rlcard
RLCard 1.0.7
中文文档
RLCard adalah toolkit untuk Penguatan Penguatan (RL) dalam permainan kartu. Ini mendukung beberapa lingkungan kartu dengan antarmuka yang mudah digunakan untuk menerapkan berbagai algoritma pembelajaran dan pencarian penguatan. Tujuan RLCard adalah untuk menjembatani pembelajaran penguatan dan permainan informasi yang tidak sempurna. RLCard dikembangkan oleh data lab di Rice dan Texas A&M University, dan kontributor komunitas.
Masyarakat:
Berita:
Permainan berikut terutama dikembangkan dan dikelola oleh kontributor komunitas. Terima kasih!
Terima kasih semua kontributor!




























Jika Anda menemukan repo ini berguna, Anda dapat mengutip:
Zha, Daochen, dkk. "RLCard: Platform untuk Penguatan Pembelajaran dalam Game Kartu." Ijcai. 2020.
@inproceedings { zha2020rlcard ,
title = { RLCard: A Platform for Reinforcement Learning in Card Games } ,
author = { Zha, Daochen and Lai, Kwei-Herng and Huang, Songyi and Cao, Yuanpu and Reddy, Keerthana and Vargas, Juan and Nguyen, Alex and Wei, Ruzhe and Guo, Junyu and Hu, Xia } ,
booktitle = { IJCAI } ,
year = { 2020 }
} Pastikan Anda memiliki Python 3.6+ dan Pip terpasang. Kami sarankan menginstal rlcard versi stabil dengan pip :
pip3 install rlcard
Instalasi default hanya akan mencakup lingkungan kartu. Untuk menggunakan implementasi Pytorch dari algoritma pelatihan, jalankan
pip3 install rlcard[torch]
Jika Anda berada di Cina dan perintah di atas terlalu lambat, Anda dapat menggunakan cermin yang disediakan oleh Tsinghua University:
pip3 install rlcard -i https://pypi.tuna.tsinghua.edu.cn/simple
Atau, Anda dapat mengkloning versi terbaru dengan (jika Anda berada di China dan GitHub lambat, Anda dapat menggunakan cermin di gitee):
git clone https://github.com/datamllab/rlcard.git
atau hanya mengkloning satu cabang untuk membuatnya lebih cepat:
git clone -b master --single-branch --depth=1 https://github.com/datamllab/rlcard.git
Lalu instal dengan
cd rlcard
pip3 install -e .
pip3 install -e .[torch]
Kami juga menyediakan metode instalasi Conda :
conda install -c toubun rlcard
Instalasi Conda hanya menyediakan lingkungan kartu, Anda perlu menginstal pytorch secara manual pada permintaan Anda.
Contoh singkat adalah seperti di bawah ini.
import rlcard
from rlcard . agents import RandomAgent
env = rlcard . make ( 'blackjack' )
env . set_agents ([ RandomAgent ( num_actions = env . num_actions )])
print ( env . num_actions ) # 2
print ( env . num_players ) # 1
print ( env . state_shape ) # [[2]]
print ( env . action_shape ) # [None]
trajectories , payoffs = env . run ()RLCARD dapat dihubungkan secara fleksibel ke berbagai algoritma. Lihat contoh -contoh berikut:
Jalankan examples/human/leduc_holdem_human.py untuk bermain dengan model Leduc Hold'em pra-terlatih. Leduc Hold'em adalah versi sederhana dari Texas Hold'em. Aturan dapat ditemukan di sini.
>> Leduc Hold'em pre-trained model
>> Start a new game!
>> Agent 1 chooses raise
=============== Community Card ===============
┌─────────┐
│░░░░░░░░░│
│░░░░░░░░░│
│░░░░░░░░░│
│░░░░░░░░░│
│░░░░░░░░░│
│░░░░░░░░░│
│░░░░░░░░░│
└─────────┘
=============== Your Hand ===============
┌─────────┐
│J │
│ │
│ │
│ ♥ │
│ │
│ │
│ J│
└─────────┘
=============== Chips ===============
Yours: +
Agent 1: +++
=========== Actions You Can Choose ===========
0: call, 1: raise, 2: fold
>> You choose action (integer):
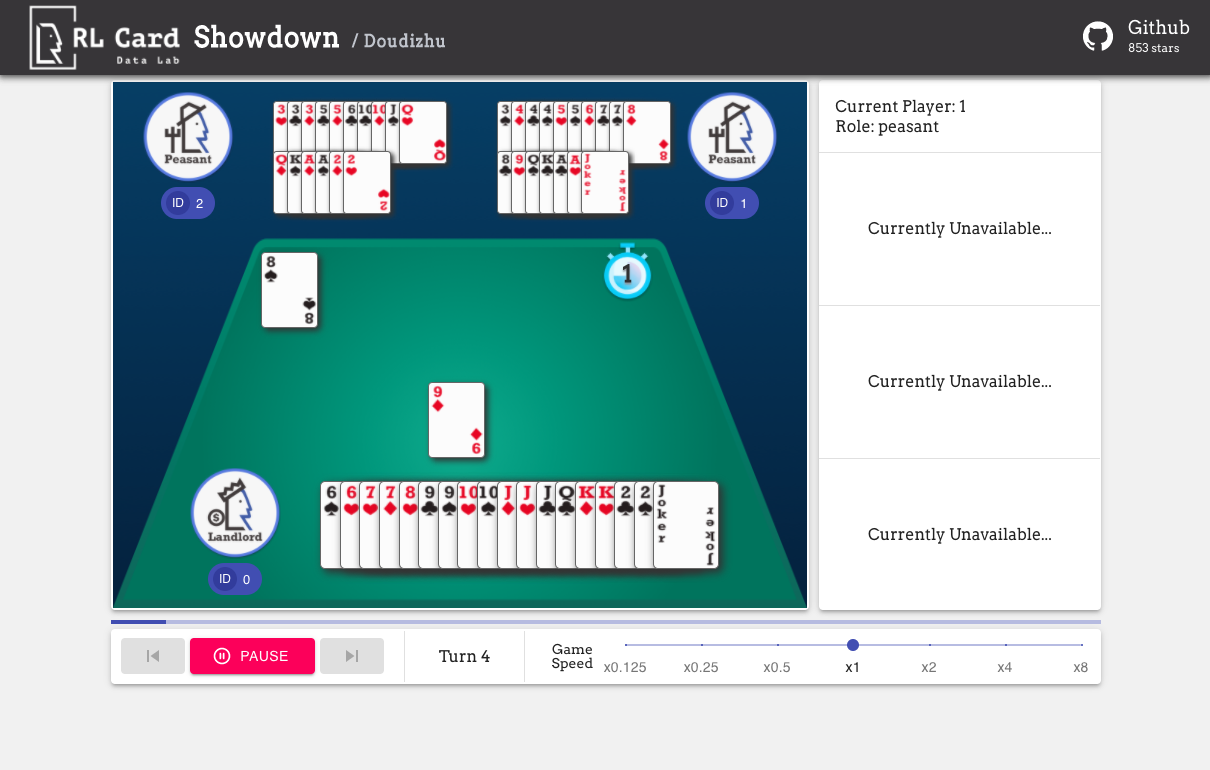
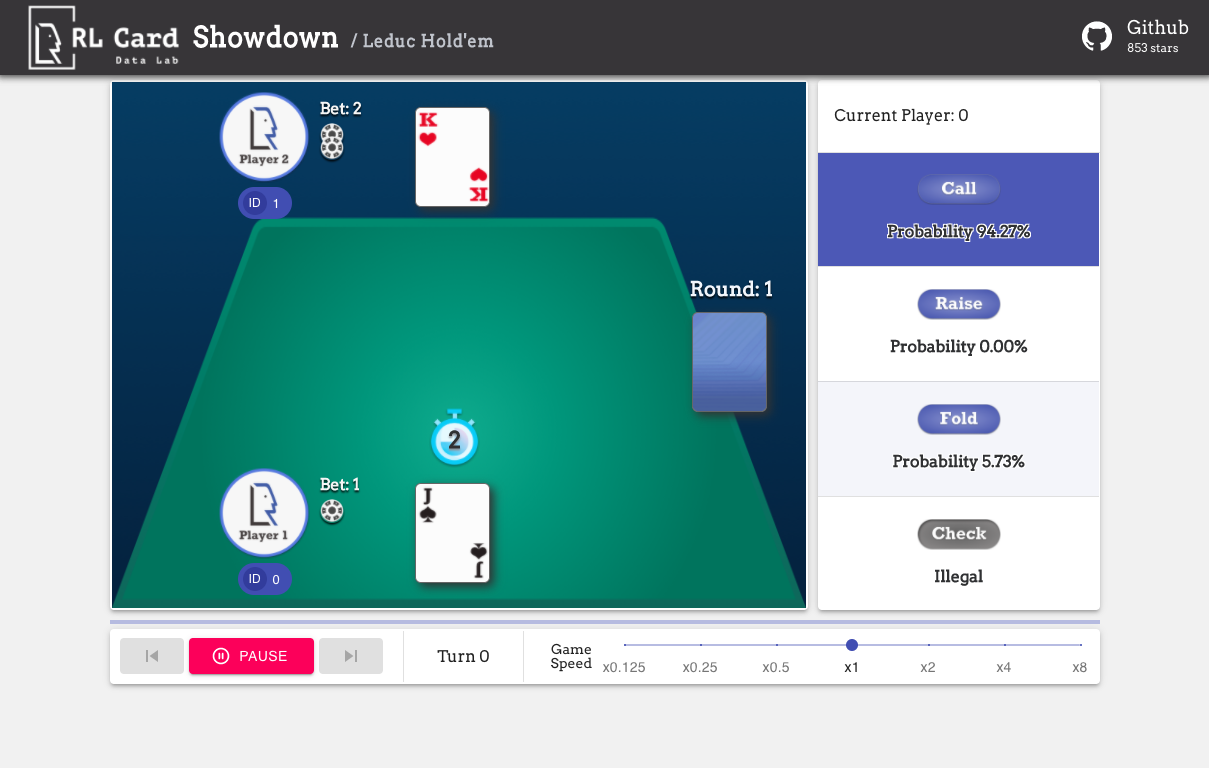
Kami juga menyediakan GUI untuk debugging yang mudah. Silakan periksa di sini. Beberapa demo:
Kami memberikan estimasi kompleksitas untuk permainan pada beberapa aspek. Nomor infoset: jumlah set informasi; Ukuran infoset: jumlah rata -rata negara bagian dalam satu set informasi; Ukuran aksi: Ukuran ruang aksi. Nama: Nama yang harus diteruskan ke rlcard.make untuk menciptakan lingkungan game. Kami juga menyediakan tautan ke dokumentasi dan contoh acak.
| Permainan | Nomor infoset | Ukuran infoset | Ukuran aksi | Nama | Penggunaan |
|---|---|---|---|---|---|
| Blackjack (Wiki, Baike) | 10^3 | 10^1 | 10^0 | selikuran | Doc, contoh |
| Leduc hold'em (kertas) | 10^2 | 10^2 | 10^0 | leduc-holdem | Doc, contoh |
| Batasi Texas Hold'em (Wiki, Baike) | 10^14 | 10^3 | 10^0 | batas-holdem | Doc, contoh |
| Dou Dizhu (Wiki, Baike) | 10^53 ~ 10^83 | 10^23 | 10^4 | Doudizhu | Doc, contoh |
| Mahjong (Wiki, Baike) | 10^121 | 10^48 | 10^2 | mahjong | Doc, contoh |
| No-limit Texas Hold'em (Wiki, Baike) | 10^162 | 10^3 | 10^4 | no-limit-holdem | Doc, contoh |
| Uno (Wiki, Baike) | 10^163 | 10^10 | 10^1 | uno | Doc, contoh |
| Gin Rummy (Wiki, Baike) | 10^52 | - | - | gin-rummy | Doc, contoh |
| Bridge (Wiki, Baike) | - | - | menjembatani | Doc, contoh |
| Algoritma | contoh | referensi |
|---|---|---|
| Deep Monte-Carlo (DMC) | Contoh/run_dmc.py | [kertas] |
| Dear-learning Deep (DQN) | Contoh/run_rl.py | [kertas] |
| Neural Fictiptips Self-Play (NFSP) | Contoh/run_rl.py | [kertas] |
| Minimalisasi penyesalan kontrafaktual (CFR) | Contoh/run_cfr.py | [kertas] |
Kami menyediakan kebun binatang model untuk berfungsi sebagai garis dasar.
| Model | Penjelasan |
|---|---|
| leduc-holdem-cfr | Model CFR pra-terlatih (Chance Sampling) pada leduc hold'em |
| leduc-holdem-aturan-V1 | Model Berbasis Aturan untuk Leduc Hold'em, V1 |
| leduc-holdem-aturan-V2 | Model Berbasis Aturan untuk Leduc Hold'em, V2 |
| uno-aturan-v1 | Model Berbasis Aturan untuk UNO, V1 |
| batas-holdem-aturan-V1 | Model Berbasis Aturan untuk Batas Texas Hold'em, V1 |
| doudizhu-aturan-v1 | Model berbasis aturan untuk Dou Dizhu, V1 |
| Gin-Rummy-Novice-aturan | Model Aturan Pemula Gin Rummy |
Anda dapat menggunakan antarmuka berikut untuk membuat lingkungan. Anda dapat secara opsional menentukan beberapa konfigurasi dengan kamus.
env_id adalah serangkaian lingkungan; config adalah kamus yang menentukan beberapa konfigurasi lingkungan, yaitu sebagai berikut.seed : Default None . Tetapkan biji acak lokal lingkungan untuk mereproduksi hasilnya.allow_step_back : False default. True jika memungkinkan fungsi step_back untuk melintasi ke belakang di pohon.game_ . Saat ini, kami hanya mendukung game_num_players di Blackjack ,.Setelah Environemnt dibuat, kami dapat mengakses beberapa informasi permainan.
Negara adalah kamus Python. Ini terdiri dari state['obs'] , tindakan hukum state['legal_actions'] , state['raw_obs'] dan tindakan hukum mentah state['raw_legal_actions'] .
Antarmuka berikut memberikan penggunaan dasar. Mudah digunakan tetapi memiliki asumsi pada agen. Agen harus mengikuti templat agen.
agents adalah daftar objek Agent . Panjang daftar harus sama dengan jumlah pemain dalam permainan.set_agents dipanggil. Jika is_training True , itu akan menggunakan fungsi step dalam agen untuk memainkan game. Jika is_training False , eval_step akan dipanggil sebagai gantinya.Untuk penggunaan lanjutan, antarmuka berikut memungkinkan operasi fleksibel pada pohon game. Antarmuka ini tidak membuat asumsi pada agen.
action dapat berupa tindakan mentah atau bilangan bulat; raw_action harus True jika tindakannya adalah tindakan mentah (string).allow_step_back True . Ambil satu langkah mundur. Ini dapat digunakan untuk algoritma yang beroperasi di pohon game, seperti CFR (Chance Sampling).True jika game saat ini sudah berakhir. Otherwise, kembalikan False .player_id .Tujuan modul utama terdaftar di bawah ini:
Untuk dokumentasi lebih lanjut, silakan merujuk ke dokumen untuk perkenalan umum. Dokumen API tersedia di situs web kami.
Kontribusi untuk proyek ini sangat dihargai! Harap buat masalah untuk umpan balik/bug. Jika Anda ingin berkontribusi kode, silakan merujuk ke Panduan Kontribusi. Jika Anda memiliki pertanyaan, silakan hubungi Daochen Zha dengan [email protected].
Kami ingin mengucapkan terima kasih kepada JJ World Network Technology Co., Ltd atas dukungan yang murah hati dan semua kontribusi dari kontributor masyarakat.


