kubeai
helm-chart-models-0.9.0
Dapatkan menyimpulkan berjalan di Kubernetes: llms, embeddings, ucapan-ke-teks.
✅️ Penggantian drop-in untuk openai dengan kompatibilitas API
⚖️ Skala dari nol, autoscale berdasarkan beban
? Sajikan model pembuatan teks (LLM, VLM, dll.)
Pidato ke API Teks
? Embedding/vector API
Multi-Platform: CPU-only, GPU, TPU
? Model caching dengan sistem file bersama (EFS, filestore, dll.)
Nol dependensi (tidak bergantung pada istio, knative, dll.)
Obrolan UI Termasuk (OpenWebui)
? Mengoperasikan Server Model OSS (VLLM, Ollama, Fasterwhisper, Infinity)
✉ Stream/Batch Inference melalui Integrasi Pesan (Kafka, Pubsub, dll.)
Kutipan dari komunitas:
Solusi yang dapat digunakan kembali, abstrak dengan baik untuk menjalankan LLMS - Mike Ensor
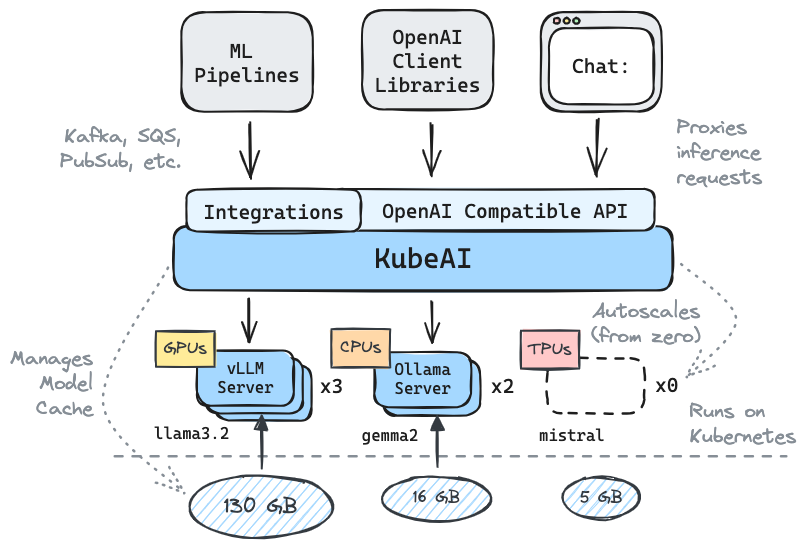
Kubeai menyajikan HTTP API yang kompatibel dengan OpenAI. Admin dapat mengonfigurasi model ML melalui kind: Model Kubernetes Sumber Daya Kustom. Kubeai dapat dianggap sebagai operator model (lihat pola operator) yang mengelola server VLLM dan Ollama.
Buat cluster lokal menggunakan jenis atau minikube.
# You might need to stop and remove the existing machine:
podman machine stop
podman machine rm
# Init and start a new machine:
podman machine init --memory 6144 --disk-size 120
podman machine startkind create cluster # OR: minikube startTambahkan repositori Helm Kubeai.
helm repo add kubeai https://www.kubeai.org
helm repo updateInstal Kubeai dan tunggu semua komponen siap (mungkin membutuhkan waktu satu menit).
helm install kubeai kubeai/kubeai --wait --timeout 10mInstal beberapa model yang telah ditentukan.
cat << EOF > kubeai-models.yaml
catalog:
gemma2-2b-cpu:
enabled: true
minReplicas: 1
qwen2-500m-cpu:
enabled: true
nomic-embed-text-cpu:
enabled: true
EOF
helm install kubeai-models kubeai/models
-f ./kubeai-models.yamlSebelum maju ke langkah selanjutnya, mulailah jam tangan di pod di terminal mandiri untuk melihat bagaimana Kubeai menggunakan model.
kubectl get pods --watch Karena kami mengatur minReplicas: 1 untuk model Gemma, Anda harus melihat pod model yang sudah muncul.
Mulailah port-forward lokal ke UI obrolan yang dibundel.
kubectl port-forward svc/openwebui 8000:80Sekarang buka browser Anda ke LocalHost: 8000 dan pilih model Gemma untuk mulai mengobrol.
Jika Anda kembali ke browser dan memulai obrolan dengan QWEN2, Anda akan melihat bahwa perlu beberapa saat untuk merespons pada awalnya. Ini karena kami mengatur minReplicas: 0 untuk model ini dan Kubeai perlu memutar pod baru (Anda dapat memverifikasi dengan kubectl get models -oyaml qwen2-500m-cpu ).
Lihat dokumentasi kami di Kubeai.org untuk menemukan info tentang:
Daftar pengadopsi yang diketahui:
| Nama | Keterangan | Link |
|---|---|---|
| Teleskop | Telescope menggunakan Kubeai untuk inferensi LLM multi-region berskala besar. | trytelescope.ai |
| Google cloud terdistribusi tepi | Kubeai dimasukkan sebagai arsitektur referensi untuk inferencing di tepi. | LinkedIn, Gitlab |
| Lambda | Anda dapat mencoba Kubeai di Lambda AI Developer Cloud. Lihat tutorial dan video Lambda. | Lambda |
Jika Anda menggunakan Kubeai dan ingin terdaftar sebagai pengadopsi, silakan buat PR.
# Implemented #
/v1/chat/completions
/v1/completions
/v1/embeddings
/v1/models
/v1/audio/transcriptions
# Planned #
# /v1/assistants/*
# /v1/batches/*
# /v1/fine_tuning/*
# /v1/images/*
# /v1/vector_stores/* Catatan: Kubeai lahir dari proyek bernama Lingo yang merupakan proxy Kubernetes LLM sederhana dengan autoscaling dasar. Kami meluncurkan kembali proyek tersebut sebagai Kubeai (akhir Agustus 2024) dan memperluas peta jalan ke seperti sekarang ini.
? Jangan lupa untuk membuat kami bintang di GitHub dan ikuti repo untuk tetap up to date!
Beri tahu kami tentang fitur yang Anda minati untuk melihat atau menjangkau dengan pertanyaan. Kunjungi Saluran Perselisihan kami untuk bergabung dengan diskusi!
Atau cukup hubungi di LinkedIn jika Anda ingin terhubung:


