l2p
1.0.0
Basis kode ini berisi implementasi dua metode pembelajaran berkelanjutan:
L2P adalah teknik pembelajaran berkelanjutan baru yang belajar secara dinamis mendorong model pra-terlatih untuk mempelajari tugas secara berurutan di bawah transisi tugas yang berbeda. Berbeda dari metode berbasis latihan utama atau berbasis arsitektur, L2P tidak memerlukan buffer latihan atau identitas tugas waktu tes. L2P dapat digeneralisasi ke berbagai pengaturan pembelajaran berkelanjutan termasuk pengaturan agnostik-agnostik yang paling menantang dan realistis. L2P secara konsisten mengungguli metode canggih sebelumnya. Anehnya, L2P mencapai hasil kompetitif terhadap metode berbasis latihan bahkan tanpa buffer latihan.
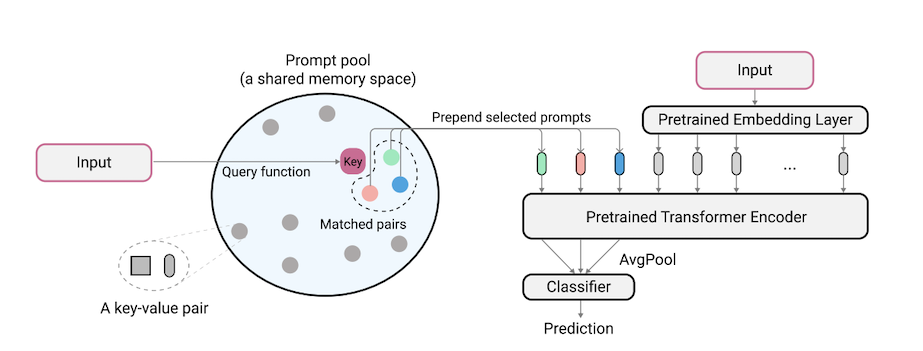
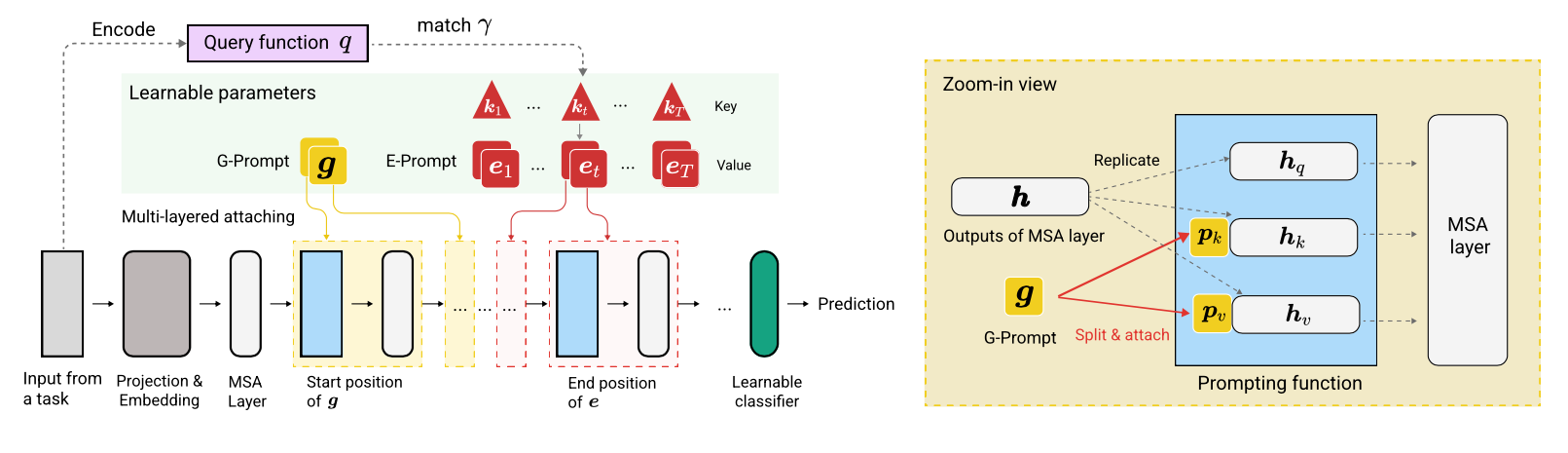
Kode ditulis oleh Zifeng Wang. Pengakuan untuk https://github.com/google-research/nested-transformer.
Ini bukan produk Google yang didukung secara resmi.
Benchmark Imagenet-R Split dibangun berdasarkan Imagenet-R dengan membagi 200 kelas menjadi 10 tugas dengan 20 kelas per tugas, lihat libml/input_pipeline.py untuk detailnya. Kami percaya Split Imagenet-R sangat penting bagi komunitas pembelajaran berkelanjutan, karena alasan berikut:
Basis kode telah diimplementasikan kembali dalam Pytorch oleh Jaeho Lee di L2P-Pytorch dan DualPromppt-Pytorch.
pip install -r requirements.txt
Setelah ini, Anda mungkin perlu menyesuaikan versi JAX Anda sesuai dengan versi driver CUDA Anda sehingga Jax mengidentifikasi GPU Anda dengan benar (lihat masalah ini untuk lebih jelasnya).
CATATAN: Basis kode telah diuji secara tidak diuji di bawah lingkungan TPU menggunakan versi Jax terbaru. Kami saat ini sedang berupaya memverifikasi lebih lanjut lingkungan GPU.
Sebelum menjalankan percobaan untuk 5-data dan Core50, langkah persiapan dataset tambahan harus dilakukan sebagai berikut:
"PATH_TO_CORE50" dan "PATH_TO_NOT_MNIST" di libml/input_pipeline.py dengan jalur tujuan pada langkah 2 Model Vit-B/16 yang digunakan dalam makalah ini dapat diunduh di sini. Catatan: Basis kode kami sebenarnya mendukung berbagai ukuran VIT. Jika Anda ingin mencoba variasi VIT, jangan ragu untuk mengubah config.model_name dalam file konfigurasi, mengikuti opsi yang valid yang ditentukan dalam model/vit.py.
Kami menyediakan file konfigurasi untuk melatih dan mengevaluasi L2P dan DualPromppt pada beberapa tolok ukur di konfigurasi.
Untuk menjalankan L2P pada dataset benchmark:
python main.py --my_config configs/$L2P_CONFIG --workdir=./l2p --my_config.init_checkpoint=<ViT-saved-path/ViT-B_16.npz>
di mana $L2P_CONFIG dapat menjadi salah satu berikut: [cifar100_l2p.py, five_datasets_l2p.py, core50_l2p.py, cifar100_gaussian_l2p.py] .
Catatan: Kami menjalankan percobaan kami menggunakan 8 V100 GPU atau 4 TPU, dan kami menentukan ukuran batch per perangkat 16 dalam file konfigurasi. Ini menunjukkan bahwa kami menggunakan ukuran batch total 128.
Untuk menjalankan DualPromppt pada dataset Benchmark:
python main.py --my_config configs/$DUALPROMPT_CONFIG --workdir=./dualprompt --my_config.init_checkpoint=<ViT-saved-path/ViT-B_16.npz>
di mana $DUALPROMPT_CONFIG dapat menjadi salah satu berikut: [imr_dualprompt.py, cifar100_dualprompt.py] .
Kami menggunakan Tensorboard untuk memvisualisasikan hasilnya. Misalnya, jika direktori kerja yang ditentukan untuk menjalankan l2p adalah workdir=./cifar100_l2p , perintah untuk memeriksa hasil adalah sebagai berikut:
tensorboard --logdir ./cifar100_l2p
Berikut adalah metrik penting untuk dilacak, dan makna yang sesuai:
| Metrik | Keterangan |
|---|---|
| Accuracy_n | Keakuratan tugas ke-n |
| lupa | Rata -rata melupakan sampai tugas saat ini |
| avg_acc | Akurasi evaluasi rata -rata hingga tugas saat ini |
@inproceedings{wang2022learning,
title={Learning to prompt for continual learning},
author={Wang, Zifeng and Zhang, Zizhao and Lee, Chen-Yu and Zhang, Han and Sun, Ruoxi and Ren, Xiaoqi and Su, Guolong and Perot, Vincent and Dy, Jennifer and Pfister, Tomas},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={139--149},
year={2022}
}
@article{wang2022dualprompt,
title={DualPrompt: Complementary Prompting for Rehearsal-free Continual Learning},
author={Wang, Zifeng and Zhang, Zizhao and Ebrahimi, Sayna and Sun, Ruoxi and Zhang, Han and Lee, Chen-Yu and Ren, Xiaoqi and Su, Guolong and Perot, Vincent and Dy, Jennifer and others},
journal={European Conference on Computer Vision},
year={2022}
}


