Deep RL Keras
1.0.0
Implementasi modular algoritma pembelajaran penguatan mendalam populer di KERAS:
Implementasi ini membutuhkan keras 2.1.6, serta gym openai.
$ pip install gym keras==2.1.6Algoritma aktor-kritik adalah metode yang bebas model, di luar kebijakan di mana kritikus bertindak sebagai perkiraan nilai-fungsi, dan aktor sebagai perkiraan fungsi kebijakan. Saat berlatih, kritikus memprediksi TD-error dan memandu pembelajaran baik itu sendiri dan aktor. Dalam praktiknya, kami memperkirakan TD-error menggunakan fungsi Advantage. Untuk stabilitas yang lebih, kami menggunakan tulang punggung komputasi bersama di kedua jaringan, serta formulasi N-langkah dari imbalan diskon. Kami juga memasukkan istilah regularisasi entropi (pembelajaran "lunak") untuk mendorong eksplorasi. Sementara A2C sederhana dan efisien, menjalankannya pada game Atari dengan cepat menjadi tidak dapat dipecahkan karena waktu perhitungan yang lama.
Dengan cara yang sama dengan algoritma A2C, implementasi A3C menggabungkan pembaruan berat badan asinkron, memungkinkan untuk perhitungan yang lebih cepat. Kami menggunakan banyak agen untuk melakukan pendakian gradien secara asinkron, melalui beberapa utas. Kami menguji A3C di lingkungan pelarian Atari.
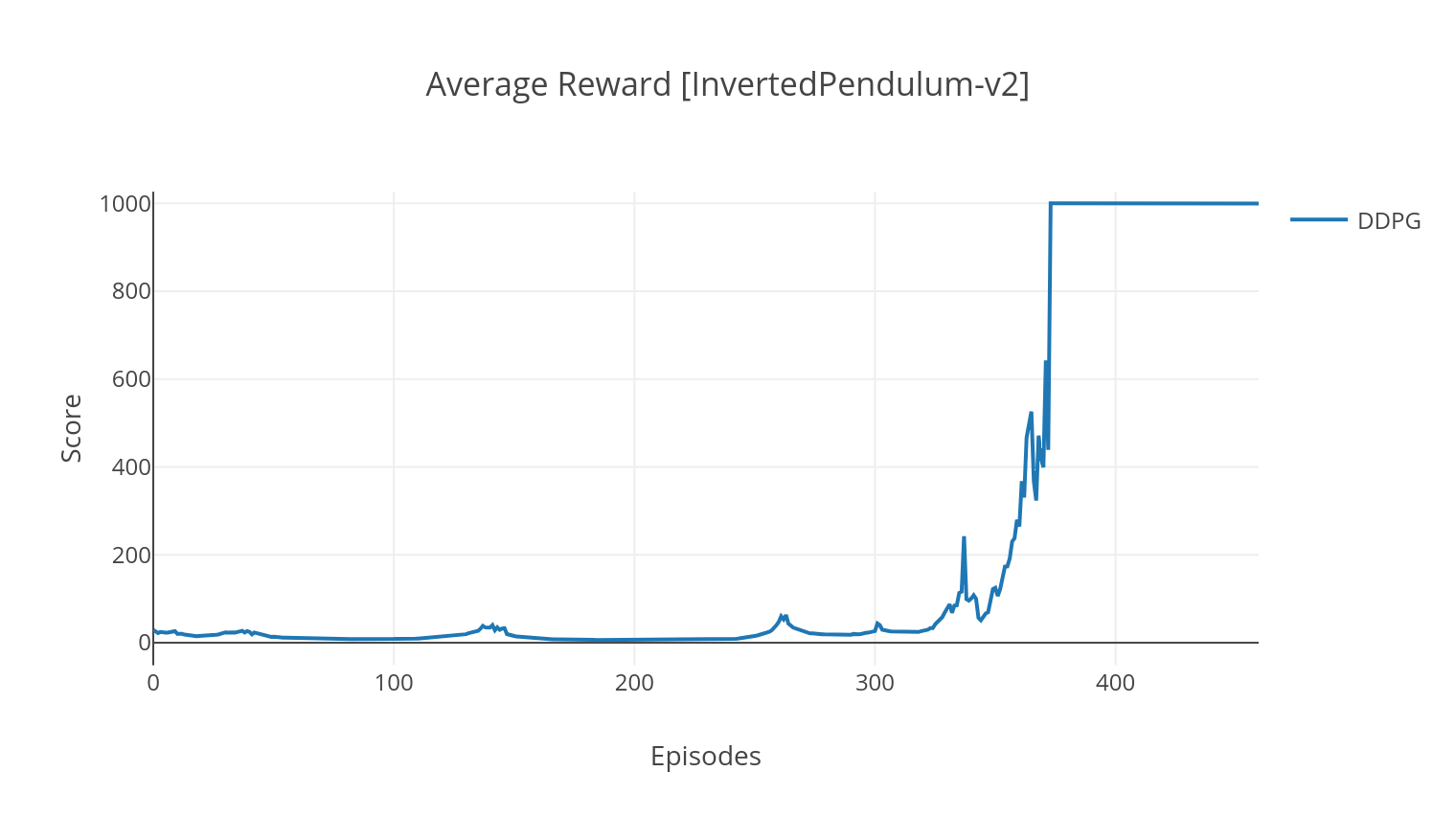
Algoritma DDPG adalah algoritma yang bebas model, di luar kebijakan untuk ruang aksi kontinu. Demikian pula dengan A2C, ini adalah algoritma aktor-kritik di mana aktor dilatih pada kebijakan target deterministik, dan kritikus memprediksi nilai-Q. Untuk mengurangi varians dan meningkatkan stabilitas, kami menggunakan replay pengalaman dan memisahkan jaringan target. Selain itu, seperti yang diisyaratkan oleh Openai, kami mendorong eksplorasi melalui kebisingan ruang parameter (sebagai lawan dari kebisingan ruang aksi tradisional). Kami menguji DDPG di lingkungan Lunar Lander.
$ python3 main.py --type A2C --env CartPole-v1
$ python3 main.py --type A3C --env CartPole-v1 --nb_episodes 10000 --n_threads 16
$ python3 main.py --type A3C --env BreakoutNoFrameskip-v4 --is_atari --nb_episodes 10000 --n_threads 16
$ python3 main.py --type DDPG --env LunarLanderContinuous-v2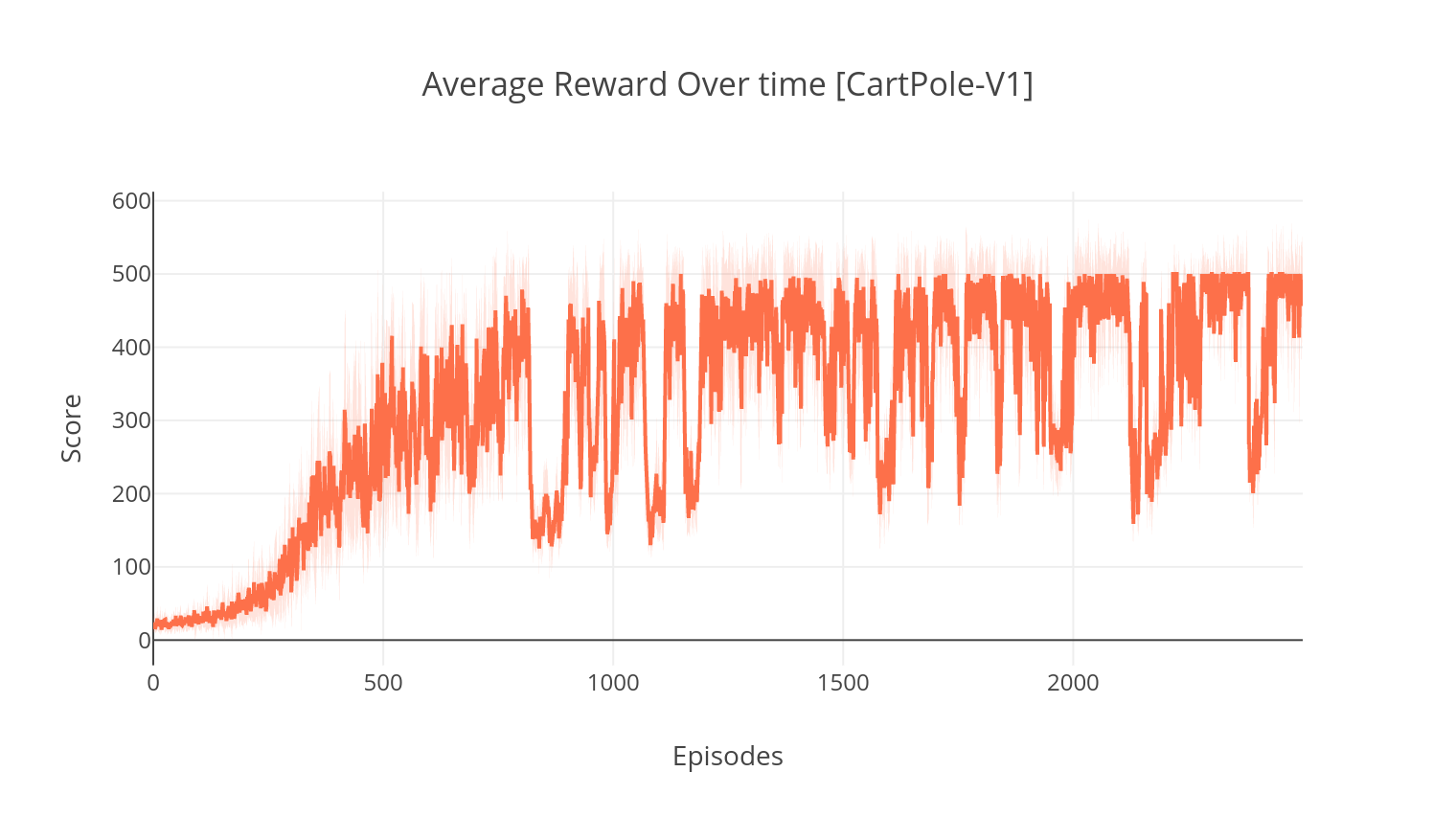
Algoritma DQN adalah algoritma q-learning, yang menggunakan jaringan saraf yang dalam sebagai perkiraan fungsi nilai-Q. Kami memperkirakan target nilai-Q dengan memanfaatkan persamaan Bellman, dan mengumpulkan pengalaman melalui kebijakan Epsilon-Greedy. Untuk stabilitas yang lebih, kami mencicipi pengalaman masa lalu secara acak (pengalaman replay). Varian dari algoritma DQN adalah DQN double-dqn (atau DDQN). Untuk estimasi nilai-Q kami yang lebih akurat, kami menggunakan jaringan kedua untuk meredam perkiraan nilai-Q oleh jaringan asli. Jaringan target ini diperbarui pada tingkat yang lebih lambat, pada setiap langkah pelatihan.
Kami dapat lebih meningkatkan algoritma DDQN kami dengan menambahkan dalam Prioritas Pengalaman Replay (Per), yang bertujuan melakukan pengambilan sampel penting pada pengalaman yang dikumpulkan. Pengalaman ini diperingkat oleh TD-error-nya, dan disimpan dalam struktur Sumtree, yang memungkinkan pengambilan transisi (S, A, R, S ') yang efisien dengan kesalahan tertinggi.
Dalam varian duel DQN, kami menggabungkan lapisan perantara dalam Q-Network untuk memperkirakan nilai negara dan fungsi keuntungan yang bergantung pada negara. Setelah reformulasi (lihat REF), ternyata kita dapat mengekspresikan estimasi nilai-Q sebagai nilai negara, di mana kita menambahkan estimasi keuntungan dan mengurangi rata-rata. Faktorisasi nilai-nilai yang tidak tergantung pada negara dan bergantung pada negara ini membantu menguraikan pembelajaran di seluruh tindakan dan menghasilkan hasil yang lebih baik.
$ python3 main.py --type DDQN --env CartPole-v1 --batch_size 64
$ python3 main.py --type DDQN --env CartPole-v1 --batch_size 64 --with_PER
$ python3 main.py --type DDQN --env CartPole-v1 --batch_size 64 --dueling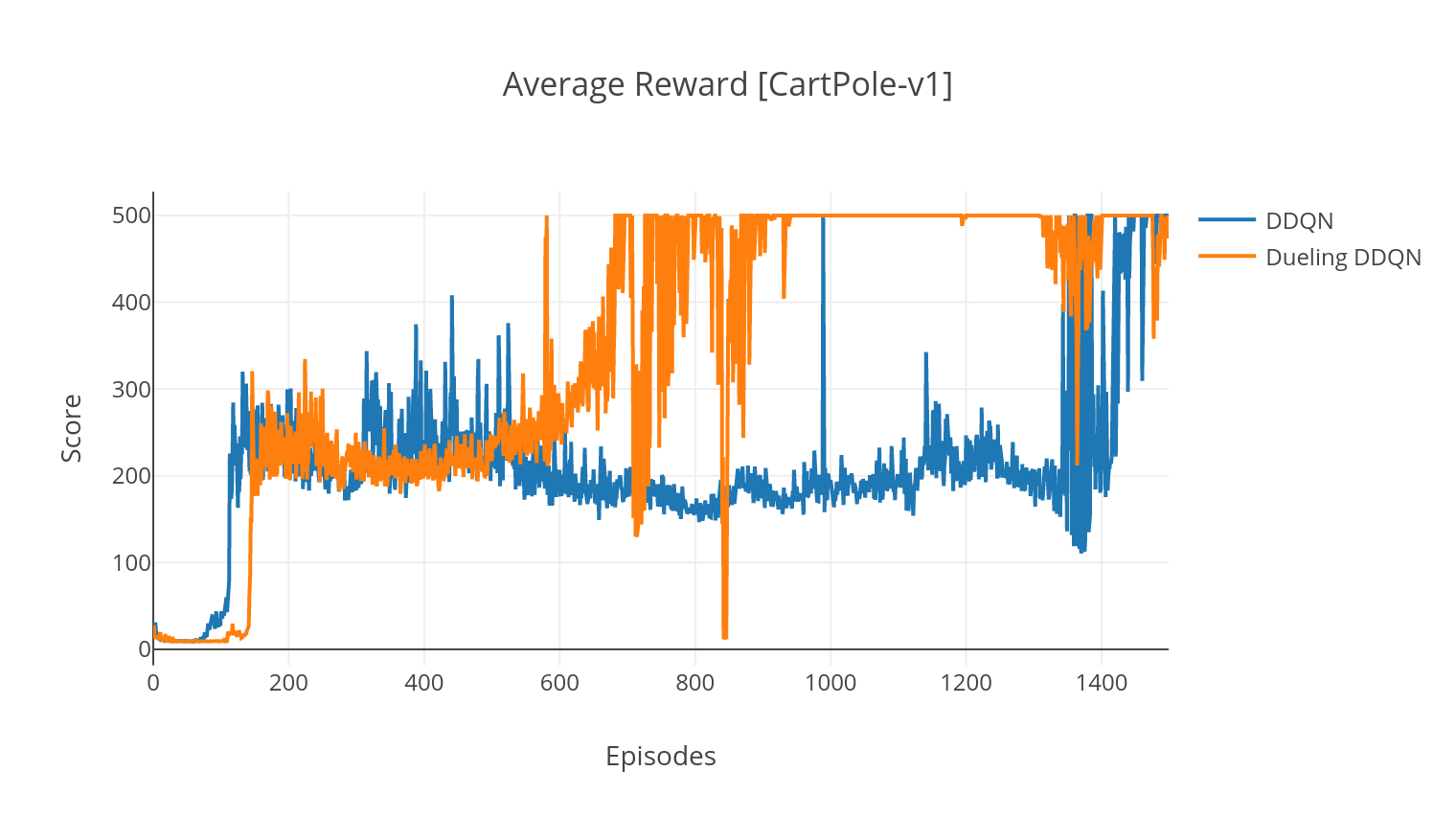
| Argumen | Keterangan | Nilai |
|---|---|---|
| --jenis | Jenis algoritma RL untuk dijalankan | Pilih dari {A2C, A3C, DDQN, DDPG} |
| --env | Tentukan lingkungan | Breakoutnoframeskip-V4 (default) |
| --nb_episodes | Jumlah episode yang harus dijalankan | 5000 (default) |
| --Bot_Size | Ukuran Batch (DDQN, DDPG) | 32 (default) |
| --Conecutive_frames | Jumlah bingkai berturut -turut | 4 (default) |
| --is_atari | Apakah lingkungan adalah permainan atari dengan input piksel | - |
| --with_per | Apakah akan menggunakan replay pengalaman prioritas (dengan ddqn) | - |
| -Dueling | Apakah akan menggunakan jaringan duel (dengan ddqn) | - |
| --N_Threads | Jumlah utas (A3C) | 16 (default) |
| --gather_stats | Apakah akan menghitung statistik skor rata -rata lebih dari 10 pertandingan (lambat, lihat di bawah) | - |
| --memberikan | Apakah akan membuat lingkungan seperti pelatihan | - |
| --gpu | Indeks GPU | 0 |
Semua model disimpan di bawah <algorithm_folder>/models/ saat pelatihan selesai. Anda dapat memvisualisasikan mereka berjalan di lingkungan yang sama dengan mereka dilatih dengan menjalankan skrip load_and_run.py . Untuk model DQN, Anda harus menentukan jalur ke model yang diinginkan dalam argumen --model_path . Untuk model aktor-kritik, Anda perlu menentukan kedua file berat dalam argumen --actor_path dan --critic_path .
Menggunakan Tensorboard, Anda dapat memantau skor agen saat pelatihan. Saat berlatih, folder log dengan nama yang cocok dengan lingkungan yang dipilih akan dibuat. Misalnya, untuk mengikuti perkembangan A2C di Cartpole-V1, cukup jalankan:
$ tensorboard --logdir=A2C/tensorboard_CartPole-v1/ Saat berlatih dengan argumen --gather_stats , file log dihasilkan berisi skor rata -rata lebih dari 10 pertandingan di setiap episode: logs.csv . Menggunakan Plotly, Anda dapat memvisualisasikan hadiah rata -rata per episode. Untuk melakukannya, pertama -tama Anda harus menginstal secara plot dan mendapatkan lisensi gratis.
pip3 install plotlyUntuk mengatur kredensial Anda, jalankan:
import plotly
plotly . tools . set_credentials_file ( username = '<your_username>' , api_key = '<your_key>' )Akhirnya, untuk merencanakan hasilnya, jalankan:
python3 utils/plot_results.py < path_to_your_log_file >

