ainovelprompter
1.0.0
AI novel proppter dapat menghasilkan prompt penulisan untuk novel berdasarkan karakteristik yang ditentukan pengguna.
AI Novel Prompter adalah aplikasi desktop yang dirancang untuk membantu penulis membuat permintaan yang konsisten dan terstruktur dengan baik untuk asisten penulisan AI seperti ChatGPT dan Claude. Alat ini membantu mengelola elemen cerita, detail karakter, dan menghasilkan petunjuk yang diformat dengan benar untuk melanjutkan novel Anda.
Yang dapat dieksekusi sedang dieksekusi/tempat sampah yang dapat dieksekusi
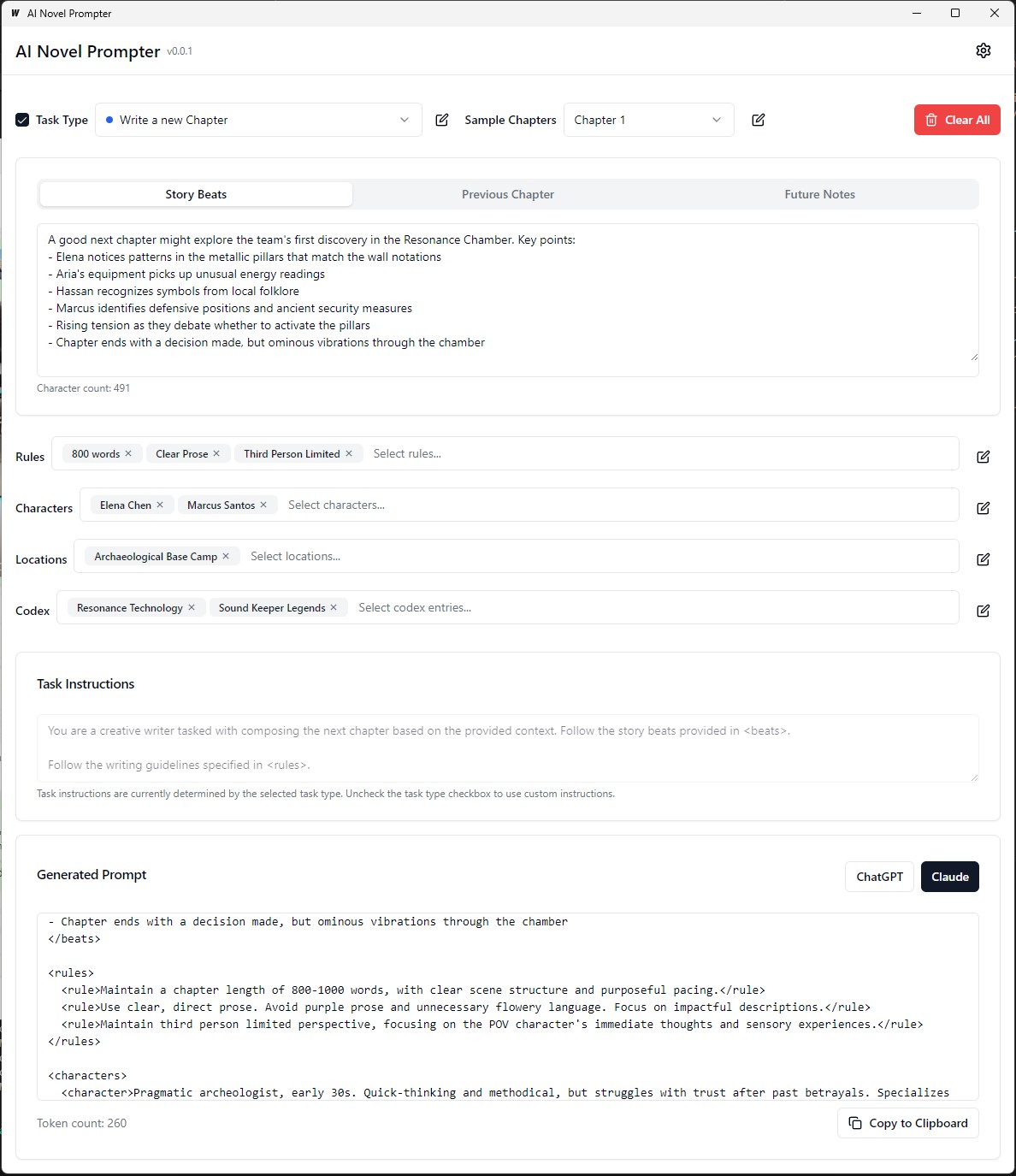
Setiap kategori dapat diedit, disimpan, dan digunakan kembali di berbagai petunjuk:
Frontend :
Backend :
.ai-novel-prompter # Clone the repository
git clone [repository-url]
# Install frontend dependencies
cd frontend
npm install
# Build and run the application
cd ..
wails dev Untuk membangun paket mode produksi yang dapat didistribusikan kembali, gunakan wails build .
wails buildYang dapat dieksekusi sedang dieksekusi/tempat sampah yang dapat dieksekusi
Atau menghasilkannya dengan:
wails build -nsisIni dapat dilakukan untuk Mac juga melihat bagian terbaru dari panduan ini
Aplikasi yang dibangun akan tersedia di direktori build .
Pengaturan Awal :
Membuat prompt :
Menghasilkan output :
Sebelum menjalankan aplikasi, pastikan Anda menginstal berikut:
git clone https://github.com/danielsobrado/ainovelprompter.git
cd ainovelprompter
Arahkan ke direktori server :
cd server
Instal Ketergantungan GO:
go mod download
Perbarui file config.yaml dengan konfigurasi database Anda.
Jalankan migrasi basis data:
go run cmd/main.go migrate
Mulai server backend:
go run cmd/main.go
Arahkan ke direktori client :
cd ../client
Instal dependensi frontend:
npm install
Mulai Server Pengembangan Frontend:
npm start
http://localhost:3000 untuk mengakses aplikasi. git clone https://github.com/danielsobrado/ainovelprompter.git
cd ainovelprompter
Perbarui file docker-compose.yml dengan konfigurasi database Anda.
Mulai aplikasi menggunakan Docker Compose:
docker-compose up -d
http://localhost:3000 untuk mengakses aplikasi. server/config.yaml .client/src/config.ts . Untuk membangun frontend untuk produksi, jalankan perintah berikut di direktori client :
npm run build
File siap-produksi akan dihasilkan di direktori client/build .
Panduan kecil ini memberikan instruksi tentang cara menginstal PostgreSQL pada subsistem Windows untuk Linux (WSL), bersama dengan langkah -langkah untuk mengelola izin pengguna dan memecahkan masalah umum.
Buka Terminal WSL : Luncurkan Distribusi WSL Anda (Ubuntu direkomendasikan).
Paket Perbarui :
sudo apt updateInstal PostgreSQL :
sudo apt install postgresql postgresql-contribPeriksa instalasi :
psql --versionAtur Kata Sandi Pengguna PostgreSQL :
sudo passwd postgresBuat Database :
createdb mydbAkses Database :
psql mydbImpor Tabel dari File SQL :
psql -U postgres -q mydb < /path/to/file.sqlDaftar database dan tabel :
l # List databases
dt # List tables in the current databaseSwitch Database :
c dbnameBuat pengguna baru :
CREATE USER your_db_user WITH PASSWORD ' your_db_password ' ;Hak Hibah :
ALTER USER your_db_user CREATEDB;Peran tidak ada kesalahan : beralih ke pengguna 'Postgres':
sudo -i -u postgres
createdb your_db_nameIzin ditolak untuk membuat ekstensi : Masuk sebagai 'postgres' dan jalankan:
CREATE EXTENSION IF NOT EXISTS pg_trgm; Kesalahan pengguna yang tidak diketahui : Pastikan Anda menggunakan pengguna sistem yang dikenali atau merujuk dengan benar ke pengguna PostgreSQL dalam lingkungan SQL, bukan melalui sudo .
Untuk menghasilkan data pelatihan khusus untuk menyempurnakan model bahasa untuk meniru gaya penulisan George MacDonald, proses dimulai dengan mendapatkan teks lengkap dari salah satu novelnya, "The Princess and the Goblin," dari Project Gutenberg. Teks tersebut kemudian dipecah menjadi ketukan cerita individu atau saat -saat penting menggunakan prompt yang menginstruksikan AI untuk menghasilkan objek JSON untuk setiap ketukan, menangkap penulis, nada emosional, jenis tulisan, dan kutipan teks yang sebenarnya.
Selanjutnya, GPT-4 digunakan untuk menulis ulang masing-masing cerita ini dengan kata-katanya sendiri, menghasilkan satu set data paralel JSON dengan pengidentifikasi unik yang menghubungkan setiap ketukan yang ditulis ulang ke rekan aslinya. Untuk menyederhanakan data dan membuatnya lebih berguna untuk pelatihan, beragam nada emosional dipetakan ke serangkaian nada inti yang lebih kecil menggunakan fungsi python. Dua file JSON (ketukan asli dan ditulis ulang) kemudian digunakan untuk menghasilkan petunjuk pelatihan, di mana model diminta untuk mengulangi teks yang dihasilkan GPT-4 dengan gaya penulis asli. Akhirnya, petunjuk ini dan output target mereka diformat ke dalam file JSONL dan JSON, siap digunakan untuk menyempurnakan model bahasa untuk menangkap gaya penulisan khas MacDonald.
Dalam contoh sebelumnya, proses menghasilkan teks parafrase menggunakan model bahasa melibatkan beberapa tugas manual. Pengguna harus secara manual menyediakan teks input, menjalankan skrip, dan kemudian meninjau output yang dihasilkan untuk memastikan kualitasnya. Jika output tidak memenuhi kriteria yang diinginkan, pengguna perlu mencoba kembali secara manual proses pembuatan dengan parameter yang berbeda atau membuat penyesuaian pada teks input.
Namun, dengan versi yang diperbarui dari fungsi process_text_file , seluruh proses telah sepenuhnya otomatis. Fungsi menangani membaca file teks input, membaginya menjadi paragraf, dan secara otomatis mengirim setiap paragraf ke model bahasa untuk memparafrasekan. Ini menggabungkan berbagai mekanisme pemeriksaan dan coba lagi untuk menangani kasus -kasus di mana output yang dihasilkan tidak memenuhi kriteria yang ditentukan, seperti berisi frasa yang tidak diinginkan, terlalu pendek atau terlalu panjang, atau terdiri dari beberapa paragraf.
Proses otomatisasi mencakup beberapa fitur utama:
Lanjutkan dari paragraf yang diproses terakhir: Jika skrip terganggu atau perlu dijalankan beberapa kali, secara otomatis memeriksa file output dan melanjutkan pemrosesan dari paragraf terakhir yang berhasil diparafrasekan. Ini memastikan bahwa kemajuan tidak hilang dan skrip dapat mengambil di mana ia tinggalkan.
Coba lagi mekanisme dengan biji dan suhu acak: Jika parafrase yang dihasilkan gagal memenuhi kriteria yang ditentukan, skrip secara otomatis menarik kembali proses pembangkit hingga beberapa kali. Dengan masing -masing coba lagi, secara acak mengubah nilai benih dan suhu untuk memperkenalkan variasi dalam respons yang dihasilkan, meningkatkan kemungkinan mendapatkan output yang memuaskan.
Simpan Progres: Skrip menyimpan kemajuan ke file output setiap jumlah paragraf yang ditentukan (misalnya, setiap 500 paragraf). Perlindungan terhadap kehilangan data ini jika terjadi gangguan atau kesalahan selama pemrosesan file teks besar.
Logging dan Ringkasan terperinci: Script memberikan informasi logging terperinci, termasuk paragraf input, output yang dihasilkan, coba lagi, dan alasan kegagalan. Ini juga menghasilkan ringkasan di akhir, menampilkan jumlah total paragraf, paragraf yang berhasil diparafrasekan, paragraf yang dilewati, dan jumlah total retries.
Untuk menghasilkan data pelatihan khusus ORPO untuk menyempurnakan model bahasa untuk meniru gaya penulisan George MacDonald.
Data input harus dalam format JSONL, dengan setiap baris berisi objek JSON yang mencakup respons prompt dan dipilih. (Dari fine tuning sebelumnya) untuk menggunakan skrip, Anda perlu mengatur klien OpenAI dengan tombol API Anda dan menentukan jalur file input dan output. Menjalankan skrip akan memproses file JSONL dan menghasilkan file CSV dengan kolom untuk prompt, respons yang dipilih, dan respons yang ditolak yang dihasilkan. Script menyimpan kemajuan setiap 100 baris dan dapat dilanjutkan dari tempat yang ditinggalkan jika terganggu. Setelah selesai, ia memberikan ringkasan dari total garis yang diproses, garis tertulis, garis yang dilewati, dan coba lagi detail.
Kualitas Dataset penting: 95% hasil tergantung pada kualitas dataset. Dataset yang bersih sangat penting karena bahkan sedikit data yang buruk dapat melukai model.
Tinjauan Data Manual: Membersihkan dan Mengevaluasi Dataset dapat sangat meningkatkan model. Ini adalah langkah yang memakan waktu tetapi perlu karena tidak ada jumlah penyesuaian parameter yang dapat memperbaiki dataset yang rusak.
Parameter pelatihan tidak boleh meningkat tetapi mencegah degradasi model. Dalam set data yang kuat, tujuannya adalah untuk menghindari dampak negatif saat mengarahkan model. Tidak ada tingkat pembelajaran yang optimal.
Skala model dan keterbatasan perangkat keras: Model yang lebih besar (parameter 33B) dapat memungkinkan penyempurnaan yang lebih baik tetapi membutuhkan setidaknya 48GB VRAM, menjadikannya tidak praktis untuk sebagian besar pengaturan rumah.
Akumulasi gradien dan ukuran batch: Akumulasi gradien membantu mengurangi overfitting dengan meningkatkan generalisasi di berbagai set data, tetapi dapat menurunkan kualitas setelah beberapa batch.
Ukuran dataset lebih penting untuk menyempurnakan model dasar daripada model yang disesuaikan dengan baik. Kelebihan model yang disesuaikan dengan data yang berlebihan dapat menurunkan fine-tuning sebelumnya.
Jadwal tingkat pembelajaran yang ideal dimulai dengan fase pemanasan, tetap stabil untuk zaman, dan kemudian secara bertahap berkurang menggunakan jadwal cosinus.
Peringkat dan generalisasi model: Jumlah parameter yang dapat dilatih mempengaruhi detail dan generalisasi model. Model berperingkat rendah menggeneralisasi lebih baik tetapi kehilangan detail.
Penerapan Lora: Parameter-efisien fine-tuning (PEFT) berlaku untuk model bahasa besar (LLM) dan sistem seperti stabil difusi (SD), menunjukkan fleksibilitasnya.
Komunitas Geseng telah membantu menyelesaikan beberapa masalah dengan Finetuning Llama3. Berikut adalah beberapa poin penting yang perlu diingat:
Token BOS Ganda : Token Bos Ganda Selama Finetuning dapat memecahkan banyak hal. Melepaskan diri secara otomatis memperbaiki masalah ini.
Konversi GGUF : Konversi GGUF rusak. Hati -hati dengan BOS ganda dan gunakan CPU alih -alih GPU untuk konversi. Ketidaksopanan memiliki konversi GGUF otomatis bawaan.
Bobot basis buggy : Beberapa bobot Llama 3 (tidak menginstruksikan) bobot adalah "buggy" (tidak terlatih): <|reserved_special_token_{0->250}|> <|eot_id|> <|start_header_id|> <|end_header_id|> . Ini dapat menyebabkan NANS dan hasil kereta. Mengorepkan secara otomatis memperbaiki ini.
Sistem Prompt : Menurut komunitas yang tidak meremehkan, menambahkan prompt sistem membuat finetuning dari versi instruksi (dan mungkin versi dasar) jauh lebih baik.
Masalah kuantisasi : Masalah kuantisasi adalah umum. Lihat perbandingan ini yang menunjukkan bahwa Anda bisa mendapatkan kinerja yang baik dengan LLAMA3, tetapi menggunakan kuantisasi yang salah dapat merusak kinerja. Untuk finetuning, gunakan Bitsandbytes NF4 untuk meningkatkan akurasi. Untuk GGUF, gunakan versi I sebanyak mungkin.
Model Konteks Panjang : Model konteks panjang tidak terlatih. Mereka hanya memperluas tali tali, kadang -kadang tanpa pelatihan, dan kemudian berlatih pada dataset gabungan yang aneh untuk menjadikannya dataset yang panjang. Pendekatan ini tidak bekerja dengan baik. Penskalaan konteks panjang yang halus dan terus menerus akan jauh lebih baik jika penskalaan dari 8k hingga 1m panjang konteks.
Untuk menyelesaikan beberapa masalah ini, gunakan ketidakteraturan untuk finetuning llama3.
Saat menyempurnakan model bahasa untuk memparafrasekan dalam gaya penulis, penting untuk mengevaluasi kualitas dan efektivitas parafrase yang dihasilkan.
Metrik evaluasi berikut dapat digunakan untuk menilai kinerja model:
Bleu (pengganti evaluasi bilingual):
sacrebleu di Python.from sacrebleu import corpus_bleu; bleu_score = corpus_bleu(generated_paraphrases, [original_paragraphs])Rouge (pengganti yang berorientasi pada penarikan kembali untuk evaluasi gisting):
rouge di Python.from rouge import Rouge; rouge = Rouge(); scores = rouge.get_scores(generated_paraphrases, original_paragraphs)Kebingungan:
perplexity = model.perplexity(generated_paraphrases)Langkah -langkah stylometrik:
stylometry di Python.from stylometry import extract_features; features = extract_features(generated_paraphrases)Untuk mengintegrasikan metrik evaluasi ini ke dalam pipa Axolotl Anda, ikuti langkah -langkah ini:
Persiapkan data pelatihan Anda dengan membuat dataset paragraf dari karya penulis target dan membaginya menjadi set pelatihan dan validasi.
Menyempurnakan model bahasa Anda menggunakan set pelatihan, mengikuti pendekatan yang dibahas sebelumnya.
Hasilkan parafrase untuk paragraf dalam set validasi menggunakan model fine-tuned.
Menerapkan metrik evaluasi menggunakan perpustakaan masing -masing ( sacrebleu , rouge , stylometry ) dan menghitung skor untuk setiap parafrase yang dihasilkan.
Lakukan evaluasi manusia dengan mengumpulkan peringkat dan umpan balik dari evaluator manusia.
Menganalisis hasil evaluasi untuk menilai kualitas dan gaya parafrase yang dihasilkan dan membuat keputusan berdasarkan informasi untuk meningkatkan proses penyempurnaan Anda.
Berikut adalah contoh bagaimana Anda dapat mengintegrasikan metrik ini ke dalam pipa Anda:
from sacrebleu import corpus_bleu
from rouge import Rouge
from stylometry import extract_features
# Fine-tune the model using the training set
fine_tuned_model = train_model ( training_data )
# Generate paraphrases for the validation set
generated_paraphrases = generate_paraphrases ( fine_tuned_model , validation_data )
# Calculate evaluation metrics
bleu_score = corpus_bleu ( generated_paraphrases , [ original_paragraphs ])
rouge = Rouge ()
rouge_scores = rouge . get_scores ( generated_paraphrases , original_paragraphs )
perplexity = fine_tuned_model . perplexity ( generated_paraphrases )
stylometric_features = extract_features ( generated_paraphrases )
# Perform human evaluation
human_scores = collect_human_evaluations ( generated_paraphrases )
# Analyze and interpret the results
analyze_results ( bleu_score , rouge_scores , perplexity , stylometric_features , human_scores )Ingatlah untuk menginstal perpustakaan yang diperlukan (Sacrebleu, Rouge, Stylometry) dan mengadaptasi kode agar sesuai dengan implementasi Anda di Axolotl atau serupa.
Dalam percobaan ini, saya mengeksplorasi kemampuan dan perbedaan antara berbagai model AI dalam menghasilkan teks 1500 kata berdasarkan prompt terperinci. Saya menguji model dari https://chat.lmsys.org/, chatgpt4, Claude 3 Opus, dan beberapa model lokal di LM Studio. Setiap model menghasilkan teks tiga kali untuk mengamati variabilitas dalam outputnya. Saya juga membuat prompt terpisah untuk mengevaluasi penulisan iterasi pertama dari masing -masing model dan meminta ChatGPT 4 dan Claude Opus 3 untuk memberikan umpan balik.
Melalui proses ini, saya mengamati bahwa beberapa model menunjukkan variabilitas yang lebih tinggi antara eksekusi, sementara yang lain cenderung menggunakan kata -kata yang sama. Ada juga perbedaan yang signifikan dalam jumlah kata yang dihasilkan dan jumlah dialog, deskripsi, dan paragraf yang dihasilkan oleh masing -masing model. Umpan balik evaluasi mengungkapkan bahwa chatgpt menunjukkan prosa yang lebih "halus", sementara Claude merekomendasikan lebih sedikit prosa ungu. Berdasarkan temuan ini, saya menyusun daftar takeaways untuk dimasukkan ke dalam prompt berikutnya, fokus pada presisi, berbagai struktur kalimat, kata kerja yang kuat, tikungan unik pada motif fantasi, nada yang konsisten, suara narator yang berbeda, dan langkah yang menarik. Teknik lain yang perlu dipertimbangkan adalah meminta umpan balik dan kemudian menulis ulang teks berdasarkan umpan balik itu.
Saya terbuka untuk berkolaborasi dengan orang lain untuk lebih menyempurnakan petunjuk untuk setiap model dan mengeksplorasi kemampuan mereka dalam tugas menulis kreatif.
Model memiliki bias format yang melekat. Beberapa model lebih suka tanda hubung untuk daftar, yang lain tanda bintang. Saat menggunakan model -model ini, akan bermanfaat untuk mencerminkan preferensi mereka untuk output yang konsisten.
Kecenderungan Memformat:
Llama 3 lebih suka daftar dengan judul dan tanda bintang yang tebal.
Contoh: Judul judul judul tebal
Daftar item dengan tanda bintang setelah dua garis baru
Daftar item yang dipisahkan oleh satu baris baru
Daftar berikutnya
Lebih banyak item daftar
Dll...
Contoh beberapa shot:
Kepatuhan Sistem Prompt:
Jendela Konteks:
Sensor:
Intelijen:
Konsistensi:
Daftar dan pemformatan:
Pengaturan Obrolan:
Pengaturan Pipa:
Llama 3 fleksibel dan cerdas tetapi memiliki batasan konteks dan mengutip. Sesuaikan metode yang tepat.
Semua komentar dipersilakan. Buka masalah atau kirim permintaan tarik jika Anda menemukan bug atau memiliki rekomendasi untuk perbaikan.
Proyek ini dilisensikan di bawah: Lisensi Atribution-NonCommercial-Noderivatives (BY-NC-ND) Lihat: https://creativecommons.org/licenses/by-nc-nd/4.0/deed.en


