Reading_groups
1.0.0
Kekuatan Komputasi : Banyak bukti menunjukkan bahwa kemajuan dalam pembelajaran mesin sebagian besar didorong oleh komputasi, bukan penelitian, silakan merujuk pada "pelajaran pahit", dan sering ada fenomena kemunculan dan homogenisasi. Studi telah menunjukkan bahwa penggunaan komputasi kecerdasan buatan berlipat ganda setiap 3,4 bulan, sedangkan peningkatan efisiensi hanya dua kali lipat setiap 16 bulan. Di antara mereka, jumlah perhitungan terutama didorong oleh daya komputasi, sedangkan efisiensi didorong oleh penelitian. Ini berarti bahwa pertumbuhan komputasi secara historis mendominasi kemajuan dalam pembelajaran mesin dan subbidangnya. Ini lebih lanjut dibuktikan dengan kemunculan GPT-4. Meskipun demikian, kita masih perlu memperhatikan apakah akan ada arsitektur yang lebih ditumbangkan di masa depan, seperti S4. Sebagian besar hotspot penelitian NLP saat ini didasarkan pada LLM yang lebih canggih (~ 100b,
Untuk lebih banyak makalah LLM Topik, silakan merujuk di sini dan di sini.
Makalah ( kategori kasar )
sumber
【Pengujian pada GPT-4, Batasan】 Percakan Kecerdasan Umum Buatan: Eksperimen Awal dengan GPT-4
【Makalah Instruksikan, termasuk SFT, PPO, dll., Salah satu artikel terpenting】 Model bahasa pelatihan untuk mengikuti instruksi dengan umpan balik manusia
【Pengawasan yang dapat diskalakan: Bagaimana manusia dapat terus meningkatkan model mereka setelah model mereka melebihi tugas mereka sendiri? 】 Mengukur kemajuan pada pengawasan yang dapat diskalakan untuk model bahasa besar
【Definisi Penyelarasan, Diproduksi oleh DeepMind】 Penyelarasan Agen Bahasa
Asisten Bahasa Umum sebagai Laboratorium untuk Alignment
[Kertas retro, model dicari menggunakan CCA+] meningkatkan model bahasa dengan mengambil dari triliunan token
Model bahasa yang menyempurnakan dari preferensi manusia
Melatih asisten yang membantu dan tidak berbahaya dengan pembelajaran penguatan dari umpan balik manusia
【Model besar dalam bahasa Cina dan Inggris, melebihi GPT-3】 GLM-130B: Model pra-terlatih bilingual terbuka
【Optimalisasi Target Pra-Pelatihan】 UL2: Paradigma Pembelajaran Bahasa yang Menyatu
【Tolok ukur baru Alignment, perpustakaan model dan metode baru】 Apakah pembelajaran penguatan (bukan) untuk pemrosesan bahasa alami?: Tolok Ukur, Baseline, dan Blok Bangunan untuk Optimalisasi Kebijakan Bahasa Alami Optimalisasi Bahasa Alami
【MLM tanpa tag [topeng] melalui Teknologi】 Kekurangan representasi dalam pemodelan bahasa bertopeng
【Teks untuk pelatihan gambar mengurangi kebutuhan kosa kata dan menolak serangan tertentu】 pemodelan bahasa dengan piksel
Lexmae: pretraining leksikon-bottlenecked untuk pengambilan skala besar
Inkoder: Model Generatif untuk Pengisian dan Sintesis Kode
[Cari gambar terkait teks untuk model bahasa pra-pelatihan]
Model Bahasa Mandiri Non-Monotonik
【Perbandingan dan penyempurnaan umpan balik negatif melalui desain propt】 Rantai Hindsight menyelaraskan model bahasa dengan umpan balik
【Model Sparrow】 Meningkatkan penyelarasan agen dialog melalui penilaian manusia yang ditargetkan
[Gunakan parameter model kecil untuk mempercepat proses pelatihan model besar (tidak mulai dari awal)] belajar menumbuhkan model pretrain untuk pelatihan transformator yang efisien
[MOE MOD Model Fusion Pengetahuan Semi-Parametrik untuk Berbagai Sumber Pengetahuan] Pengetahuan-dalam-Konteks: Menuju Model Bahasa Semi-Parametrik yang Berpengetahuan
[Metode gabungkan untuk menggabungkan beberapa model terlatih pada dataset yang berbeda] fusi pengetahuan dataless dengan menggabungkan bobot model bahasa
[Sangat menginspirasi bahwa mekanisme pencarian menggantikan arsitektur umum FFN dalam transformator (× 2.54 waktu) untuk memisahkan pengetahuan yang disimpan dalam parameter model] Model Bahasa dengan memori Plug-in Knowldge
【Secara otomatis menghasilkan data tuning instruksi untuk pelatihan GPT-3】 Instruksi diri: Menyelaraskan model bahasa dengan instruksi yang dihasilkan sendiri
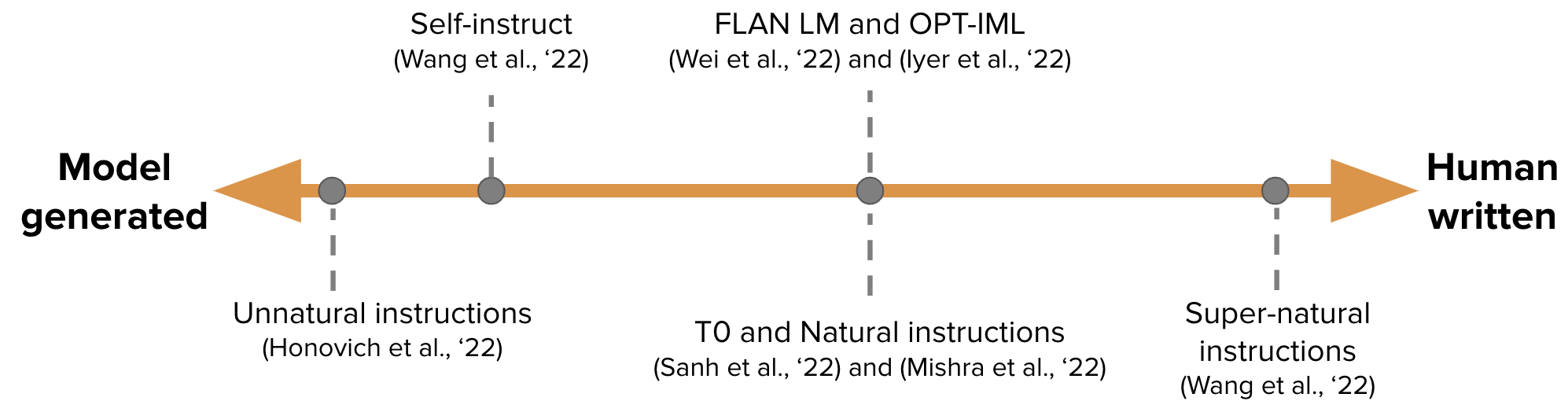
- 
Menuju model bahasa bertopeng yang bergantung secara kondisional
【Secara iteribrate secara tidak sempurna menghasilkan koreksi independen, artikel tindak lanjut Sean Welleck】 menghasilkan urutan dengan belajar untuk mengoreksi diri sendiri
[Pembelajaran berkelanjutan: Tambahkan propt untuk tugas baru, dan propt tugas sebelumnya dan model besar tetap tidak berubah] prompt progresif: pembelajaran berkelanjutan untuk model bahasa tanpa lupa
[EMNLP 2022, Pembaruan Berkelanjutan dari Model] MEMPROMPT: Pengeditan cepat yang dibantu memori dengan umpan balik pengguna
【Arsitektur saraf baru (folnet), yang berisi bias induksi logis orde pertama】 representasi bahasa pembelajaran dengan bias induktif logis
Ganlm: pra-pelatihan encoder-decoder dengan diskriminator tambahan
Model Model Bahasa Pretraining Berdasarkan Model ruang negara bagian, melebihi Bert】 pretraining tanpa perhatian
[Pertimbangkan umpan balik manusia selama pra-pelatihan] Model bahasa pretraining dengan preferensi manusia
[Model Llama Open Source Meta, 7B-65B, melatih lebih banyak model kecil berlabel dari biasanya, mencapai kinerja optimal di bawah berbagai anggaran inferensi] llama: model bahasa yayasan terbuka dan efisien
[Mengajar model bahasa besar untuk mendebug diri sendiri dan menjelaskan kode yang dihasilkan melalui sejumlah kecil contoh, tetapi mereka telah digunakan seperti ini sekarang] mengajarkan model bahasa besar untuk mendebug diri sendiri
Seberapa jauh unta bisa pergi?
Lima: Lebih sedikit lebih banyak untuk penyelarasan
【Tree-of-Thought, semakin seperti Alphago】 Penyelesaian Masalah yang Disengaja Dengan Model Bahasa Besar
【Metode penalaran multi-langkah untuk menerapkan ICL sangat menginspirasi】 Bereaksi: Sinergis penalaran dan bertindak dalam model bahasa
【COT secara langsung menghasilkan kode program, dan kemudian memungkinkan Python Interpreter mengeksekusi】 Program pemikiran yang diminta: Menghilangkan perhitungan dari penalaran untuk tugas penalaran numerik
[Model besar secara langsung menghasilkan konteks bukti] menghasilkan daripada mengambil: model bahasa besar adalah generator konteks yang kuat
【Model Penulisan dengan 4 Operasi Spesifik】 Peer: Model Bahasa Kolaboratif
【Menggabungkan Python, Eksekutor SQL dan Model Besar】 Model Bahasa yang Mengikat dalam Bahasa Simbolik
[Ambil kode pembuatan dokumen] Docprompting: Menghasilkan kode dengan mengambil dokumen
[Akan ada banyak artikel di landasan+llm di seri berikutnya] LLM-Planner: beberapa perencanaan ground untuk agen yang diwujudkan dengan model bahasa besar
【Generasi Diri (Diverifikasi Menggunakan Python) Data Pelatihan】 Model bahasa dapat mengajar diri mereka sendiri untuk memprogram dengan lebih baik
Artikel terkait: Mengkhususkan model bahasa yang lebih kecil menuju penalaran multi-langkah
Bintang: Penalaran bootstrap dengan penalaran, dari Neurips 22 (menghasilkan data COT untuk fine-tuning model), menyebabkan serangkaian artikel COT yang mengajar model kecil.
Ide serupa [Distilasi Pengetahuan] Mengajar Model Bahasa Kecil untuk Beralih dan Belajar dengan Menyaring Konteks
Ide-Ide Serupa Kaist dan kelompok Xiang Ren ([COT's Rationale Fine-Tuning (Profesor)] Pinto: Alasan Bahasa yang Setia Menggunakan Rasional yang Dihasilkan Segera, dll.) Dan model bahasa besar adalah penalaran guru
ETH [COT Data melatih masalah dekomposisi dan model pemecahan masalah secara terpisah] menyuling kemampuan penalaran multi-langkah dari model bahasa besar menjadi model yang lebih kecil melalui dekomposisi semantik
【Biarkan model kecil mempelajari kemampuan cot】 Distilasi pembelajaran dalam konteks: mentransfer kemampuan belajar beberapa-shot dari model bahasa pra-terlatih
【Model Besar Mengajarkan Model Kecil Cot】 Model Bahasa Besar adalah Guru yang Beralasan
[Model besar menghasilkan bukti (pembacaan) dan kemudian melakukan pertanyaan dan jawaban buku tertutup sampel kecil]
[Metode Bahasa Alami dari Alasan Induktif] Model Bahasa sebagai Alasan Induktif
[GPT-3 digunakan untuk anotasi data (seperti klasifikasi emosional)] adalah GPT-3 annotator data yang baik?
【Model untuk augmentasi data berdasarkan pelatihan multitasking untuk lebih sedikit sampel augmentasi data】 Knowda: model campuran pengetahuan all-in-one untuk augmentasi data di NLP sumber daya rendah
【Pekerjaan perencanaan prosedural, tidak tertarik pada waktu menjadi】 perencanaan prosedural simbolik neuro dengan diminta akal sehat
[Tujuan: Hasilkan artikel yang benar secara faktual untuk pertanyaan dengan mendarat di Corpus Web Besar
【Menggabungkan hasil simulator fisika eksternal dalam konteks】 Mata pikiran: Model bahasa ground beralasan melalui simulasi
[Ambil tugas meningkatkan cot untuk melakukan pengetahuan intensif] pengambilan interleaving dengan penalaran rantai untuk pertanyaan multi-langkah yang intensif pengetahuan
【Kontras Potensi (biner) pengetahuan dalam model bahasa pengakuan tanpa pengawasan】 Menemukan pengetahuan laten dalam model bahasa tanpa pengawasan
[Grup Percy Liang, mesin pencari tepercaya, hanya 51,5% dari kalimat yang dihasilkan didukung sepenuhnya oleh kutipan] mengevaluasi verifikasi dalam mesin pencari generatif
Progressive-hint corongan meningkatkan penalaran dalam model bahasa besar
Penyelarasan diri yang didorong oleh prinsip model bahasa dari awal dengan pengawasan manusia minimal
Menilai LLM-AS-A-Hakim dengan MT-Bench dan Chatbot Arena
[Menurut saya, ini adalah salah satu artikel terpenting. pelatihan, dan lebar dan kedalaman detail arsitektur seperti lebar dan kedalaman.
[Salah satu artikel terpenting lainnya, Chinchilla, di bawah komputasi terbatas, model optimal bukan model terbesar, tetapi model yang lebih kecil yang dilatih dengan lebih banyak data (60-70b)] pelatihan komputasi model bahasa besar optimal optimal besar
[Arsitektur dan sasaran optimisasi mana yang membantu generalisasi sampel nol] Arsitektur model bahasa apa dan pekerjaan objektif yang paling baik untuk generalisasi zero-shot?
【Grokking "Epiphany" Proses Pembelajaran Mengorisasi-> Formasi Sirkuit-> Pembersihan】 Langkah-langkah kemajuan untuk grokking melalui interpretasi mekanistik
[Selidiki karakteristik model berbasis pencarian dan temukan bahwa keduanya memiliki penalaran terbatas] dapat membuat model bahasa Retriever-Agusted?
[Kerangka Evaluasi Interaksi Bahasa Manusia-Ai] Mengevaluasi Interaksi Model Bahasa Manusia
Algoritma pembelajaran apa yang sedang dibahas?
【Pengeditan model, ini adalah topik hangat】 Memori pengeditan massal dalam transformator
[Sensitivitas model terhadap konteks yang tidak relevan, menambahkan informasi yang tidak relevan ke dalam contoh -contoh dalam prompt dan menambahkan instruksi yang mengabaikan konteks yang tidak relevan sebagian menyelesaikan] model bahasa besar dapat dengan mudah terganggu oleh konteks yang tidak relevan
【Cot Zero-Shot akan menunjukkan bias dan toksisitas di bawah masalah sensitif】 pada pemikiran kedua, jangan berpikir langkah demi langkah!
【Cot dari model besar memiliki kemampuan lintas bahasa】 Model bahasa adalah alasan rantai multibahasa
[Semakin rendah kebingungan dari urutan prompt yang berbeda, semakin baik kinerja] Demosi pengabaian dalam model bahasa melalui estimasi kebingungan
[Tugas Resolusi Implicity Biner dari Model Besar, Saran ini sulit dan tidak ada fenomena penskalaan] Model bahasa besar bukanlah komunikator nol-shot (https://github.com/google/big-bence/tree/main/bigbench/ Benchmark_Tasks/ implicity)
【Diminta berbasis kompleksitas untuk penalaran multi-langkah
Apa yang penting dalam pemangkasan terstruktur model bahasa generatif?
[Dataset Ambibench, Ambiguitas Tugas: Model RLHF penskalaan berkinerja terbaik dalam tugas -tugas disambiguating. Fine-tuning lebih bermanfaat daripada beberapa penembakan yang mendorong】 ambiguitas tugas pada manusia dan model bahasa
【Tes GPT-3, termasuk memori, kalibrasi, bias, dll.】 Meminta GPT-3 menjadi dapat diandalkan
[Studi OSU Bagian COT mana yang efektif untuk kinerja] menuju pemahaman dorongan rantai-pemikiran: studi empiris tentang apa yang penting
[Penelitian tentang model lintas-bahasa dari dorongan diskrit] Dapatkah ekstraksi informasi diskrit menggeneralisasi seluruh model bahasa?
【Laju memori adalah hubungan linier logaritmik dengan ukuran model, panjang awalan dan laju pengulangan dalam pelatihan】 Mengukur hafalan di seluruh model bahasa saraf
【Sangat menginspirasi, menguraikan masalah menjadi sub-pertanyaan melalui iterasi GPT dan menjawabnya】 mengukur dan mempersempit kesenjangan komposisi dalam model bahasa
[Tes analog GPT-3 mirip dengan pertanyaan kecerdasan pegawai negeri] yang muncul sebagai penalaran analog dalam model bahasa besar
【Pelatihan Teks Pendek, Pengujian Teks Panjang, Evaluasi Model Variabel Panjang Adaptasi】 Transformator Panjang-Ekstrapolasi
[Ketika tidak mempercayai model bahasa: menyelidiki efektivitas dan keterbatasan ingatan parametrik dan non-parametrik
【ICL adalah bentuk pembaruan gradien lain】 Mengapa GPT dapat belajar dalam konteks?
Apakah GPT-3 seorang psikopat?
[Penelitian tentang proses pelatihan model opt dalam ukuran yang berbeda, dan menemukan bahwa kebingungan adalah indikator ICL] lintasan pelatihan model bahasa di seluruh skala
[EMNLP 2022, Corpus Bahasa Inggris Murni yang sudah terlatih berisi bahasa lain, dan kemampuan bahasa lintas model mungkin berasal dari kebocoran data] Kontaminasi bahasa membantu menjelaskan kemampuan lintas-bahasa dari model pretrained Inggris
[Mengesampingkan prior semantik dan menggunakan informasi dalam propt adalah kemampuan lonjakan] model bahasa yang lebih besar melakukan pembelajaran dalam konteks secara berbeda
【Temuan EMNLP 2022】 Model bahasa apa yang akan dilatih jika Anda memiliki satu juta jam GPU?
[Memperkenalkan teknologi CFG selama penalaran sangat meningkatkan kemampuan kepatuhan instruksi dari model kecil] tetap pada topik dengan panduan bebas classifier
【Latih model llama Anda sendiri dengan Openai's GPT-4, dan saya hanya bisa mengatakan saya mengagumi Anda】 Tuning Instruksi dengan GPT-4
Refleksi: agen otonom dengan memori dinamis dan refleksi diri
【Pembelajaran cepat gaya yang dipersonalisasi, opt】 permintaan yang dapat diperpanjang untuk model bahasa
[Mempercepat decoding model besar, menggunakan konsensus langsung antara model kecil dan model besar yang akan digunakan beberapa kali sekaligus, input akan sangat lambat jika panjang] mempercepat decoding model bahasa besar dengan pengambilan sampel khusus
[Gunakan soft prompt untuk mengurangi penurunan kemampuan ICL yang disebabkan oleh fine tuning, menyempurnakan tahap pertama, menyempurnakan tahap kedua] menjaga kemampuan belajar dalam konteks dalam fine-tuning model bahasa besar
【Tugas parsing semantik, metode pemilihan sampel ICL, Codex dan T5-Large】 Beragam demonstrasi meningkatkan generalisasi komposisi dalam konteks
【Metode optimasi baru untuk pembuatan teks】 Menyesuaikan model pembuatan bahasa di bawah jarak variasi total
[Estimasi ketidakpastian pembuatan bersyarat, menggunakan pengelompokan semantik yang dikombinasikan dengan beberapa output pengambilan sampel untuk memperkirakan entropi kluster] ketidakpastian semantik: invarian linguistik untuk estimasi ketidakpastian dalam generasi bahasa alami
Go-tuning: Meningkatkan kemampuan belajar zero-shot dari model bahasa yang lebih kecil
【Metode pembuatan teks yang sangat menginspirasi di bawah kendala teks gratis】 pembuatan teks yang dapat dikendalikan dengan kendala bahasa
[Saat menghasilkan prediksi, gunakan kesamaan untuk memilih frasa alih -alih token softmax] pemodelan bahasa bertopeng nonparametrik
[Metode ICL untuk teks panjang] Windows konteks paralel meningkatkan pembelajaran dalam-konteks model bahasa besar
【Sampel model instruktur yang menghasilkan ICL dengan sendirinya】 Model bahasa besar yang memicu diri sendiri untuk QA domain terbuka
【Mekanisme Transfer dan Perhatian memungkinkan ICL untuk memasukkan lebih banyak sampel anotasi】 Didorong terstruktur: Penskalaan pembelajaran dalam konteks ke 1.000 contoh
Kalibrasi momentum untuk pembuatan teks
【Dua metode pemilihan sampel ICL, percobaan berdasarkan OPT dan GPTJ】 Kurasi data yang cermat menstabilkan pembelajaran dalam konteks
【Analisis indikator evaluasi ungu muda (Pillutla et al.)】 Tentang kegunaan embedding, cluster dan string untuk evaluasi pembuatan teks
Promptagator: beberapa pengambilan padat beberapa kali dari 8 contoh
[Tiga Cobblers, Zhuge Liang] Konsistensi diri meningkatkan penalaran rantai pemikiran dalam model bahasa
[Balikkan, input, dan label menghasilkan instruksi untuk kondisi] Tebak instruksi!
Derivasi Derivasi Terbalik LLM Verifikasi Diri】 Model bahasa besar adalah alasan dengan verifikasi diri sendiri
【Metode untuk Pencarian - Skenario Keselamatan Di bawah proses menghasilkan bukti】 foveate, atribut, dan rasionalisasi: Menuju AI yang aman dan dapat dipercaya
[Estimasi kepercayaan fragmen yang diekstraksi dengan informasi yang dihasilkan teks berdasarkan pencarian balok] Bagaimana pencarian balok meningkatkan estimasi kepercayaan level rentang dalam pelabelan urutan generatif?
SPT: tuning prompt semi-parametrik untuk multitask yang diminta pembelajaran
【Diskusi tentang Ringkasan Label Emas Ringkasan】 Ringkasan teks dengan ekspektasi Oracle
【Metode Deteksi OOD berdasarkan jarak Mars】 Deteksi out-of-distribusi dan generasi selektif untuk model bahasa bersyarat
[Modul Perhatian Mengintegrasikan Prompt untuk Memprediksi Level Sampel] Model Ensemble Alih-alih Fusi Prompt: Metode Transfer Pengetahuan-Khusus Sampel untuk beberapa Tuning Prompt beberapa-shot
【Prompt untuk beberapa tugas dengan dekomposisi dan distilasi menjadi satu prompt】 Multitask Prompt Tuning memungkinkan pembelajaran transfer yang efisien parameter
[Indikator evaluasi dari penalaran langkah demi langkah teks yang dihasilkan dapat digunakan sebagai topik untuk dibagikan waktu berikutnya] Roscoe: Serangkaian metrik untuk mencetak penalaran langkah demi langkah
[Kalibrasi kemungkinan urutan meningkatkan generasi bahasa bersyarat]
【Metode serangan teks berdasarkan optimasi gradien】 TextGrad: Memajukan evaluasi ketahanan dalam NLP dengan optimasi yang digerakkan oleh gradien
[Pemodelan GMM Batas Klasifikasi Keputusan ICL Untuk mengkalibrasi] Kalibrasi prototipikal untuk pembelajaran beberapa shot dari model bahasa
【Masalah penulisan ulang, dan metode agregasi ICL berbasis grafik】 Tanyakan apa saja: Strategi sederhana untuk mendorong model bahasa
[Database untuk memilih kandidat yang baik sebagai ICLS dari kumpulan contoh yang tidak ternotasi] Anotasi selektif membuat model bahasa lebih baik beberapa pelajar shot
PromptBoosting: Klasifikasi teks kotak hitam dengan sepuluh operan maju
Serangan backdoor yang dipandu perhatian terhadap Transformers
【Posisi Prompt Posisi Label Otomatis】 Model bahasa pra-terlatih dapat sepenuhnya menjadi pelajar zero-shot
[Kompres panjang vektor input FID dan order ulang saat output ke peringkat dokumen output] FID-LIGH
【Penjelasan tentang Generasi Model Besar】 Pinto: Penalaran Bahasa yang Setia Menggunakan Rasional yang Didorong
【Temukan subset dampak pra-pelatihan】 orca: menafsirkan model bahasa yang diminta melalui lokasi pendukung lokasi di lautan data pretraining
[Proyek Prompt, yang ditujukan untuk instruksi, menghasilkan model penyaringan besar tahap pertama dan dua tahap] adalah insinyur prompt tingkat manusia
Pengetahuan yang tidak belajar untuk mengurangi risiko privasi dalam model bahasa
Mengedit model dengan aritmatika tugas
[Jangan masukkan instruksi dan sampel setiap kali, ubah menjadi modul yang efisien parameter,] Petunjuk: Tuning Instruksi Hypernetwork untuk Generalisasi Zero-Shot yang efisien
[Metode pembuatan tampilan ICL tanpa pemilihan sampel manual] Z-ICL: Pembelajaran dalam konteks nol-shot dengan demonstrasi semu
[Instruksi tugas dan teks menghasilkan penyematan bersama] satu embedder, tugas apa pun: embeddings teks yang disetel instruksi
【Model Besar Mengajar Model Kecil Cot】 Pisau: Distilasi Pengetahuan dengan Rasional teks bebas
[Masalah ketidakkonsistenan antara sumber dan target segmentasi kata dari model pembuatan ekstraksi informasi] Konsistensi tokenisasi penting untuk model generatif pada tugas NLP ekstraktif
Parsel: Kerangka kerja bahasa alami yang terpadu untuk penalaran algoritmik
[Pemilihan sampel ICL, pemilihan fase pertama dan penyortiran fase kedua] Pembelajaran dalam konteks self-adaptif
[Bacaan intensif, metode seleksi tanpa pengawasan yang dapat dibaca, GPT-2] Menuju tuning prompt yang dapat dibaca manusia: Kubrick's the Shining adalah film yang bagus, dan prompt yang bagus juga
【Tes dataset prontoqa kemampuan inferensi cot dan menemukan bahwa kemampuan perencanaan masih terbatas】 model bahasa dapat (jenis) alasan: analisis formal sistematis rantai-pemikiran
【Dataset Penalaran】 WikiWhy: Menjawab dan menjelaskan pertanyaan sebab dan efek
【Dataset Penalaran】 Jalan: Benchmark Penalaran dan Penjelasan Struktur Multi-Tugas
【Dataset Penalaran, Membandingkan OPT pra-pelatihan dan penyempurnaan, termasuk model fine-tuning COT】 Peringatan: mengadaptasi model bahasa dengan tugas penalaran
[Ringkasan Penalaran Terbaru oleh Tim Zhang Ningyu dari Universitas Zhejiang] Penalaran dengan Model Bahasa yang Didorong: Survei
[Ringkasan Teknologi dan Arah Generasi Teks oleh Tim Xiao Yanghua di Fudan] Memanfaatkan Pengetahuan dan Penalaran untuk Generasi Bahasa Alami seperti Manusia: Tinjauan Singkat
[Ringkasan Artikel Penalaran Terbaru, Jie Huang dari UIUC] Menuju Penalaran dalam Model Bahasa Besar: Survei
【Ulasan tugas, kumpulan data, dan metode penalaran matematika dan DL】 Survei pembelajaran yang mendalam untuk penalaran matematika
Survei tentang Pemrosesan Bahasa Alami untuk Pemrograman
Dataset Pemodelan Hadiah:
Red-teaming数据集,harmless vs. helpful, RLHF +scale更难被攻击(另一个有效的技术是CoT fine-tuning):
【知识】+【推理】+【生成】
如果对您有帮助,请star支持一下,欢迎Pull Request~
主观整理,时间上主要从ICLR 2023 Rebuttal期间开始的,包括ICLR,ACL,ICML等预印版论文。
不妥之处或者建议请指正! Dongfang Li, [email protected]


