archgw
release 0.1.5 ?
Arch adalah proxy terdistribusi Layer 7 yang cerdas yang dirancang untuk melindungi, mengamati, dan mempersonalisasikan agen AI dengan API Anda.
Direkayasa dengan LLM yang dibangun khusus, Arch menangani tugas-tugas kritis tetapi tidak terdiferensiasi terkait dengan penanganan dan pemrosesan petunjuk, termasuk mendeteksi dan menolak upaya jailbreak, secara cerdas menyebut "backend" API untuk memenuhi permintaan pengguna yang diwakili dalam pengamatan yang diminta, dan menawarkan pemulihan di atas interaksi di antara interaksi, dan mengelola pengamatan.
Arch dibangun di atas (dan oleh kontributor inti) proxy utusan dengan keyakinan bahwa:
Prompt adalah permintaan pengguna yang bernuansa dan buram, yang membutuhkan kemampuan yang sama seperti permintaan HTTP tradisional termasuk penanganan yang aman, perutean cerdas, observabilitas yang kuat, dan integrasi dengan sistem backend (API) untuk personalisasi - semua logika bisnis luar.*
Fitur Inti :
Lompat ke dokumen kami untuk mempelajari bagaimana Anda dapat menggunakan Arch untuk meningkatkan kecepatan, keamanan, dan personalisasi aplikasi Genai Anda.
Penting
Hari ini, fungsi yang memanggil LLM (fungsi arsip) yang dirancang untuk skenario agen dan RAG dihosting secara gratis di wilayah AS-pusat. Untuk menawarkan latensi dan throughput yang konsisten, dan untuk mengelola pengeluaran kami, kami akan mengaktifkan akses ke versi yang dihosting melalui kunci pengembang segera, dan memberi Anda opsi untuk menjalankan LLM secara lokal. Untuk detail lebih lanjut lihat edisi ini #258
Untuk menghubungi kami, silakan bergabung dengan server Discord kami. Kami akan memantau itu secara aktif dan menawarkan dukungan di sana.
Ikuti panduan ini untuk mempelajari cara dengan cepat mengatur Arch dan mengintegrasikannya ke dalam aplikasi AI generatif Anda.
Sebelum Anda mulai, pastikan Anda memiliki yang berikut:
Docker & Python diinstal pada sistem AndaAPI Keys untuk penyedia LLM (jika menggunakan LLM eksternal)Arch's CLI memungkinkan Anda untuk mengelola dan berinteraksi dengan Gateway Arch secara efisien. Untuk menginstal CLI, cukup jalankan perintah berikut: Kiat: Kami menyarankan agar pengembang membuat lingkungan virtual Python baru untuk mengisolasi dependensi sebelum memasang lengkung. Ini memastikan bahwa ArchGW dan ketergantungannya tidak mengganggu paket lain pada sistem Anda.
Pastikan Anda memiliki utilitas berikut yang diinstal sebelum melanjutkan lebih lanjut,
$ python -m venv venv
$ source venv/bin/activate # On Windows, use: venvScriptsactivate
$ pip install archgwArch beroperasi berdasarkan file konfigurasi di mana Anda dapat mendefinisikan penyedia LLM, target prompt, pagar pembatas, dll. Di bawah ini adalah contoh konfigurasi untuk memulai:
version : v0.1
listener :
address : 127.0.0.1
port : 8080 # If you configure port 443, you'll need to update the listener with tls_certificates
message_format : huggingface
# Centralized way to manage LLMs, manage keys, retry logic, failover and limits in a central way
llm_providers :
- name : OpenAI
provider : openai
access_key : $OPENAI_API_KEY
model : gpt-3.5-turbo
default : true
# default system prompt used by all prompt targets
system_prompt : |
You are a network assistant that helps operators with a better understanding of network traffic flow and perform actions on networking operations. No advice on manufacturers or purchasing decisions.
prompt_targets :
- name : device_summary
description : Retrieve network statistics for specific devices within a time range
endpoint :
name : app_server
path : /agent/device_summary
parameters :
- name : device_ids
type : list
description : A list of device identifiers (IDs) to retrieve statistics for.
required : true # device_ids are required to get device statistics
- name : days
type : int
description : The number of days for which to gather device statistics.
default : " 7 "
- name : reboot_devices
description : Reboot a list of devices
endpoint :
name : app_server
path : /agent/device_reboot
parameters :
- name : device_ids
type : list
description : A list of device identifiers (IDs).
required : true
- name : days
type : int
description : A list of device identifiers (IDs)
default : " 7 "
# Arch creates a round-robin load balancing between different endpoints, managed via the cluster subsystem.
endpoints :
app_server :
# value could be ip address or a hostname with port
# this could also be a list of endpoints for load balancing
# for example endpoint: [ ip1:port, ip2:port ]
endpoint : host.docker.internal:18083
# max time to wait for a connection to be established
connect_timeout : 0.005sLakukan panggilan keluar melalui lengkungan
from openai import OpenAI
# Use the OpenAI client as usual
client = OpenAI (
# No need to set a specific openai.api_key since it's configured in Arch's gateway
api_key = '--' ,
# Set the OpenAI API base URL to the Arch gateway endpoint
base_url = "http://127.0.0.1:12000/v1"
)
response = client . chat . completions . create (
# we select model from arch_config file
model = "--" ,
messages = [{ "role" : "user" , "content" : "What is the capital of France?" }],
)
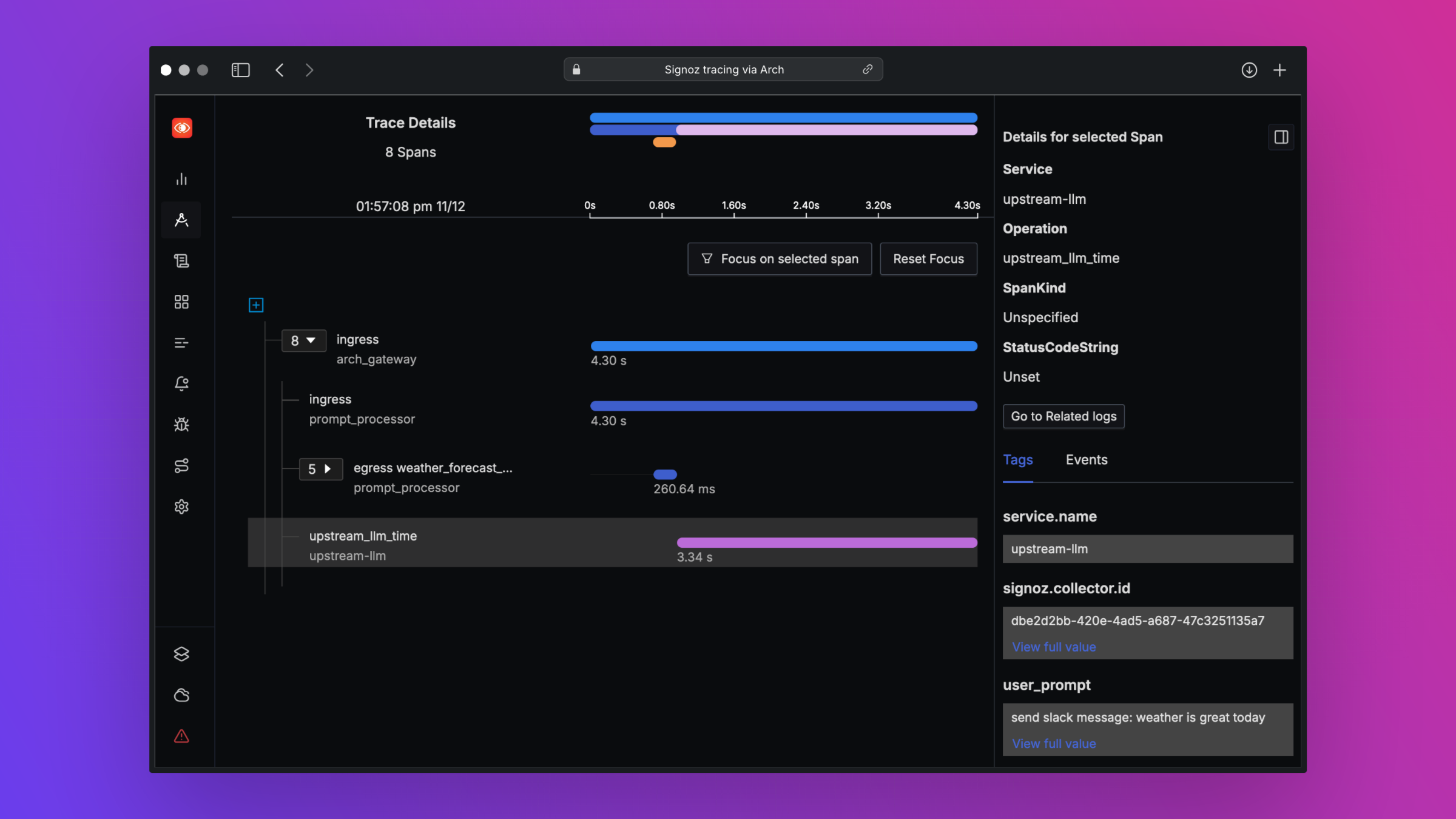
print ( "OpenAI Response:" , response . choices [ 0 ]. message . content )Arch dirancang untuk mendukung observabilitas kelas terbaik dengan mendukung standar terbuka. Harap baca dokumen kami tentang observabilitas untuk detail lebih lanjut tentang penelusuran, metrik, dan log
Kami akan menyukai umpan balik pada peta jalan kami dan kami menyambut kontribusi untuk Arch ! Apakah Anda memperbaiki bug, menambahkan fitur baru, meningkatkan dokumentasi, atau membuat tutorial, bantuan Anda sangat dihargai. Silakan kunjungi panduan kontribusi kami untuk lebih jelasnya


