IP Adapter
1.0.0
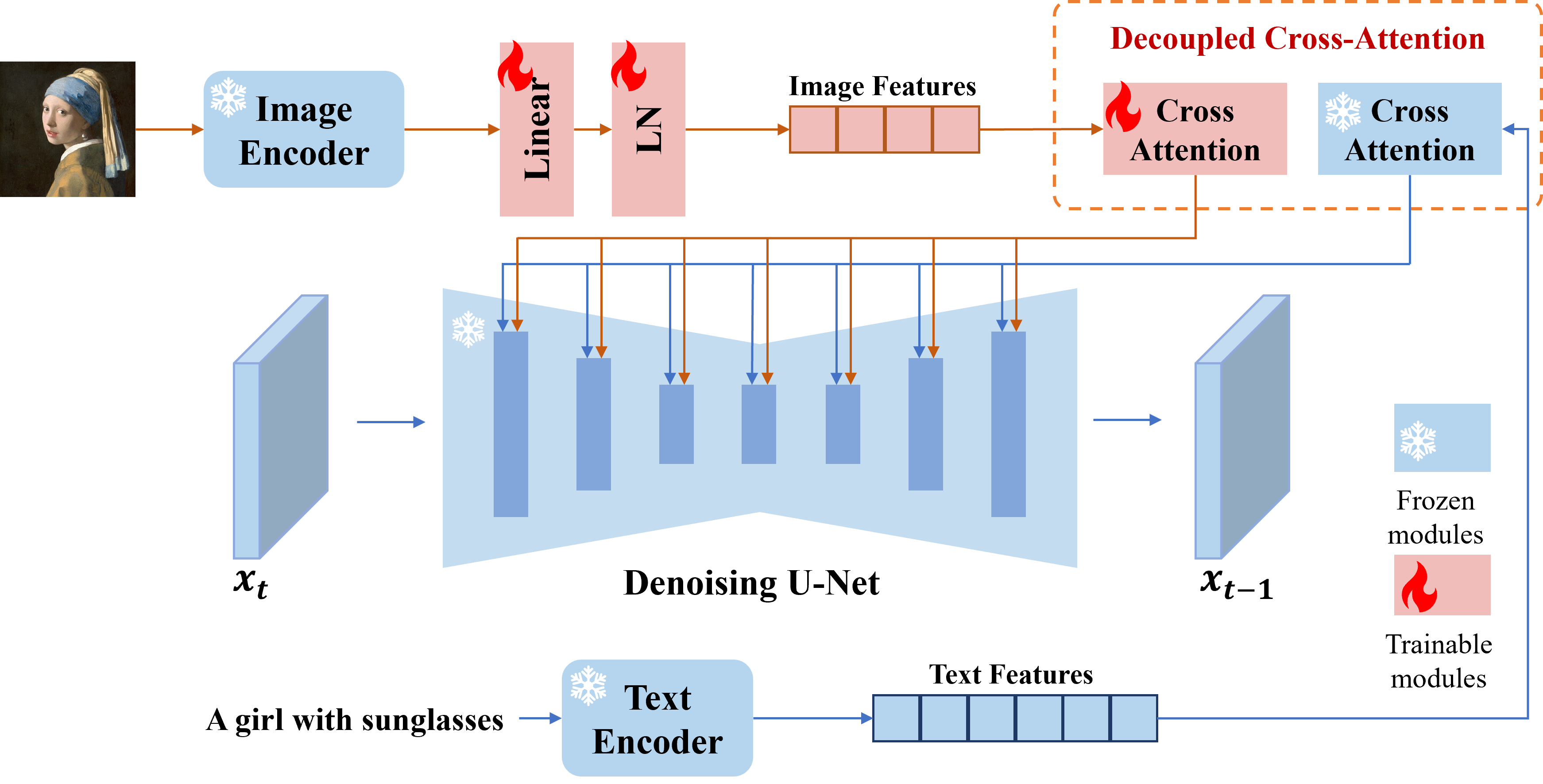
Kami menyajikan Adaptor IP, adaptor yang efektif dan ringan untuk mencapai kemampuan cepat gambar untuk model difusi teks-ke-gambar yang sudah terlatih. Adaptor IP dengan hanya 22m parameter dapat mencapai kinerja yang sebanding atau bahkan lebih baik dengan model prompt gambar yang disetel. Adaptor IP dapat digeneralisasi tidak hanya untuk model kustom lain yang disempurnakan dari model dasar yang sama, tetapi juga untuk pembuatan yang dapat dikendalikan menggunakan alat yang dapat dikontrol yang ada. Selain itu, prompt gambar juga dapat bekerja dengan baik dengan prompt teks untuk mencapai pembuatan gambar multimodal.
# install latest diffusers
pip install diffusers==0.22.1
# install ip-adapter
pip install git+https://github.com/tencent-ailab/IP-Adapter.git
# download the models
cd IP-Adapter
git lfs install
git clone https://huggingface.co/h94/IP-Adapter
mv IP-Adapter/models models
mv IP-Adapter/sdxl_models sdxl_models
# then you can use the notebook
Anda dapat mengunduh model dari sini. Untuk menjalankan demo, Anda juga harus mengunduh model berikut:









Praktik terbaik
scale=1.0 dan text_prompt="" (atau beberapa permintaan teks generik, misalnya "kualitas terbaik", Anda juga dapat menggunakan prompt teks negatif apa pun). Jika Anda menurunkan scale , gambar yang lebih beragam dapat dihasilkan, tetapi mereka mungkin tidak konsisten dengan prompt gambar.scale untuk mendapatkan hasil terbaik. Dalam kebanyakan kasus, scale=0.5 bisa mendapatkan hasil yang baik. Untuk versi SD 1.5, kami sarankan menggunakan model komunitas untuk menghasilkan gambar yang bagus.Adaptor IP untuk gambar non-square
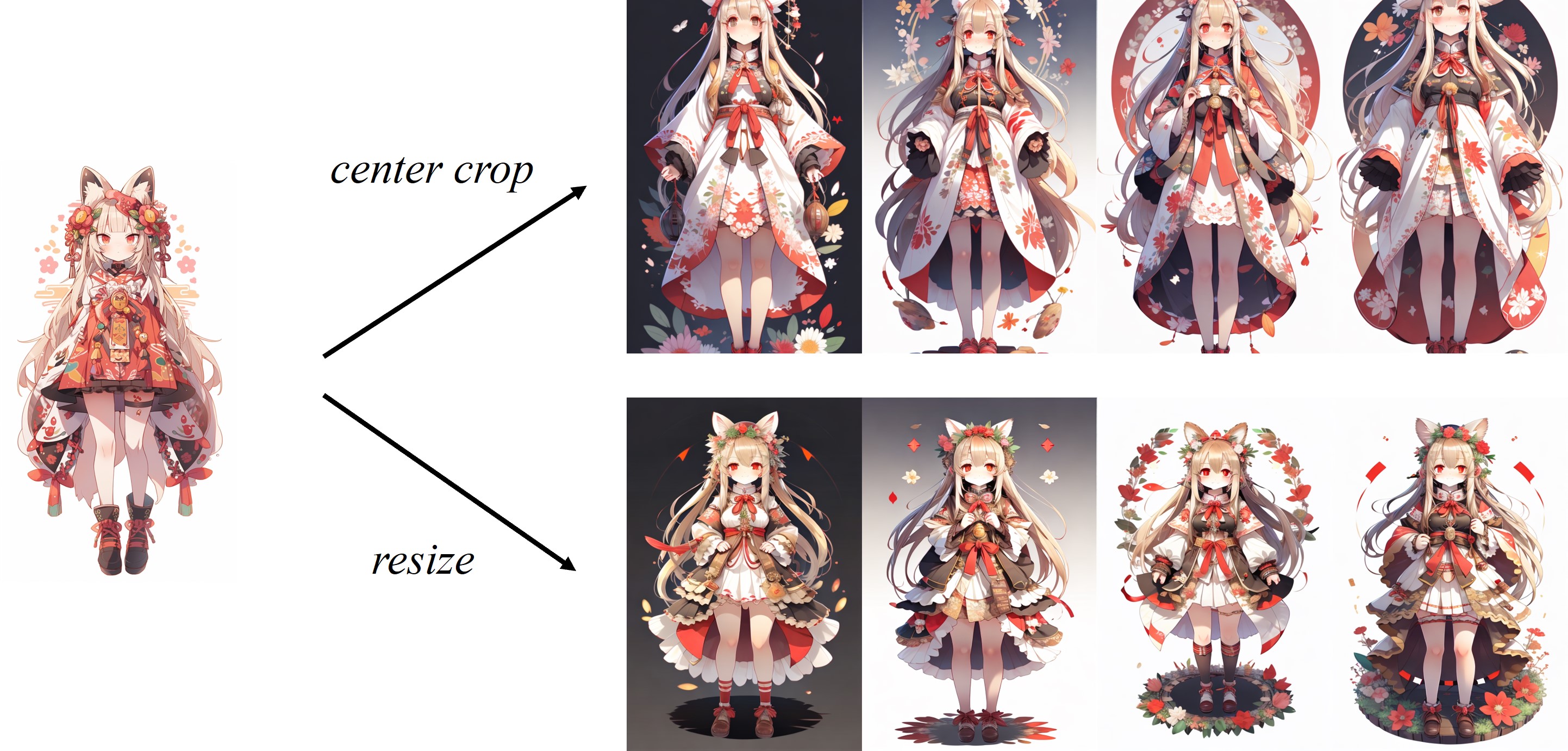
Karena gambar dipotong di tengah dalam prosesor gambar default klip, Adaptor IP bekerja paling baik untuk gambar persegi. Untuk gambar non -persegi, itu akan kehilangan informasi di luar pusat. Tetapi Anda hanya dapat mengubah ukuran menjadi 224x224 untuk gambar non-square, perbandingannya adalah sebagai berikut:
Perbandingan IP-adapter_xl dengan reimagine XL ditampilkan sebagai berikut:

Perbaikan dalam versi baru (2023.9.8) :
Untuk pelatihan, Anda harus menginstal Accelerate dan membuat dataset Anda sendiri ke dalam file JSON.
accelerate launch --num_processes 8 --multi_gpu --mixed_precision "fp16"
tutorial_train.py
--pretrained_model_name_or_path="runwayml/stable-diffusion-v1-5/"
--image_encoder_path="{image_encoder_path}"
--data_json_file="{data.json}"
--data_root_path="{image_path}"
--mixed_precision="fp16"
--resolution=512
--train_batch_size=8
--dataloader_num_workers=4
--learning_rate=1e-04
--weight_decay=0.01
--output_dir="{output_dir}"
--save_steps=10000
Setelah pelatihan selesai, Anda dapat mengonversi bobot dengan kode berikut:
import torch
ckpt = "checkpoint-50000/pytorch_model.bin"
sd = torch . load ( ckpt , map_location = "cpu" )
image_proj_sd = {}
ip_sd = {}
for k in sd :
if k . startswith ( "unet" ):
pass
elif k . startswith ( "image_proj_model" ):
image_proj_sd [ k . replace ( "image_proj_model." , "" )] = sd [ k ]
elif k . startswith ( "adapter_modules" ):
ip_sd [ k . replace ( "adapter_modules." , "" )] = sd [ k ]
torch . save ({ "image_proj" : image_proj_sd , "ip_adapter" : ip_sd }, "ip_adapter.bin" )Proyek ini berusaha secara positif berdampak pada domain pembuatan gambar yang digerakkan oleh AI. Pengguna diberikan kebebasan untuk membuat gambar menggunakan alat ini, tetapi mereka diharapkan mematuhi hukum setempat dan menggunakannya dengan cara yang bertanggung jawab. Pengembang tidak bertanggung jawab atas potensi penyalahgunaan oleh pengguna.
Jika Anda menemukan IP-Adapter berguna untuk penelitian dan aplikasi Anda, silakan mengutip menggunakan Bibtex ini:
@article { ye2023ip-adapter ,
title = { IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models } ,
author = { Ye, Hu and Zhang, Jun and Liu, Sibo and Han, Xiao and Yang, Wei } ,
booktitle = { arXiv preprint arxiv:2308.06721 } ,
year = { 2023 }
}

