numpoints = 1 )
plt . ylabel ( "Loss" )
plt . xlabel ( "Epoch" )
plt . xticks ( rotation = 90 )
plt . ylim ([ 100 , 150 ])
plt . show ()
madelname = "./THEMODEL"
model . save ( madelname )
print ( "Model Created!" )
Fungsi ini memeriksa apakah data pelatihan dan pengujian telah melalui ekstraksi fitur. Jika belum, itu membuat file -file ini dan model dengan memanggil fungsi yang sesuai. Setelah menangani model dan semua ekstraksi fitur, ia memformat data uji untuk menghasilkan hasil akhir.
## 1.6 Checking the inputs
from numpy import inf
from numpy import nan
def create_new_files ( train , test ):
model_path = "./THEMODEL/"
my_train_file = 'new_train_features.csv'
my_test_file = 'new_test_features.csv'
if os . path . isfile ( my_train_file ) :
pass
else :
print ( "Please wait! Training data feature extraction is in progress... n it will take about 10 minutes" )
feature_extraction_file ( train , my_train_file , 1 )
print ( "TThe training feature extraction completed!!!" )
if os . path . isfile ( my_test_file ) :
pass
else :
print ( "Please wait! Testing data feature extraction is in progress... n it will take about 100-120 minutes" )
feature_extraction_file ( test , my_test_file , 0 )
print ( "The testing feature extraction completed!!!" )
if os . path . isdir ( model_path ):
pass
else :
print ( "Please wait! Creating the deep learning model... n it will take about 10 minutes" )
create_model ( my_train_file )
print ( "The model file created!!! n n n " )
model = keras . models . load_model ( model_path )
df = pd . read_csv ( my_test_file )
df . replace ([ np . inf , - np . inf ], np . nan , inplace = True )
df = df . fillna ( 0 )
X_train = df [ df . columns [ 0 : - 1 ]]
X_train = np . array ( X_train )
y_train = np . array ( df [ df . columns [ - 1 ]])
predicted = model . predict ( X_train )
print ( "Please wait! Creating resuşts... " )
return predicted Langkah ini memicu ekstraksi fitur dan proses pembuatan model dan memungkinkan semua proses dimulai. Jadi, menggunakan ID dari file test1_test.csv itu mengisi kolom ketiga (perpindahan) dengan perkiraan jarak untuk pasangan sidik jari ini dan menyimpan file ini di direktori dengan nama TASK1-MySubmission.csv .
## 1.7 Submission
distance_estimate = create_new_files ( train_data , test_ids )
count = 0
output_data = [[ "id1" , "id2" , "displacement" ]]
for id1 , id2 in tqdm ( test_ids ):
output_data . append ([ id1 , id2 , distance_estimate [ count ][ 0 ]])
count += 1
print ( "Process finished. Preparing result file ..." )
with open ( "TASK1-MySubmission.csv" , "w" , newline = '' ) as f :
writer = csv . writer ( f )
writer . writerows ( output_data )
print ( "The results are ready. n See MySubmission.csv" ) Please wait! Creating the deep learning model...
it will take about 10 minutes
Model: "sequential_3"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_1 (Dense) (None, 64) 768
_________________________________________________________________
dense_2 (Dense) (None, 128) 8320
_________________________________________________________________
dense_output (Dense) (None, 1) 129
=================================================================
Total params: 9,217
Trainable params: 9,217
Non-trainable params: 0
_________________________________________________________________
Epoch 1/19
13748/13748 [==============================] - 30s 2ms/step - loss: 2007233.6250 - mae: 161.3013 - val_loss: 218.8822 - val_mae: 11.5630
Epoch 2/19
13748/13748 [==============================] - 27s 2ms/step - loss: 24832.6309 - mae: 53.9385 - val_loss: 123437.0859 - val_mae: 307.2885
Epoch 3/19
13748/13748 [==============================] - 26s 2ms/step - loss: 4028.0859 - mae: 29.9960 - val_loss: 3329.2024 - val_mae: 49.9126
Epoch 4/19
13748/13748 [==============================] - 27s 2ms/step - loss: 904.7919 - mae: 17.6284 - val_loss: 122.3358 - val_mae: 6.8169
Epoch 5/19
13748/13748 [==============================] - 25s 2ms/step - loss: 315.7050 - mae: 11.9098 - val_loss: 404.0973 - val_mae: 15.2033
Epoch 6/19
13748/13748 [==============================] - 26s 2ms/step - loss: 126.3843 - mae: 7.8173 - val_loss: 112.6499 - val_mae: 7.6804
Epoch 7/19
13748/13748 [==============================] - 27s 2ms/step - loss: 112.0149 - mae: 7.4220 - val_loss: 109.5987 - val_mae: 7.1964
Epoch 8/19
13748/13748 [==============================] - 26s 2ms/step - loss: 108.6342 - mae: 7.3271 - val_loss: 110.9016 - val_mae: 7.6862
Epoch 9/19
13748/13748 [==============================] - 26s 2ms/step - loss: 107.6721 - mae: 7.2827 - val_loss: 109.5083 - val_mae: 7.5235
Epoch 10/19
13748/13748 [==============================] - 27s 2ms/step - loss: 107.0110 - mae: 7.2290 - val_loss: 107.7498 - val_mae: 7.1105
Epoch 11/19
13748/13748 [==============================] - 29s 2ms/step - loss: 106.7296 - mae: 7.2158 - val_loss: 107.6115 - val_mae: 7.1178
Epoch 12/19
13748/13748 [==============================] - 26s 2ms/step - loss: 106.5561 - mae: 7.2039 - val_loss: 107.9937 - val_mae: 6.9932
Epoch 13/19
13748/13748 [==============================] - 26s 2ms/step - loss: 106.3344 - mae: 7.1905 - val_loss: 108.8941 - val_mae: 7.4530
Epoch 14/19
13748/13748 [==============================] - 27s 2ms/step - loss: 106.3188 - mae: 7.1927 - val_loss: 109.0832 - val_mae: 7.5309
Epoch 15/19
13748/13748 [==============================] - 27s 2ms/step - loss: 106.1150 - mae: 7.1829 - val_loss: 113.9741 - val_mae: 7.9496
Epoch 16/19
13748/13748 [==============================] - 26s 2ms/step - loss: 106.0676 - mae: 7.1788 - val_loss: 107.2984 - val_mae: 7.2192
Epoch 17/19
13748/13748 [==============================] - 27s 2ms/step - loss: 106.0614 - mae: 7.1733 - val_loss: 108.8553 - val_mae: 7.4640
Epoch 18/19
13748/13748 [==============================] - 28s 2ms/step - loss: 106.0113 - mae: 7.1790 - val_loss: 110.2068 - val_mae: 7.6562
Epoch 19/19
13748/13748 [==============================] - 27s 2ms/step - loss: 106.0519 - mae: 7.1791 - val_loss: 107.3276 - val_mae: 7.0981
INFO:tensorflow:Assets written to: ./THEMODELassets
Model Created!
The model file created!!!
Please wait! Creating resuşts...
100%|████████████████████████████████████████████████████████████████████| 5160445/5160445 [00:08<00:00, 610910.29it/s]
Process finished. Preparing result file ...
The results are ready.
See MySubmission.csv
Mengingat bahwa kami sekarang memiliki metrik untuk mengevaluasi jarak wifi tugas kami berikutnya adalah memisahkan lintasan dari mal (mal yang berbeda dengan yang digunakan dalam tantangan pertama!) Ke lantai terpisah tempat mereka berada. Anda dapat melakukan ini dengan cara yang berbeda , tetapi kami akan sangat menyarankan pendekatan grafik pengelompokan.
Pertimbangkan setiap sidik jari wifi dalam data sebagai node dalam grafik dan bahwa kita dapat membentuk tepi dengan sidik jari lain dalam grafik dengan mengevaluasi kesamaan dua sidik jari. Kami dapat memberikan bobot tinggi ke tepi di mana kami memiliki kesamaan tinggi antara sidik jari dan bobot rendah (atau tidak ada tepi) antara yang tidak serupa. Secara teori, metrik kesamaan yang sangat akurat akan memisahkan lantai yang sepele karena kami dapat mengecualikan semua tepi yang lebih besar dari sekitar 4 meter (kira -kira ketinggian 1 lantai bangunan). Pada kenyataannya ada kemungkinan bahwa kita akan membuat tepi yang salah di antara lantai dan kita perlu entah bagaimana mematahkan tepi ini.
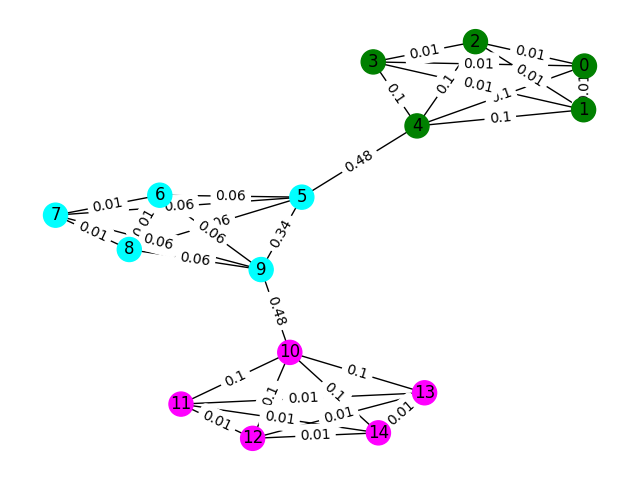
Mari kita mulai dengan contoh sederhana. Pertimbangkan grafik di bawah ini di mana warna node menunjukkan klasifikasi lantai yang sebenarnya dari sidik jari dan ujung -ujungnya mencerminkan bahwa kami percaya node -node ini ada di lantai yang sama. Untuk latihan ini, kami telah melakukan pra-berlabel di setiap tepi dengan "Skor Antara", sebuah metrik yang menghitung berapa kali tepi ini berjalan dengan mengambil jalan terpendek antara dua node dalam grafik. Biasanya, ini akan mengungkapkan tepi yang menunjukkan konektivitas tinggi dan mungkin kandidat untuk dihapus.
Dalam contoh ini, gunakan skor tepi-antara untuk mendeteksi komunikasi grafik. Kembalikan daftar daftar di mana masing -masing sublist berisi id node komunitas. Perhatikan ini hanya untuk membantu pemahaman Anda tentang masalah dan tidak diperhitungkan untuk solusi yang sebenarnya.
def detect_communities ( Graph ):
## This function should return a list of lists containing
## the node ids of the communities that you have detected.
eb_score = nx . edge_betweenness_centrality ( G )
raise NotImplementedError import networkx as nx
from metrics import check_result
G = nx . read_adjlist ( "graph.adjlist" )
communities = detect_communities ( G )
if check_result ( communities ):
print ( "Correct!" )
else :
print ( "Try again" ) Data pelatihan sampel untuk masalah ini adalah satu set 106981 sidik jari ( task2_train_fingerprints.json ) dan beberapa tepi di antara mereka. Kami telah menyediakan file yang menunjukkan tiga jenis tepi yang berbeda, yang semuanya harus diperlakukan secara berbeda.
task2_train_steps.csv menunjukkan tepi yang menghubungkan langkah -langkah selanjutnya dalam lintasan. Tepi ini harus sangat dipercaya karena menunjukkan kepastian bahwa dua sidik jari dicatat dari lantai yang sama.
task2_train_elevations.csv menunjukkan kebalikan dari langkah -langkah. Ketinggian ini menunjukkan bahwa sidik jari hampir pasti dari lantai yang berbeda. Dengan demikian Anda dapat mengekstrapolasi jika sidik jari
task2_train_estimated_wifi_distances.csv adalah jarak pra-komputasi yang telah kami hitung menggunakan metrik jarak kami sendiri. Metrik ini tidak sempurna dan karena itu kita tahu bahwa banyak dari tepi ini akan salah (yaitu mereka akan menghubungkan dua lantai bersama). Kami menyarankan agar Anda menggunakan tepi dalam file ini untuk membangun grafik awal Anda dan menghitung beberapa solusi. Namun, jika Anda mendapatkan skor tinggi di Task1 maka Anda dapat mempertimbangkan untuk menghitung jarak wifi Anda sendiri untuk membangun grafik.
Grafik Anda dapat berada di salah satu dari dua tingkat detail, baik level lintasan atau tingkat sidik jari, Anda dapat memilih representasi apa yang ingin Anda gunakan, tetapi pada akhirnya kami ingin mengetahui kelompok lintasan . Level lintasan akan memiliki setiap node sebagai lintasan dan tepi antara node akan terjadi jika sidik jari di lintasan mereka memiliki similiraty tinggi. Level sidik jari akan memiliki setiap sidik jari sebagai simpul. Anda dapat mencari ID lintasan sidik jari menggunakan task2_train_lookup.json untuk mengonversi antar representasi.
Untuk membantu Anda men -debug dan melatih solusi Anda, kami telah memberikan kebenaran dasar untuk beberapa lintasan di task2_train_GT.json . Dalam file ini tombol adalah ID lintasan (sama seperti di task2_train_lookup.json ) dan nilainya adalah ID lantai asli bangunan.
Set tes adalah format yang sama persis dengan set pelatihan (untuk bangunan terpisah, kami tidak akan membuatnya mudah;)) tetapi kami belum memasukkan file kebenaran tanah yang setara. Ini akan ditahan untuk memungkinkan kami mencetak solusi Anda.
Poin yang perlu dipertimbangkan
Di bagian ini kami akan memberikan beberapa kode contoh untuk membuka file dan membangun kedua jenis grafik.
import os
import json
import csv
import networkx as nx
from tqdm import tqdm
path_to_data = "task2_for_participants/train"
with open ( os . path . join ( path_to_data , "task2_train_estimated_wifi_distances.csv" )) as f :
wifi = []
reader = csv . DictReader ( f )
for line in tqdm ( reader ):
wifi . append ([ line [ 'id1' ], line [ 'id2' ], float ( line [ 'estimated_distance' ])])
with open ( os . path . join ( path_to_data , "task2_train_elevations.csv" )) as f :
elevs = []
reader = csv . DictReader ( f )
for line in tqdm ( reader ):
elevs . append ([ line [ 'id1' ], line [ 'id2' ]])
with open ( os . path . join ( path_to_data , "task2_train_steps.csv" )) as f :
steps = []
reader = csv . DictReader ( f )
for line in tqdm ( reader ):
steps . append ([ line [ 'id1' ], line [ 'id2' ], float ( line [ 'displacement' ])])
fp_lookup_path = os . path . join ( path_to_data , "task2_train_lookup.json" )
gt_path = os . path . join ( path_to_data , "task2_train_GT.json" )
with open ( fp_lookup_path ) as f :
fp_lookup = json . load ( f )
with open ( gt_path ) as f :
gt = json . load ( f )
Ini adalah salah satu cara untuk membangun grafik level sidik jari, di mana setiap node dalam grafik adalah sidik jari. Kami telah menambahkan bobot tepi yang sesuai dengan perkiraan/jarak yang benar dari tepi WiFi dan PDR masing -masing. Kami juga telah menambahkan tepi ketinggian untuk menunjukkan hubungan ini. Anda mungkin ingin secara eksplisit menegakkan bahwa tidak ada bagian tepi ini (atau tepi ketinggian yang valid di antara lintasan) saat mengembangkan solusi Anda.
G = nx . Graph ()
for id1 , id2 , dist in tqdm ( steps ):
G . add_edge ( id1 , id2 , ty = "s" , weight = dist )
for id1 , id2 , dist in tqdm ( wifi ):
G . add_edge ( id1 , id2 , ty = "w" , weight = dist )
for id1 , id2 in tqdm ( elevs ):
G . add_edge ( id1 , id2 , ty = "e" )Grafik lintasan ini bisa dibilang tidak sesederhana yang Anda butuhkan untuk memikirkan cara untuk mewakili banyak koneksi WiFi antara lintasan. Dalam contoh grafik di bawah ini kita hanya mengambil jarak rata -rata sebagai bobot, tetapi apakah ini benar -benar representasi terbaik?
B = nx . Graph ()
# Get all the trajectory ids from the lookup
valid_nodes = set ( fp_lookup . values ())
for node in valid_nodes :
B . add_node ( node )
# Either add an edge or append the distance to the edge data
for id1 , id2 , dist in tqdm ( wifi ):
if not B . has_edge ( fp_lookup [ str ( id1 )], fp_lookup [ str ( id2 )]):
B . add_edge ( fp_lookup [ str ( id1 )],
fp_lookup [ str ( id2 )],
ty = "w" , weight = [ dist ])
else :
B [ fp_lookup [ str ( id1 )]][ fp_lookup [ str ( id2 )]][ 'weight' ]. append ( dist )
# Compute the mean edge weight
for edge in B . edges ( data = True ):
B [ edge [ 0 ]][ edge [ 1 ]][ 'weight' ] = sum ( B [ edge [ 0 ]][ edge [ 1 ]][ 'weight' ]) / len ( B [ edge [ 0 ]][ edge [ 1 ]][ 'weight' ])
# If you have made a wifi connection between trajectories with an elev, delete the edge
for id1 , id2 in tqdm ( elevs ):
if B . has_edge ( fp_lookup [ str ( id1 )], fp_lookup [ str ( id2 )]):
B . remove_edge ( fp_lookup [ str ( id1 )],
fp_lookup [ str ( id2 )])Pengajuan Anda harus menjadi file CSV di mana lintasan yang Anda yakini berada di lantai yang sama memiliki indeks mereka pada baris yang sama dipisahkan oleh koma. Setiap cluster baru akan dimasukkan pada baris baru.
Misalnya, lihat entri acak di bawah ini.
import random
random_data = []
n_clusters = random . randint ( 50 , 100 )
for i in range ( 0 , n_clusters ):
random_data . append ([])
for traj in set ( fp_lookup . values ()):
cluster = random . randint ( 0 , n_clusters - 1 )
random_data [ cluster ]. append ( traj )
with open ( "MyRandomSubmission.csv" , "w" , newline = '' ) as f :
csv_writer = csv . writer ( f )
csv_writer . writerows ( random_data )Langkah -langkah dalam Tugas 2 dapat diringkas sebagai berikut:
Node2vec .TASK2-Mysubmission.csv ) disiapkan sesuai dengan lintasan ID.Langkah -langkah ini diilustrasikan pada gambar di bawah ini.

Kami menggunakan Python 3.6.5 untuk membuat file aplikasi. Kami menyertakan beberapa modul tambahan yang tidak termasuk dalam file contoh yang diberikan pada awal kompetisi. Modul -modul ini dapat terdaftar sebagai:
| Molulat | Tugas |
|---|---|
| scikit-learn | Pembelajaran Mesin & Persiapan Data |
| node2vec | Pembelajaran fitur yang dapat diskalakan untuk jaringan |
| Numpy | Operasi Matematika |
Kami mulai dengan pemasangan modul ini sebagai langkah pertama.
## 2.1 Installing modules
!p ip install node2vec
!p ip install scikit - learn
!p ip install numpy Pada langkah ini, kami memperbaiki benih acak terkait yang akan digunakan untuk mendapatkan hasil yang dapat diulang. Dengan cara ini, kami telah memberikan jalur deterministik di mana kami mendapatkan hasil yang sama dalam setiap proses. Namun, menurut pengamatan kami, hasil yang diperoleh pada komputer yang berbeda mungkin sedikit berbeda (± 1%)
## 2.2 Setting Random Seeds
seed_value = 0
import os
os . environ [ 'PYTHONHASHSEED' ] = str ( seed_value )
import random
random . seed ( seed_value )
import numpy as np
np . random . seed ( seed_value )Di bagian ini, file yang diberikan untuk data uji dimuat.
wifi mengambil ID dan bobot dari task2_test_estimated_wifi_distances.csv .steps Membutuhkan ID dan Bobot dari File task2_test_steps.csv .elevs Variable mengambil ID dari file task2_test_elevations.csv .fp_lookup Mendapat ID dan lintasan dari file task2_test_lookup.json . Kami tidak lebih suka metode penghitungan ulang jarak perkiraan yang diberikan dalam WiFi dengan model yang kami peroleh di Task1, karena hasil yang kami peroleh dari proses ini tidak membuat perbedaan yang signifikan. Itulah mengapa kami tidak menggunakan file task2_test_fingerprints.json dalam pekerjaan utama kami.
## 2.3 Loading the data
import os
import json
import csv
import networkx as nx
from tqdm import tqdm
path_to_data = "task2_for_participants/test"
with open ( os . path . join ( path_to_data , "task2_test_estimated_wifi_distances.csv" )) as f :
wifi = []
reader = csv . DictReader ( f )
for line in tqdm ( reader ):
wifi . append ([ line [ 'id1' ], line [ 'id2' ], float ( line [ 'estimated_distance' ])])
with open ( os . path . join ( path_to_data , "task2_test_elevations.csv" )) as f :
elevs = []
reader = csv . DictReader ( f )
for line in tqdm ( reader ):
elevs . append ([ line [ 'id1' ], line [ 'id2' ]])
with open ( os . path . join ( path_to_data , "task2_test_steps.csv" )) as f :
steps = []
reader = csv . DictReader ( f )
for line in tqdm ( reader ):
steps . append ([ line [ 'id1' ], line [ 'id2' ], float ( line [ 'displacement' ])])
fp_lookup_path = os . path . join ( path_to_data , "task2_test_lookup.json" )
with open ( fp_lookup_path ) as f :
fp_lookup = json . load ( f ) 3773297it [00:19, 191689.25it/s]
2767it [00:00, 52461.27it/s]
139537it [00:00, 180082.01it/s]
Kami mengambil jarak rata -rata sebagai bobot saat membuat grafik lintasan. Kami menggunakan contoh yang diberikan untuk Tugas 2 ( Task2-IPS-Challenge-2021.ipynb ) untuk proses ini. Kami menyimpan grafik yang dihasilkan ( B ) sebagai daftar adjacency di direktori (sebagai my.adjlist ).
## 2.3 Generating the Trajectory graph.
B = nx . Graph ()
# Get all the trajectory ids from the lookup
valid_nodes = set ( fp_lookup . values ())
for node in valid_nodes :
B . add_node ( node )
# Either add an edge or append the distance to the edge data
for id1 , id2 , dist in tqdm ( wifi ):
if not B . has_edge ( fp_lookup [ str ( id1 )], fp_lookup [ str ( id2 )]):
B . add_edge ( fp_lookup [ str ( id1 )],
fp_lookup [ str ( id2 )],
ty = "w" , weight = [ dist ])
else :
B [ fp_lookup [ str ( id1 )]][ fp_lookup [ str ( id2 )]][ 'weight' ]. append ( dist )
# Compute the mean edge weight
for edge in B . edges ( data = True ):
B [ edge [ 0 ]][ edge [ 1 ]][ 'weight' ] = sum ( B [ edge [ 0 ]][ edge [ 1 ]][ 'weight' ]) / len ( B [ edge [ 0 ]][ edge [ 1 ]][ 'weight' ])
# If you have made a wifi connection between trajectories with an elev, delete the edge
for id1 , id2 in tqdm ( elevs ):
if B . has_edge ( fp_lookup [ str ( id1 )], fp_lookup [ str ( id2 )]):
B . remove_edge ( fp_lookup [ str ( id1 )],
fp_lookup [ str ( id2 )])
nx . write_adjlist ( B , "my.adjlist" ) 100%|████████████████████████████████████████████████████████████████████| 3773297/3773297 [00:27<00:00, 135453.95it/s]
100%|██████████████████████████████████████████████████████████████████████████████████████| 2767/2767 [00:00<?, ?it/s]
Sebelum memberikan daftar adjacency sebagai input ke algoritma pembelajaran mesin, kami mengonversi node ke vektor. Dalam pekerjaan kami, kami menggunakan Node2VEC sebagai metodologi algoritma embedding grafik yang diusulkan oleh Grover & Leskovec pada tahun 2016 [3]. Node2Vec adalah algoritma semi-diawasi untuk pembelajaran fitur node dalam jaringan. Node2Vec dibuat berdasarkan teknik Skip-Gram, yang merupakan pendekatan NLP yang termotivasi pada konsep struktur distribusi. Menurut ide, jika kata-kata berbeda yang digunakan dalam konteks yang sama mereka mungkin memiliki makna yang sama dan ada hubungan yang jelas di antara mereka. Teknik Skip-Gram menggunakan kata pusat (input) untuk memprediksi tetangga (output) saat menghitung probabilitas lingkungan berdasarkan ukuran jendela yang diberikan (urutan item yang berdekatan sebelum setelah pusat), dengan kata lain n-gram. Berbeda dengan pendekatan NLP, sistem NODE2VEC tidak diberi makan dengan kata -kata yang memiliki struktur linier, tetapi node dan tepi, yang memiliki struktur grafis terdistribusi. Struktur multidimensi ini membuat embeddings kompleks dan mahal secara komputasi, tetapi Node2VEC menggunakan pengambilan sampel negatif dengan mengoptimalkan keturunan gradien stokastik (SGD) untuk menghadapinya. Selain itu, pendekatan jalan acak digunakan untuk mendeteksi node tetangga sampel dari node sumber dalam struktur nonlinier.
Dalam penelitian kami, kami pertama kali melakukan representasi vektor hubungan simpul dalam ruang dimensi rendah dengan memodelkan dengan Node2VEC dari jarak yang diberikan dua node (bobot). Kemudian kami menggunakan output node2vec (grafik embeddings), yang memiliki vektor node, untuk memberi makan algoritma pengelompokan K-means tradisional.
Parameter yang kami gunakan di NOD2VEC dapat terdaftar sebagai berikut:
| Hyperparameter | Nilai |
|---|---|
| ukuran | 32 |
| walk_length | 15 |
| num_walks | 100 |
| pekerja | 1 |
| benih | 0 |
| jendela | 10 |
| min_count | 1 |
| Batch_words | 4 |
Model NODE2VEC mengambil daftar adjacency sebagai input dan output vektor ukuran 32. Pada bagian ini, file node.py dibuat dan dijalankan di Jupyter Notebook . Ada dua alasan mengapa lebih baik dijalankan secara eksternal daripada di sel notebook Jupyter.
Node2vec adalah metode yang sangat mahal secara komputasi, kesalahan overflow RAM sangat mungkin jika dijalankan di dalam buku catatan Jupyter. Membuat dan menjalankan model Node2vec di luar menghindari kesalahan ini. Sel di bawah ini membuat file bernama node.py. File ini membuat model Node2Vec. Model ini mengambil daftar adjacency ( my.adjlist ) sebagai input dan membuat file vektor 32 dimensi sebagai output ( vectors.emb ).
Penting! Kode di bawah ini harus dijalankan dalam distribusi Linux (diuji di Google Colab dan Ubuntu).
# 2.4 Converting nodes to vectors
# A folder named tmp is created. This folder is essential for the node2vec model to use less RAM.
try :
if not os . path . exists ( "tmp" ):
os . makedirs ( "tmp" )
except OSError :
print ( "The folder could not be created! n Please manually create the " tmp " folder in the directory" )
node = """
# importing related modules
from node2vec import Node2Vec
import networkx as nx
#importing adjacency list file as B
B = nx.read_adjlist("my.adjlist")
seed_value=0
# Specifying the input and hyperparameters of the node2vec model
node2vec = Node2Vec(B, dimensions=32, walk_length=15, num_walks=100, workers=1,seed=seed_value,temp_folder = './tmp')
#Assigning/specifying random seeds
import os
os.environ['PYTHONHASHSEED']=str(seed_value)
import random
random.seed(seed_value)
import numpy as np
np.random.seed(seed_value)
# creation of the model
model = node2vec.fit(window=10, min_count=1, batch_words=4,seed=seed_value)
# saving the output vector
model.wv.save_word2vec_format("vectors.emb")
# save the model
model.save("vectorMODEL")
"""
f = open ( "node.py" , "w" )
f . write ( node )
f . close ()
! PYTHONHASHSEED = 0 python3 node . py Setelah file vektor kami dibuat, kami membaca file ini ( vectors.emb ). File ini terdiri dari 33 kolom. Kolom pertama adalah nomor simpul (IDS), dan tetap adalah nilai vektor. Dengan mengurutkan seluruh file berdasarkan kolom pertama, kami mengembalikan node ke urutan aslinya. Kemudian kami menghapus kolom ID ini, yang tidak akan kami gunakan lagi. Jadi, kami memberikan bentuk akhir dari data kami. Data kami siap digunakan dalam aplikasi pembelajaran mesin.
# 2.4 Reshaping data
vec = np . loadtxt ( "vectors.emb" , skiprows = 1 )
print ( "shape of vector file: " , vec . shape )
print ( vec )
vec = vec [ vec [:, 0 ]. argsort ()];
vec = vec [ 0 : vec . shape [ 0 ], 1 : vec . shape [ 1 ]] shape of vector file: (11162, 33)
[[ 9.1200000e+03 3.9031842e-01 -4.7147268e-01 ... -5.7490986e-02
1.3059708e-01 -5.4280665e-02]
[ 6.5320000e+03 -3.5591956e-02 -9.8558587e-01 ... -2.7217887e-02
5.6435770e-01 -5.7787680e-01]
[ 5.6580000e+03 3.5879680e-01 -4.7564098e-01 ... -9.7607370e-02
1.5506668e-01 1.1333219e-01]
...
[ 2.7950000e+03 1.1724627e-02 1.0272172e-02 ... -4.5596390e-04
-1.1507459e-02 -7.6738600e-04]
[ 4.3380000e+03 1.2865483e-02 1.2103912e-02 ... 1.6619096e-03
1.3672550e-02 1.4605848e-02]
[ 1.1770000e+03 -1.3707868e-03 1.5238028e-02 ... -5.9994194e-04
-1.2986251e-02 1.3706315e-03]]
Tugas-2 adalah masalah pengelompokan. Premis yang perlu kita putuskan saat menyelesaikan masalah ini adalah berapa banyak kelompok yang harus kita bagi. Untuk ini, kami mencoba nomor cluster yang berbeda dan membandingkan skor yang kami dapatkan. Grafik di bawah ini menunjukkan perbandingan jumlah kelompok dan skor yang diperoleh. Seperti yang dapat dilihat dari grafik ini, jumlah kelompok meningkat terus menerus antara 5 dan 21, dengan beberapa fluktuasi pengecualian, dan distabilkan setelah 21. Untuk alasan ini, kami fokus pada jumlah cluster antara 21 dan 23 dalam penelitian kami.
# 2.5 Determine the number of clusters
import numpy as np
import matplotlib . pyplot as plt
import seaborn as sns
import matplotlib
% matplotlib inline
sns . set_style ( "whitegrid" )
agglom = [ 24.69 , 28.14 , 28.14 , 28.14 , 30 , 33.33 , 40.88 , 38.70 , 40 , 40 , 40 , 29.12 , 45.85 , 45.85 , 48.00 , 50.17 , 57.83 , 57.83 , 57.83 ]
plt . figure ( figsize = ( 10 , 5 ))
plt . plot ( range ( 5 , 24 ), agglom )
matplotlib . pyplot . xticks ( range ( 5 , 24 ))
plt . title ( 'Number of clusters and performance relationship' )
plt . xlabel ( 'Number of clusters' )
plt . ylabel ( 'Score' )
plt . show ()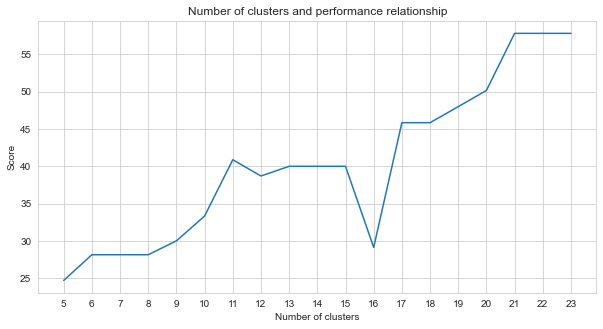
Di antara metode pembelajaran mesin yang tidak diawasi yang kami coba (seperti K-means, pengelompokan aglomeratif, perambatan afinitas, pergeseran rata-rata, pengelompokan spektral, dbscan, optik, birch, mini-batch-k-means), kami mencapai hasil terbaik menggunakan k-means dengan 23 cluster.
K-Means adalah algoritma pengelompokan adalah salah satu teknik pembelajaran mesin dasar dan tradisional yang tidak diawasi yang membuat asumsi untuk menemukan kelompok elemen (cluster) yang homogen atau alami menggunakan data yang tidak berlabel. Cluster harus set poin (node dalam data kami) yang dikelompokkan bersama yang memiliki kesamaan tertentu. K-Means membutuhkan jumlah target centroid yang mengacu pada berapa banyak kelompok data yang harus dibagi menjadi. Algoritma dimulai dengan kelompok centroid yang ditugaskan secara acak kemudian melanjutkan iterasi untuk menemukan posisi terbaik dari mereka. Algoritma ini memberikan poin/node ke centroid yang ditunjuk menggunakan in-cluster jumlah kotak anggota poin, ini terus memperbarui dan pindah [4]. Dalam contoh kami, jumlah centroid mencerminkan jumlah lantai. Perlu dicatat bahwa ini tidak memberikan informasi tentang urutan lantai.
Di bawah ini, aplikasi K-Means telah dibuat untuk 23 cluster.
# 2.5 Best result
from sklearn import cluster
import time
ML_results = []
k_clusters = 23
algorithms = {}
algorithms [ 'KMeans' ] = cluster . KMeans ( n_clusters = k_clusters , random_state = 10 )
second = time . time ()
for model in algorithms . values ():
model . fit ( vec )
ML_results = list ( model . labels_ )
print ( model , time . time () - second ) KMeans(n_clusters=23, random_state=10) 1.082334280014038
Output dari algoritma pembelajaran mesin menentukan cluster sidik jari mana yang dimiliki. Tetapi yang dibutuhkan dari kita adalah untuk mengelompokkan lintasan. Oleh karena itu, sidik jari ini dikonversi ke lintasan lintasannya menggunakan variabel fp_lookup . Output ini diproses ke dalam file TASK2-Mysubmission.csv .
## 2.6 Submission
result = {}
for ii , i in enumerate ( set ( fp_lookup . values ())):
result [ i ] = ML_results [ ii ]
ters = {}
for i in result :
if result [ i ] not in ters :
ters [ result [ i ]] = []
ters [ result [ i ]]. append ( i )
else :
ters [ result [ i ]]. append ( i )
final_results = []
for i in ters :
final_results . append ( ters [ i ])
name = "TASK2-Mysubmission.csv"
with open ( name , "w" , newline = '' ) as f :
csv_writer = csv . writer ( f )
csv_writer . writerows ( final_results )
print ( name , "file is ready!" ) TASK2-Mysubmission.csv file is ready!
[1] P. Kontributor Virtanen dan Scipy 1.0. SCIPY 1.0: Algoritma fundamental untuk komputasi ilmiah di Python. Metode Alam, 17: 261--272, 2020.
[2] A. Geron, Pembelajaran mesin langsung dengan scikit-learn, keras, dan tensorflow: konsep, alat, dan teknik untuk membangun sistem cerdas. O'Reilly Media, 2019
[3] A. Grover, J. Leskovec. Konferensi Internasional ACM SIGKDD tentang Penemuan Pengetahuan dan Penambangan Data (KDD), 2016.
[4] Jin X., Han J. (2011) K-Means Clustering. Dalam: Sammut C., Webb GI (eds) Ensiklopedia Pembelajaran Mesin. Springer, Boston, MA. https://doi.org/10.1007/978-0-387-30164-8_425


