GPTCache
v0.1.44
Slash LLM API Anda Biaya dengan 10x ?, Boost Speed dengan 100x ⚡
? GptCache telah sepenuhnya terintegrasi dengan? ️? Langchain! Berikut adalah instruksi penggunaan yang terperinci.
? Gambar GptCache Server Docker telah dirilis, yang berarti bahwa bahasa apa pun akan dapat menggunakan GPTCACHE!
? Proyek ini sedang mengalami pengembangan cepat, dan dengan demikian, API dapat berubah kapan saja. Untuk informasi terbaru, silakan merujuk ke dokumentasi terbaru dan catatan rilis.
CATATAN: Karena jumlah model besar tumbuh secara eksplosif dan bentuk API mereka terus berkembang, kami tidak lagi menambahkan dukungan untuk API atau model baru. Kami mendorong penggunaan menggunakan API Get and Set di GptCache, berikut adalah kode demo: https://github.com/zilliztech/gptcache/blob/main/examples/adapter/api.py
pip install gptcache
ChatGPT dan berbagai model bahasa besar (LLM) memiliki keserbagunaan yang luar biasa, memungkinkan pengembangan berbagai aplikasi. Namun, ketika aplikasi Anda semakin populer dan menemukan tingkat lalu lintas yang lebih tinggi, biaya yang terkait dengan panggilan API LLM dapat menjadi substansial. Selain itu, layanan LLM mungkin menunjukkan waktu respons yang lambat, terutama ketika berhadapan dengan sejumlah besar permintaan.
Untuk mengatasi tantangan ini, kami telah membuat GPTCACHE, sebuah proyek yang didedikasikan untuk membangun cache semantik untuk menyimpan tanggapan LLM.
Catatan :
python --versionpython -m pip install --upgrade pip . # clone GPTCache repo
git clone -b dev https://github.com/zilliztech/GPTCache.git
cd GPTCache
# install the repo
pip install -r requirements.txt
python setup.py installContoh -contoh ini akan membantu Anda memahami cara menggunakan pencocokan yang tepat dan serupa dengan caching. Anda juga dapat menjalankan contoh di Colab. Dan lebih banyak contoh Anda dapat merujuk ke bootcamp
Sebelum menjalankan contoh, pastikan variabel lingkungan openai_api_key ditetapkan dengan mengeksekusi echo $OPENAI_API_KEY .
Jika belum diatur, itu dapat diatur dengan menggunakan export OPENAI_API_KEY=YOUR_API_KEY di sistem UNIX/Linux/MacOS atau set OPENAI_API_KEY=YOUR_API_KEY pada sistem Windows.
Penting untuk dicatat bahwa metode ini hanya efektif sementara, jadi jika Anda menginginkan efek permanen, Anda harus memodifikasi file konfigurasi variabel lingkungan. Misalnya, pada Mac, Anda dapat memodifikasi file yang terletak di
/etc/profile.
import os
import time
import openai
def response_text ( openai_resp ):
return openai_resp [ 'choices' ][ 0 ][ 'message' ][ 'content' ]
question = 'what‘s chatgpt'
# OpenAI API original usage
openai . api_key = os . getenv ( "OPENAI_API_KEY" )
start_time = time . time ()
response = openai . ChatCompletion . create (
model = 'gpt-3.5-turbo' ,
messages = [
{
'role' : 'user' ,
'content' : question
}
],
)
print ( f'Question: { question } ' )
print ( "Time consuming: {:.2f}s" . format ( time . time () - start_time ))
print ( f'Answer: { response_text ( response ) } n ' )Jika Anda mengajukan chatgpt dua pertanyaan yang sama persis, jawaban untuk pertanyaan kedua akan diperoleh dari cache tanpa meminta chatgpt lagi.
import time
def response_text ( openai_resp ):
return openai_resp [ 'choices' ][ 0 ][ 'message' ][ 'content' ]
print ( "Cache loading....." )
# To use GPTCache, that's all you need
# -------------------------------------------------
from gptcache import cache
from gptcache . adapter import openai
cache . init ()
cache . set_openai_key ()
# -------------------------------------------------
question = "what's github"
for _ in range ( 2 ):
start_time = time . time ()
response = openai . ChatCompletion . create (
model = 'gpt-3.5-turbo' ,
messages = [
{
'role' : 'user' ,
'content' : question
}
],
)
print ( f'Question: { question } ' )
print ( "Time consuming: {:.2f}s" . format ( time . time () - start_time ))
print ( f'Answer: { response_text ( response ) } n ' )Setelah mendapatkan jawaban dari ChatGPT dalam menanggapi beberapa pertanyaan serupa, jawaban untuk pertanyaan selanjutnya dapat diambil dari cache tanpa perlu meminta chatgpt lagi.
import time
def response_text ( openai_resp ):
return openai_resp [ 'choices' ][ 0 ][ 'message' ][ 'content' ]
from gptcache import cache
from gptcache . adapter import openai
from gptcache . embedding import Onnx
from gptcache . manager import CacheBase , VectorBase , get_data_manager
from gptcache . similarity_evaluation . distance import SearchDistanceEvaluation
print ( "Cache loading....." )
onnx = Onnx ()
data_manager = get_data_manager ( CacheBase ( "sqlite" ), VectorBase ( "faiss" , dimension = onnx . dimension ))
cache . init (
embedding_func = onnx . to_embeddings ,
data_manager = data_manager ,
similarity_evaluation = SearchDistanceEvaluation (),
)
cache . set_openai_key ()
questions = [
"what's github" ,
"can you explain what GitHub is" ,
"can you tell me more about GitHub" ,
"what is the purpose of GitHub"
]
for question in questions :
start_time = time . time ()
response = openai . ChatCompletion . create (
model = 'gpt-3.5-turbo' ,
messages = [
{
'role' : 'user' ,
'content' : question
}
],
)
print ( f'Question: { question } ' )
print ( "Time consuming: {:.2f}s" . format ( time . time () - start_time ))
print ( f'Answer: { response_text ( response ) } n ' )Anda selalu dapat melewati parameter suhu saat meminta layanan atau model API.
Kisaran
temperatureadalah [0, 2], nilai default adalah 0,0.Suhu yang lebih tinggi berarti kemungkinan yang lebih tinggi untuk melewatkan pencarian cache dan meminta model besar secara langsung. Ketika suhu 2, itu akan melewatkan cache dan mengirim permintaan ke model besar secara langsung. Saat suhu 0, ia akan mencari cache sebelum meminta layanan model besar.
post_process_messages_funcdefault adalahtemperature_softmax. Dalam hal ini, lihat referensi API untuk mempelajari tentang bagaimanatemperaturemempengaruhi output.
import time
from gptcache import cache , Config
from gptcache . manager import manager_factory
from gptcache . embedding import Onnx
from gptcache . processor . post import temperature_softmax
from gptcache . similarity_evaluation . distance import SearchDistanceEvaluation
from gptcache . adapter import openai
cache . set_openai_key ()
onnx = Onnx ()
data_manager = manager_factory ( "sqlite,faiss" , vector_params = { "dimension" : onnx . dimension })
cache . init (
embedding_func = onnx . to_embeddings ,
data_manager = data_manager ,
similarity_evaluation = SearchDistanceEvaluation (),
post_process_messages_func = temperature_softmax
)
# cache.config = Config(similarity_threshold=0.2)
question = "what's github"
for _ in range ( 3 ):
start = time . time ()
response = openai . ChatCompletion . create (
model = "gpt-3.5-turbo" ,
temperature = 1.0 , # Change temperature here
messages = [{
"role" : "user" ,
"content" : question
}],
)
print ( "Time elapsed:" , round ( time . time () - start , 3 ))
print ( "Answer:" , response [ "choices" ][ 0 ][ "message" ][ "content" ])Untuk menggunakan GPTCACHE secara eksklusif, hanya baris kode berikut yang diperlukan, dan tidak perlu memodifikasi kode yang ada.
from gptcache import cache
from gptcache . adapter import openai
cache . init ()
cache . set_openai_key ()Lebih banyak dokumen :
GPTCACHE menawarkan manfaat utama berikut:
Layanan online sering menunjukkan lokalitas data, dengan pengguna sering mengakses konten populer atau tren. Sistem cache memanfaatkan perilaku ini dengan menyimpan data yang diakses secara umum, yang pada gilirannya mengurangi waktu pengambilan data, meningkatkan waktu respons, dan meringankan beban pada server backend. Sistem cache tradisional biasanya menggunakan kecocokan yang tepat antara kueri baru dan kueri yang di -cache untuk menentukan apakah konten yang diminta tersedia dalam cache sebelum mengambil data.
Namun, menggunakan pendekatan pencocokan yang tepat untuk cache LLM kurang efektif karena kompleksitas dan variabilitas kueri LLM, menghasilkan laju hit cache rendah. Untuk mengatasi masalah ini, GptCache mengadopsi strategi alternatif seperti caching semantik. Caching semantik mengidentifikasi dan menyimpan kueri yang serupa atau terkait, sehingga meningkatkan probabilitas hit cache dan meningkatkan efisiensi caching secara keseluruhan.
GPTCACHE menggunakan algoritma embedding untuk mengubah kueri menjadi embeddings dan menggunakan toko vektor untuk pencarian kesamaan pada embeddings ini. Proses ini memungkinkan GptCache untuk mengidentifikasi dan mengambil kueri yang serupa atau terkait dari penyimpanan cache, seperti yang diilustrasikan dalam bagian Modul.
Menampilkan desain modular, GPTCACHE memudahkan pengguna untuk menyesuaikan cache semantik mereka sendiri. Sistem ini menawarkan berbagai implementasi untuk setiap modul, dan pengguna bahkan dapat mengembangkan implementasi mereka sendiri agar sesuai dengan kebutuhan spesifik mereka.
Dalam cache semantik, Anda mungkin menghadapi positif palsu selama hit cache dan negatif palsu selama cache gagal. GPTCACHE menawarkan tiga metrik untuk mengukur kinerjanya, yang bermanfaat bagi pengembang untuk mengoptimalkan sistem caching mereka:
Benchmark sampel disertakan untuk pengguna untuk memulai dengan menilai kinerja cache semantik mereka.
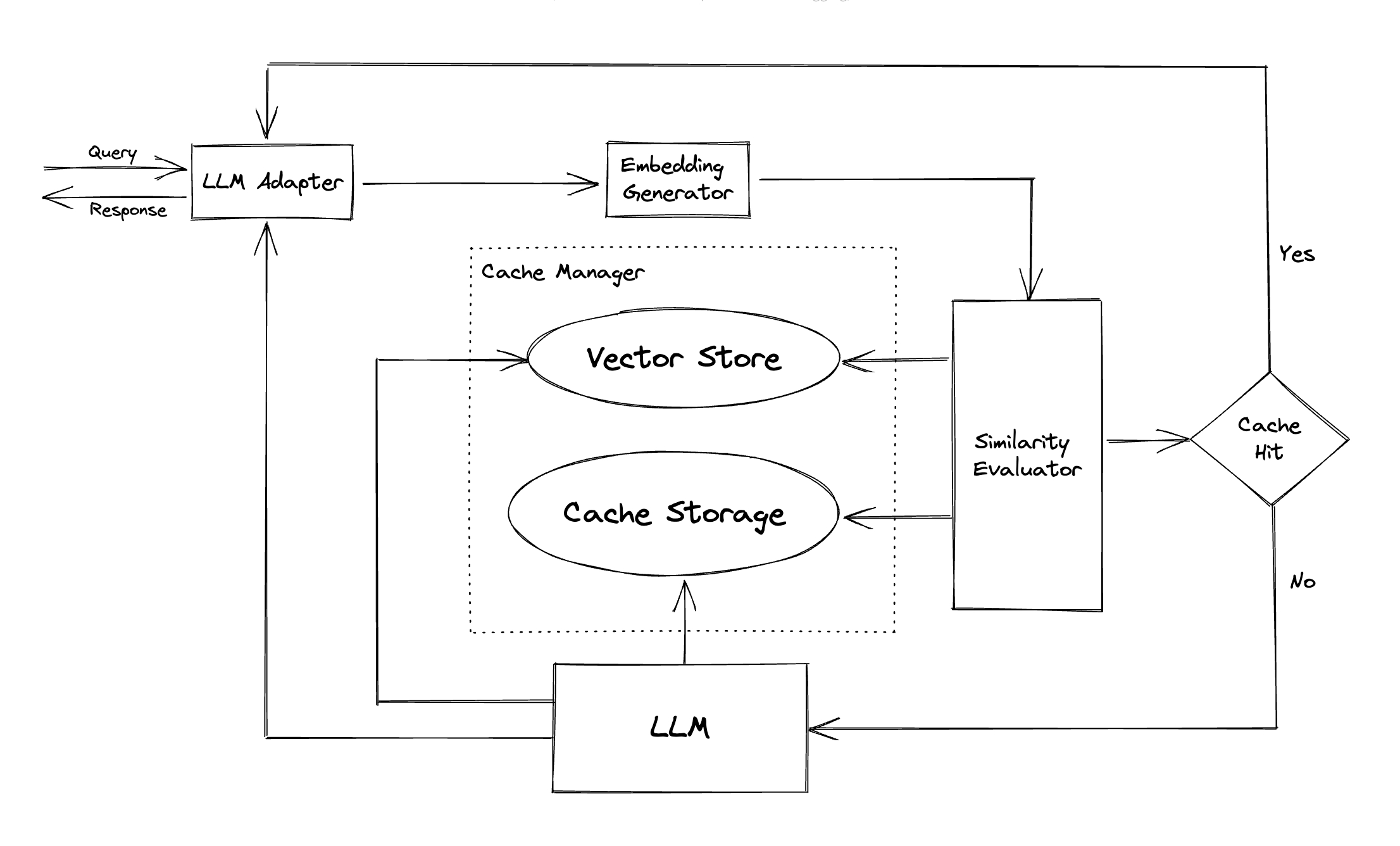
Adaptor LLM : Adaptor LLM dirancang untuk mengintegrasikan model LLM yang berbeda dengan menyatukan API mereka dan meminta protokol. GPTCACHE menawarkan antarmuka standar untuk tujuan ini, dengan dukungan saat ini untuk integrasi chatgpt.
Adaptor Multimodal (Eksperimental) : Adaptor multimodal dirancang untuk mengintegrasikan berbagai model multimodal besar dengan menyatukan API mereka dan meminta protokol. GPTCACHE menawarkan antarmuka standar untuk tujuan ini, dengan dukungan saat ini untuk integrasi pembuatan gambar, transkripsi audio.
Generator Embedding : Modul ini dibuat untuk mengekstrak embeddings dari permintaan pencarian kesamaan. GPTCACHE menawarkan antarmuka generik yang mendukung beberapa API embedding, dan menyajikan berbagai solusi untuk dipilih.
Penyimpanan cache : Penyimpanan cache adalah tempat respons dari LLMS, seperti chatgpt, disimpan. Respons yang di -cache diambil untuk membantu dalam mengevaluasi kesamaan dan dikembalikan ke pemohon jika ada pertandingan semantik yang baik. Saat ini, GptCache mendukung SQLite dan menawarkan antarmuka yang dapat diakses secara universal untuk perluasan modul ini.
Vector Store : Modul Vector Store membantu menemukan permintaan K yang paling mirip dari embedding yang diekstraksi permintaan input. Hasilnya dapat membantu menilai kesamaan. GPTCACHE menyediakan antarmuka yang ramah pengguna yang mendukung berbagai toko vektor, termasuk Milvus, Zilliz Cloud, dan FAISS. Lebih banyak opsi akan tersedia di masa mendatang.
Cache Manager : Manajer cache bertanggung jawab untuk mengendalikan operasi penyimpanan cache dan toko vektor .
cachetools Python atau dengan cara terdistribusi menggunakan Redis sebagai toko nilai kunci.Saat ini, GPTCACHE membuat keputusan tentang penggusuran hanya berdasarkan jumlah baris. Pendekatan ini dapat mengakibatkan evaluasi sumber daya yang tidak akurat dan dapat menyebabkan kesalahan out-of-memory (OOM). Kami secara aktif menyelidiki dan mengembangkan strategi yang lebih canggih.
Jika Anda skala penyebaran GPTCACHE Anda secara horizontal menggunakan caching dalam memori, itu tidak akan mungkin terjadi. Karena informasi yang di -cache akan terbatas pada pod tunggal.
Dengan caching terdistribusi, informasi cache yang konsisten di semua replika yang dapat kami gunakan toko cache terdistribusi seperti Redis.
Evaluator Kesamaan : Modul ini mengumpulkan data dari penyimpanan cache dan penyimpanan vektor , dan menggunakan berbagai strategi untuk menentukan kesamaan antara permintaan input dan permintaan dari toko vektor . Berdasarkan kesamaan ini, ini menentukan apakah suatu permintaan cocok dengan cache. GPTCACHE menyediakan antarmuka standar untuk mengintegrasikan berbagai strategi, bersama dengan kumpulan implementasi untuk digunakan. Definisi kesamaan berikut saat ini didukung atau akan didukung di masa depan:
Catatan : Tidak semua kombinasi modul yang berbeda mungkin kompatibel satu sama lain. Misalnya, jika kita menonaktifkan ekstraktor embedding , toko vektor mungkin tidak berfungsi sebagaimana dimaksud. Kami saat ini sedang berupaya menerapkan pemeriksaan kewarasan kombinasi untuk GPTCACHE .
Segera hadir! Pantau terus!
Kami sangat terbuka untuk kontribusi, baik melalui fitur baru, peningkatan infrastruktur, atau dokumentasi yang lebih baik.
Untuk instruksi komprehensif tentang cara berkontribusi, silakan merujuk ke panduan kontribusi kami.


