paper2slides
1.0.0
Ubah kertas arxiv menjadi slide menggunakan model bahasa besar (LLM)! Alat ini berguna untuk dengan cepat memahami ide -ide utama dari makalah penelitian.
Beberapa contoh slide yang dihasilkan adalah: Word2vec, Gan, Transformer, Vit, Chain-of-Thought, Star, DPO, dan AI Scientist. Lihat banyak contoh lain dari slide yang dihasilkan dalam demo.
Skrip akan mengunduh file dari Internet (ARXIV), mengirim informasi ke API OpenAI, dan mengkompilasi secara lokal. Harap berhati -hati tentang konten yang dibagikan dan potensi risiko. Jika Anda memiliki ID Arxiv khusus yang Anda minati dan tidak ingin menjalankan kode sendiri, beri tahu saya dalam "diskusi" dan saya akan dengan senang hati menambahkan slide ke daftar demo.
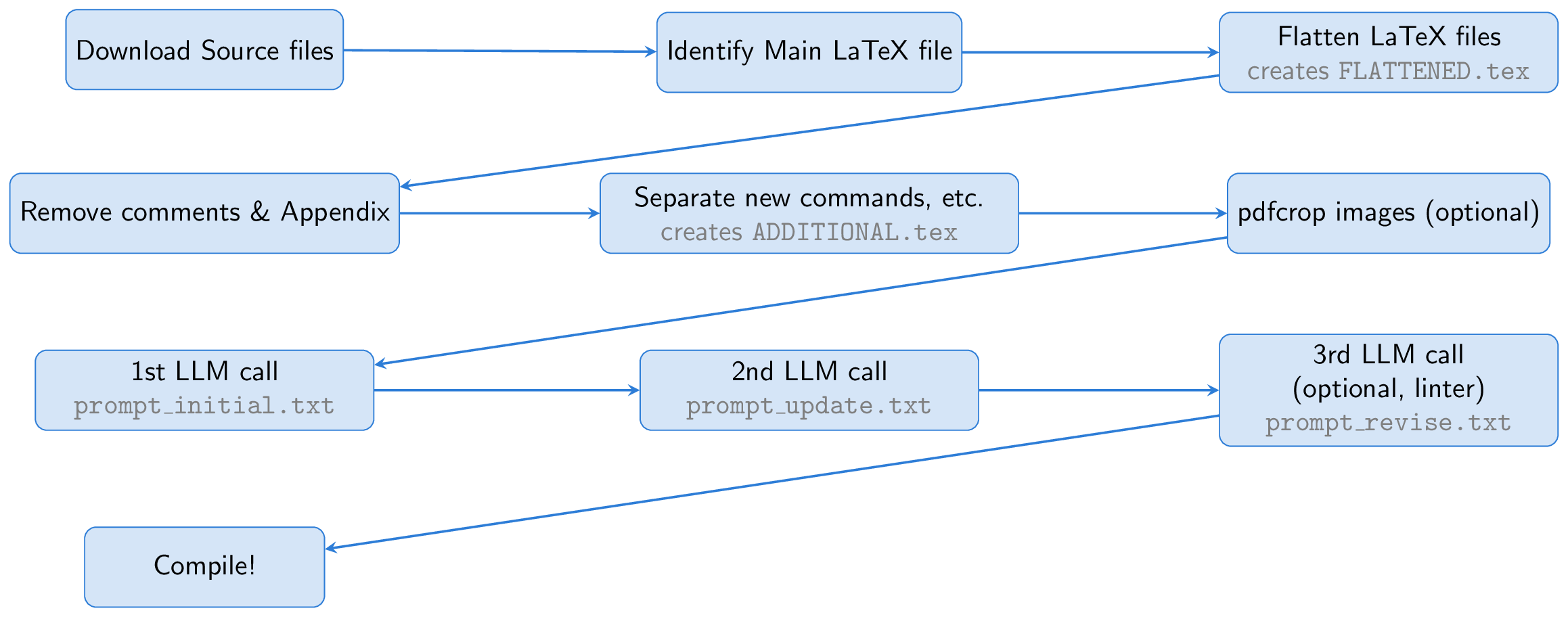
Proses dimulai dengan mengunduh file sumber dari kertas Arxiv. File lateks utama diidentifikasi dan diratakan, menggabungkan semua file input ke dalam satu dokumen ( FLATTENED.tex ). Kami preprocess file gabungan ini dengan menghapus komentar dan lampiran. File yang diproses praproses ini, bersama dengan instruksi untuk membuat slide yang baik, membentuk dasar dari prompt kami.
Salah satu ide utama adalah menggunakan Beamer untuk pembuatan slide, memungkinkan kami untuk tetap sepenuhnya berada di dalam ekosistem lateks. Pendekatan ini pada dasarnya mengubah tugas menjadi latihan peringkasan: Mengubah kertas lateks panjang menjadi lateks beamer ringkas. LLM dapat menyimpulkan konten angka -angka dari keterangan mereka dan memasukkannya ke dalam slide, menghilangkan kebutuhan akan kemampuan penglihatan.
Untuk membantu LLM, kami membuat file yang disebut ADDITIONAL.tex , yang berisi semua paket yang diperlukan, NewCommand Definition, dan pengaturan lateks lainnya yang digunakan dalam kertas. Termasuk file ini dengan input{ADDITIONAL.tex} dalam prompt memperpendeknya dan membuat slide menghasilkan lebih dapat diandalkan, terutama untuk makalah teoretis dengan banyak perintah khusus.
LLM menghasilkan kode beamer dari sumber lateks, tetapi karena menjalankan pertama mungkin memiliki masalah, kami meminta LLM untuk menuntut diri dan memperbaiki output. Secara opsional, langkah ketiga melibatkan penggunaan linter untuk memeriksa kode yang dihasilkan, dengan hasil yang diumpankan kembali ke LLM untuk koreksi lebih lanjut (langkah linter ini terinspirasi oleh ilmuwan AI). Akhirnya, kode Beamer dikompilasi ke dalam presentasi PDF menggunakan PDFLATEX.
all.zsh Script mengotomatiskan seluruh proses, biasanya diselesaikan dalam waktu kurang dari beberapa menit dengan GPT-4O untuk satu kertas.
Persyaratan adalah:
requests Perpustakaanarxivopenaiarxiv-latex-cleanerpdflatex yang berfungsiLangkah untuk Instalasi:
Klon Repositori ini:
git clone https://github.com/takashiishida/paper2slides.git
cd paper2slidesPasang paket Python yang diperlukan:
pip install requests arxiv openai arxiv-latex-cleaner Pastikan pdflatex diinstal dan tersedia di jalur sistem Anda. Periksa secara opsional apakah Anda dapat mengkompilasi test.tex sampel.tex dengan pdflatex test.tex . Periksa apakah test.pdf digenarkan dengan benar. Periksa chktex dan pdfcrop secara opsional berfungsi.
Siapkan Kunci API OpenAI Anda:
export OPENAI_API_KEY= ' your-api-key ' all.shScript ini mengotomatiskan proses mengunduh kertas Arxiv, memprosesnya, dan mengonversinya menjadi presentasi Beamer.
bash all.sh < arxiv_id > Ganti <arxiv_id> dengan ID kertas arxiv yang diinginkan. ID dapat diidentifikasi dari URL: ID untuk https://arxiv.org/abs/xxxx.xxxx adalah xxxx.xxxx .
Anda juga dapat menjalankan skrip Python secara individual untuk kontrol lebih lanjut.
Unduh dan proses file sumber arxiv
python arxiv2tex.py < arxiv_id > Script ini mengunduh file sumber dari kertas Arxiv yang ditentukan, mengekstraknya, dan memproses file lateks utama. Hasil akan disimpan di source/<arxiv_id>/FLATTENED.tex dan source/<arxiv_id>/ADDITIONAL.tex .
Konversi lateks menjadi beamer
python tex2beamer.py --arxiv_id < arxiv_id > Skrip ini membaca file lateks yang diproses dan menyiapkan slide beamer. Di sinilah kami menggunakan API Openai. Kami menelepon dua kali, pertama untuk menghasilkan kode Beamer, dan kemudian untuk menginspeksi diri kode Beamer. Secara opsional gunakan flag berikut: --use_linter dan --use_pdfcrop . Prompt yang dikirim ke LLM dan respons dari LLM akan disimpan di tex2beamer.log . Log Linter akan disimpan di source/<arxiv_id>/linter.log .
Konversi Beamer ke PDF
python beamer2pdf.py < arxiv_id >Script ini menyusun file Beamer ke dalam presentasi PDF.
Prompt disimpan di prompt_initial.txt , prompt_update.txt , dan prompt_revise.txt tetapi jangan ragu untuk menyesuaikannya dengan kebutuhan Anda. Mereka berisi placeholder yang disebut PLACEHOLDER_FOR_FIGURE_PATHS . Ini akan diganti dengan jalur gambar yang digunakan di koran. Kami ingin memastikan jalurnya digunakan dengan benar dalam kode Beamer. LLM sering membuat kesalahan, jadi kami secara eksplisit memasukkan ini di prompt.
Tingkat keberhasilan sekitar 90 persen dalam pengalaman saya (kompilasi mungkin gagal atau jalur gambar mungkin salah dalam beberapa kasus). Jika Anda menghadapi masalah atau memiliki saran untuk perbaikan, jangan ragu untuk memberi tahu saya!


