lang2sql
1.0.0
Repo ini menyediakan panduan langkah demi langkah dan templat untuk menyiapkan bahasa alami ke generator kode SQL dengan OPNEAI API.
Tutorial ini juga tersedia di Medium.
Pembaruan Terakhir: 7 Jan, 2024
Perkembangan cepat model bahasa alami, terutama model bahasa besar (LLM), telah menyajikan banyak kemungkinan untuk berbagai bidang. Salah satu aplikasi yang paling umum adalah menggunakan LLMS untuk pengkodean. Misalnya, Openai's Chatgpt dan Meta's Code Llama adalah LLMS yang menawarkan bahasa alami canggih kepada generator kode. Salah satu kasus penggunaan potensial adalah bahasa alami untuk generator kode SQL, yang dapat membantu para profesional non-teknis dengan permintaan data sederhana dan mudah-mudahan memungkinkan tim data untuk fokus pada tugas yang lebih intensif data. Tutorial ini berfokus pada pengaturan bahasa untuk generator kode SQL menggunakan API OpenAI.
Salah satu aplikasi yang mungkin adalah chatbot yang dapat menanggapi kueri pengguna dengan data yang relevan (Gambar 1). Chatbot dapat diintegrasikan dengan saluran Slack menggunakan aplikasi Python yang melakukan langkah -langkah berikut:
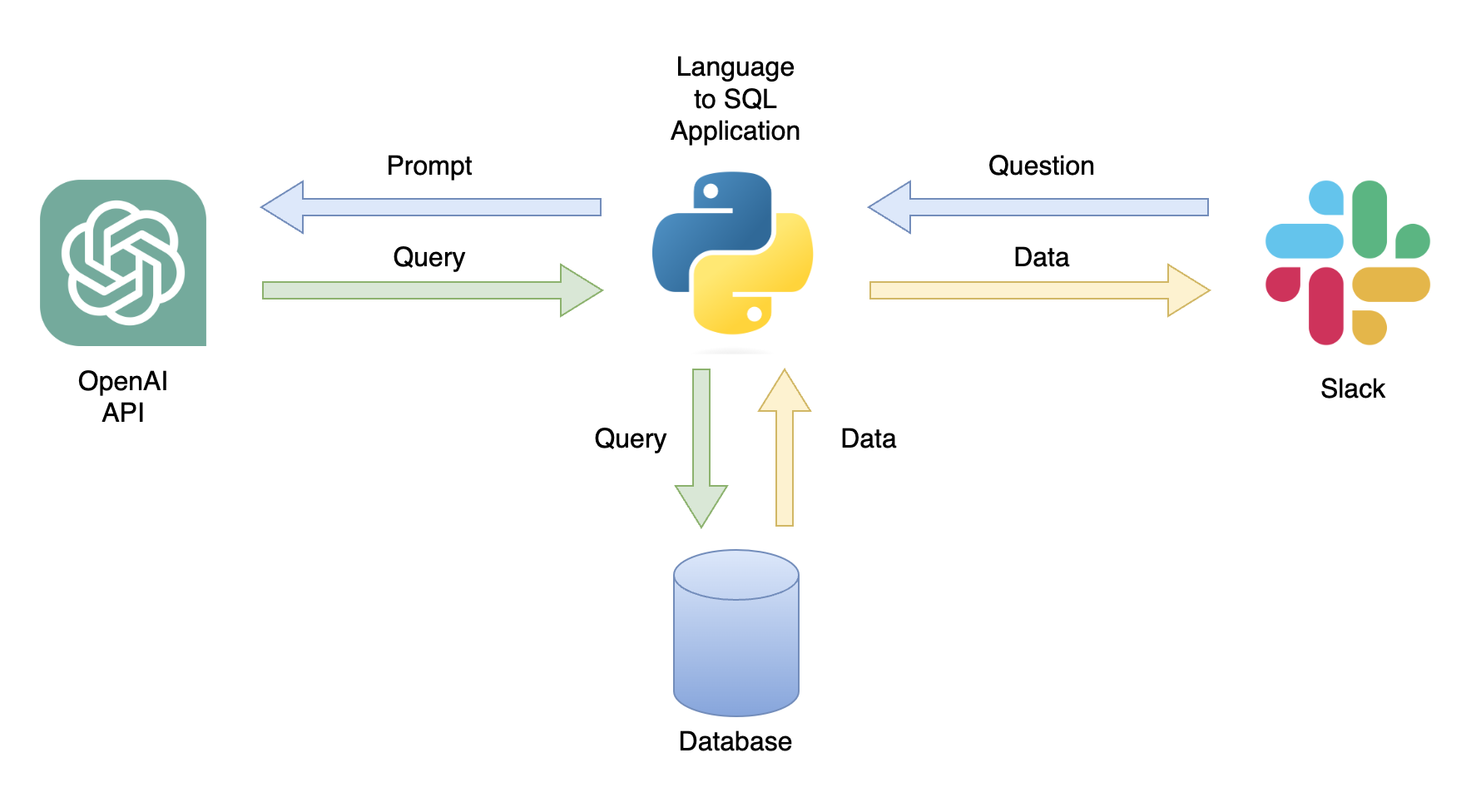
In this tutorial, we will build a step-by-step Python application that converts user questions into SQL queries.
Tutorial ini memberikan panduan langkah demi langkah tentang cara mengatur aplikasi Python yang mengubah pertanyaan umum menjadi kueri SQL menggunakan API OpenAI. Itu termasuk fungsionalitas berikut:
Gambar 2 di bawah ini menjelaskan arsitektur umum bahasa sederhana untuk generator kode SQL.
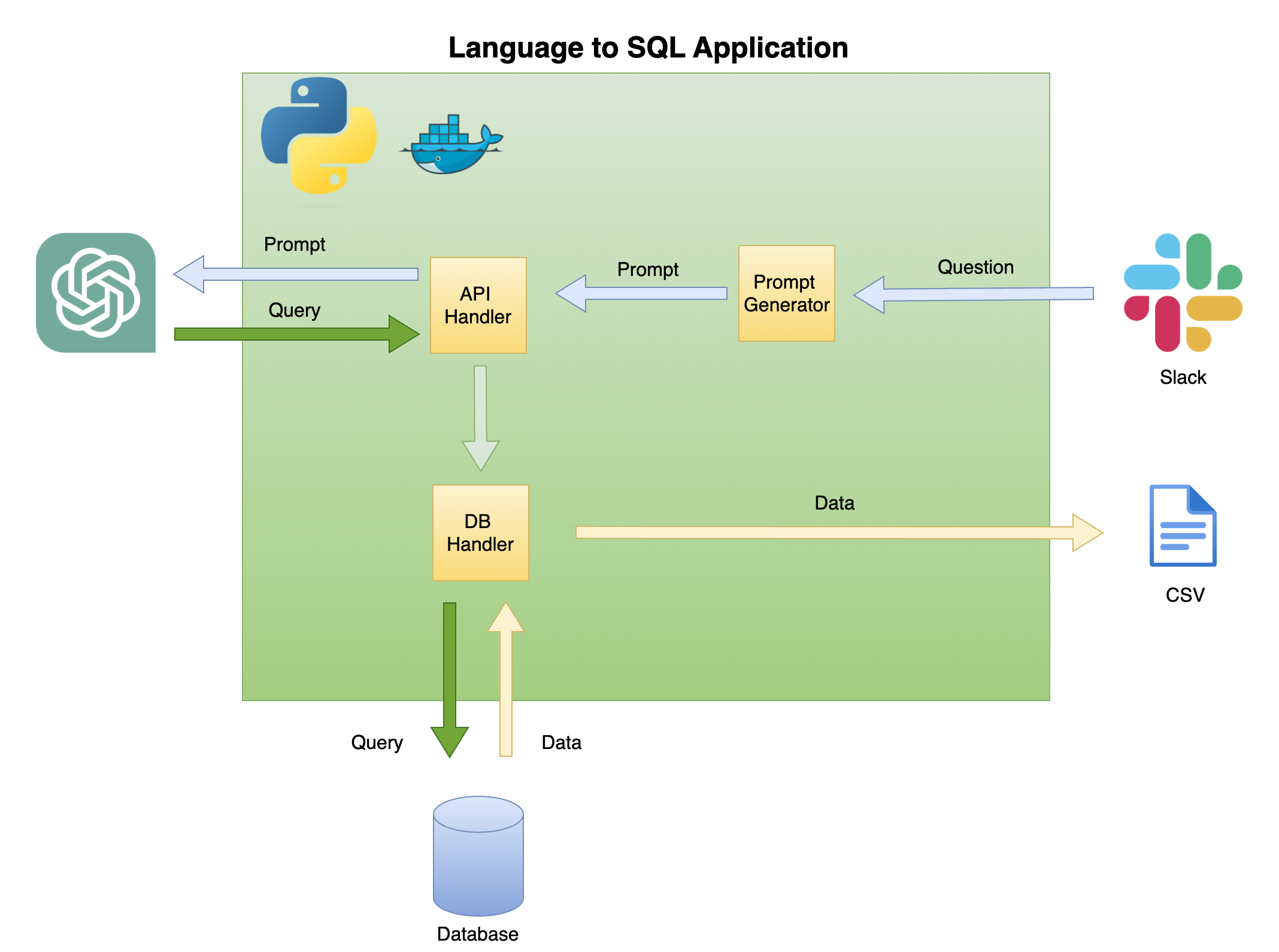
Lingkup dan fokus tutorial ini ada di kotak hijau - membangun fungsionalitas berikut:
Pertanyaan untuk meminta - mengubah pertanyaan menjadi format prompt:
API Handler - Fungsi yang berfungsi dengan API Openai:
DB Handler - Fungsi yang mengirimkan kueri SQL ke database dan mengembalikan data yang diperlukan
Prasyarat utama untuk tutorial ini adalah pengetahuan dasar Python. Itu termasuk fungsionalitas berikut:
Selain itu, pengetahuan dasar SQL dan akses ke API OpenAI diperlukan.
Meskipun tidak perlu, memiliki pengetahuan dasar tentang Docker sangat membantu, karena tutorial dibuat di lingkungan Dockerized menggunakan ekstensi wadah dev vscode. Jika Anda tidak memiliki pengalaman dengan Docker atau ekstensi, Anda masih dapat menjalankan tutorial dengan membuat lingkungan virtual dan menginstal pustaka yang diperlukan (seperti yang dijelaskan di bawah). Pengetahuan tentang rekayasa cepat dan API Openai juga bermanfaat.
Saya membuat tutorial terperinci tentang pengaturan lingkungan Python Dockerized dengan vScode dan ekstensi wadah dev:
https://github.com/ramikrispin/vscode-python
Untuk mengatur bahasa alami untuk pembuatan kode SQL, kami akan menggunakan pustaka Python berikut:
pandas - untuk memproses data di seluruh prosesduckdb - untuk mensimulasikan pekerjaan dengan databaseopenai - untuk bekerja dengan API openaitime dan os - Untuk memuat file CSV dan memformat bidangRepositori ini berisi pengaturan yang diperlukan untuk meluncurkan lingkungan berlabuh dengan persyaratan tutorial di vScode dan ekstensi wadah dev. Rincian lebih lanjut tersedia di bagian berikutnya.
Atau, Anda dapat mengatur lingkungan virtual dan menginstal persyaratan tutorial dengan mengikuti instruksi di bawah ini menggunakan instruksi di bagian Lingkungan Virtual.
Tutorial ini dibangun di dalam lingkungan berlabuh dengan vScode dan ekstensi wadah dev. Untuk menjalankannya dengan vScode, Anda harus menginstal ekstensi wadah dev dan membuka Docker Desktop (atau setara). Pengaturan lingkungan tersedia di bawah folder .devcontainer :
.── .devcontainer
├── Dockerfile
├── Dockerfile.dev
├── devcontainer.json
├── install_dependencies_core.sh
├── install_dependencies_other.sh
├── install_quarto.sh
├── requirements_core.txt
├── requirements_openai.txt
└── requirements_transformers.txt
devcontainer.json memiliki instruksi build dan pengaturan vscode untuk lingkungan berlabuh ini:
{
"name" : " lang2sql " ,
"build" : {
"dockerfile" : " Dockerfile " ,
"args" : {
"ENV_NAME" : " lang2sql " ,
"PYTHON_VER" : " 3.10 " ,
"METHOD" : " openai " ,
"QUARTO_VER" : " 1.3.450 "
},
"context" : " . "
},
"customizations" : {
"settings" : {
"python.defaultInterpreterPath" : " /opt/conda/envs/lang2sql/bin/python " ,
"python.selectInterpreter" : " /opt/conda/envs/lang2sql/bin/python "
},
"vscode" : {
"extensions" : [
" quarto.quarto " ,
" ms-azuretools.vscode-docker " ,
" ms-python.python " ,
" ms-vscode-remote.remote-containers " ,
" yzhang.markdown-all-in-one " ,
" redhat.vscode-yaml " ,
" ms-toolsai.jupyter "
]
}
},
"remoteEnv" : {
"OPENAI_KEY" : " ${localEnv:OPENAI_KEY} "
}
}
Di mana argumen build mendefinisikan metode docker build dan menetapkan argumen untuk build. Dalam hal ini, kami mengatur versi Python ke 3.10 , dan lingkungan virtual Conda ke ang2sql . Argumen METHOD mendefinisikan jenis lingkungan - baik openai untuk menginstal pustaka persyaratan untuk tutorial ini menggunakan API OpenAI atau transformers untuk mengatur lingkungan untuk API HuggingFaces (yang berada di luar ruang lingkup tutorial ini).
Argumen remoteEnv memungkinkan pengaturan variabel lingkungan. Kami akan menggunakannya untuk mengatur kunci API OpenAI. Dalam hal ini, saya mengatur variabel secara lokal sebagai OPENAI_KEY , dan saya memuatnya menggunakan argumen localEnv .
Jika Anda ingin mempelajari lebih lanjut tentang menyiapkan lingkungan pengembangan Python dengan VScode dan Docker, periksa tutorial ini.
Jika Anda tidak menggunakan lingkungan tutorial berlabuh, Anda dapat membuat lingkungan virtual lokal dari baris perintah menggunakan skrip di bawah ini:
ENV_NAME=openai_api
PYTHON_VER=3.10
conda create -y --name $ENV_NAME python= $PYTHON_VER
conda activate $ENV_NAME
pip3 install -r ./.devcontainer/requirements_core.txt
pip3 install -r ./.devcontainer/requirements_openai.txt
Catatan: Saya menggunakan conda dan itu harus bekerja dengan baik dengan metode lingkungan virutal lainnya.
Kami menggunakan variabel ENV_NAME dan PYTHON_VER untuk mengatur lingkungan virtual dan versi Python.
Untuk mengonfirmasi bahwa lingkungan Anda diatur dengan benar, gunakan conda list untuk mengonfirmasi bahwa pustaka Python yang diperlukan diinstal. Anda harus mengharapkan output di bawah ini:
(openai_api) root@0ca5b8000cd5:/workspaces/lang2sql# conda list
# packages in environment at /opt/conda/envs/openai_api:
#
# Name Version Build Channel
_libgcc_mutex 0.1 main
_openmp_mutex 5.1 51_gnu
aiohttp 3.9.0 pypi_0 pypi
aiosignal 1.3.1 pypi_0 pypi
asttokens 2.4.1 pypi_0 pypi
async-timeout 4.0.3 pypi_0 pypi
attrs 23.1.0 pypi_0 pypi
bzip2 1.0.8 hfd63f10_2
ca-certificates 2023.08.22 hd43f75c_0
certifi 2023.11.17 pypi_0 pypi
charset-normalizer 3.3.2 pypi_0 pypi
comm 0.2.0 pypi_0 pypi
contourpy 1.2.0 pypi_0 pypi
cycler 0.12.1 pypi_0 pypi
debugpy 1.8.0 pypi_0 pypi
decorator 5.1.1 pypi_0 pypi
duckdb 0.9.2 pypi_0 pypi
exceptiongroup 1.2.0 pypi_0 pypi
executing 2.0.1 pypi_0 pypi
fonttools 4.45.1 pypi_0 pypi
frozenlist 1.4.0 pypi_0 pypi
gensim 4.3.2 pypi_0 pypi
idna 3.5 pypi_0 pypi
ipykernel 6.26.0 pypi_0 pypi
ipython 8.18.0 pypi_0 pypi
jedi 0.19.1 pypi_0 pypi
joblib 1.3.2 pypi_0 pypi
jupyter-client 8.6.0 pypi_0 pypi
jupyter-core 5.5.0 pypi_0 pypi
kiwisolver 1.4.5 pypi_0 pypi
ld_impl_linux-aarch64 2.38 h8131f2d_1
libffi 3.4.4 h419075a_0
libgcc-ng 11.2.0 h1234567_1
libgomp 11.2.0 h1234567_1
libstdcxx-ng 11.2.0 h1234567_1
libuuid 1.41.5 h998d150_0
matplotlib 3.8.2 pypi_0 pypi
matplotlib-inline 0.1.6 pypi_0 pypi
multidict 6.0.4 pypi_0 pypi
ncurses 6.4 h419075a_0
nest-asyncio 1.5.8 pypi_0 pypi
numpy 1.26.2 pypi_0 pypi
openai 0.28.1 pypi_0 pypi
openssl 3.0.12 h2f4d8fa_0
packaging 23.2 pypi_0 pypi
pandas 2.0.0 pypi_0 pypi
parso 0.8.3 pypi_0 pypi
pexpect 4.8.0 pypi_0 pypi
pillow 10.1.0 pypi_0 pypi
pip 23.3.1 py310hd43f75c_0
platformdirs 4.0.0 pypi_0 pypi
prompt-toolkit 3.0.41 pypi_0 pypi
psutil 5.9.6 pypi_0 pypi
ptyprocess 0.7.0 pypi_0 pypi
pure-eval 0.2.2 pypi_0 pypi
pygments 2.17.2 pypi_0 pypi
pyparsing 3.1.1 pypi_0 pypi
python 3.10.13 h4bb2201_0
python-dateutil 2.8.2 pypi_0 pypi
pytz 2023.3.post1 pypi_0 pypi
pyzmq 25.1.1 pypi_0 pypi
readline 8.2 h998d150_0
requests 2.31.0 pypi_0 pypi
scikit-learn 1.3.2 pypi_0 pypi
scipy 1.11.4 pypi_0 pypi
setuptools 68.0.0 py310hd43f75c_0
six 1.16.0 pypi_0 pypi
smart-open 6.4.0 pypi_0 pypi
sqlite 3.41.2 h998d150_0
stack-data 0.6.3 pypi_0 pypi
threadpoolctl 3.2.0 pypi_0 pypi
tk 8.6.12 h241ca14_0
tornado 6.3.3 pypi_0 pypi
tqdm 4.66.1 pypi_0 pypi
traitlets 5.13.0 pypi_0 pypi
tzdata 2023.3 pypi_0 pypi
urllib3 2.1.0 pypi_0 pypi
wcwidth 0.2.12 pypi_0 pypi
wheel 0.41.2 py310hd43f75c_0
xz 5.4.2 h998d150_0
yarl 1.9.3 pypi_0 pypi
zlib 1.2.13 h998d150_0
Kami akan menggunakan API OpenAI untuk mengakses ChatGPT menggunakan mesin Text-Davinci-003. Ini membutuhkan akun OpenAI aktif dan kunci API. Sangat mudah untuk mengatur akun dan kunci API mengikuti instruksi di tautan di bawah ini:
https://openai.com/product
Setelah Anda mengatur akses ke API dan kunci, saya sarankan menambahkan kunci sebagai variabel lingkungan ke file .zshrc Anda (atau format lain yang Anda gunakan untuk menyimpan variabel lingkungan pada sistem shell Anda). Saya menyimpan kunci API saya di bawah variabel lingkungan OPENAI_KEY . Untuk alasan yang meyakinkan, saya sarankan Anda menggunakan konvensi penamaan yang sama.
Untuk mengatur variabel pada file .zshrc (atau setara), tambahkan baris di bawah ini ke file:
export OPENAI_KEY= " YOUR_API_KEY " Jika menggunakan vscode atau berjalan dari terminal, Anda harus memulai kembali sesi Anda setelah menambahkan variabel ke file .zshrc .
Untuk mensimulasikan fungsi database, kami akan memanfaatkan dataset kejahatan Chicago. Dataset ini memberikan informasi mendalam mengenai kejahatan yang dicatat di kota Chicago sejak tahun 2001. Dengan hampir 8 juta catatan dan 22 kolom, dataset mencakup informasi seperti klasifikasi kejahatan, lokasi, waktu, hasil, dll. Data tersedia untuk diunduh dari portal data Chicago. Karena kami menyimpan data secara lokal sebagai bingkai data panda dan menggunakan DuckDB untuk mensimulasikan kueri SQL, kami akan mengunduh subset data menggunakan tiga tahun terakhir.
Anda dapat menarik data dari API atau mengunduh file CSV. Untuk menghindari memanggil API setiap kali saya menjalankan skrip, saya mengunduh file dan menyimpannya di bawah folder data. Di bawah ini adalah tautan ke set data berdasarkan tahun:
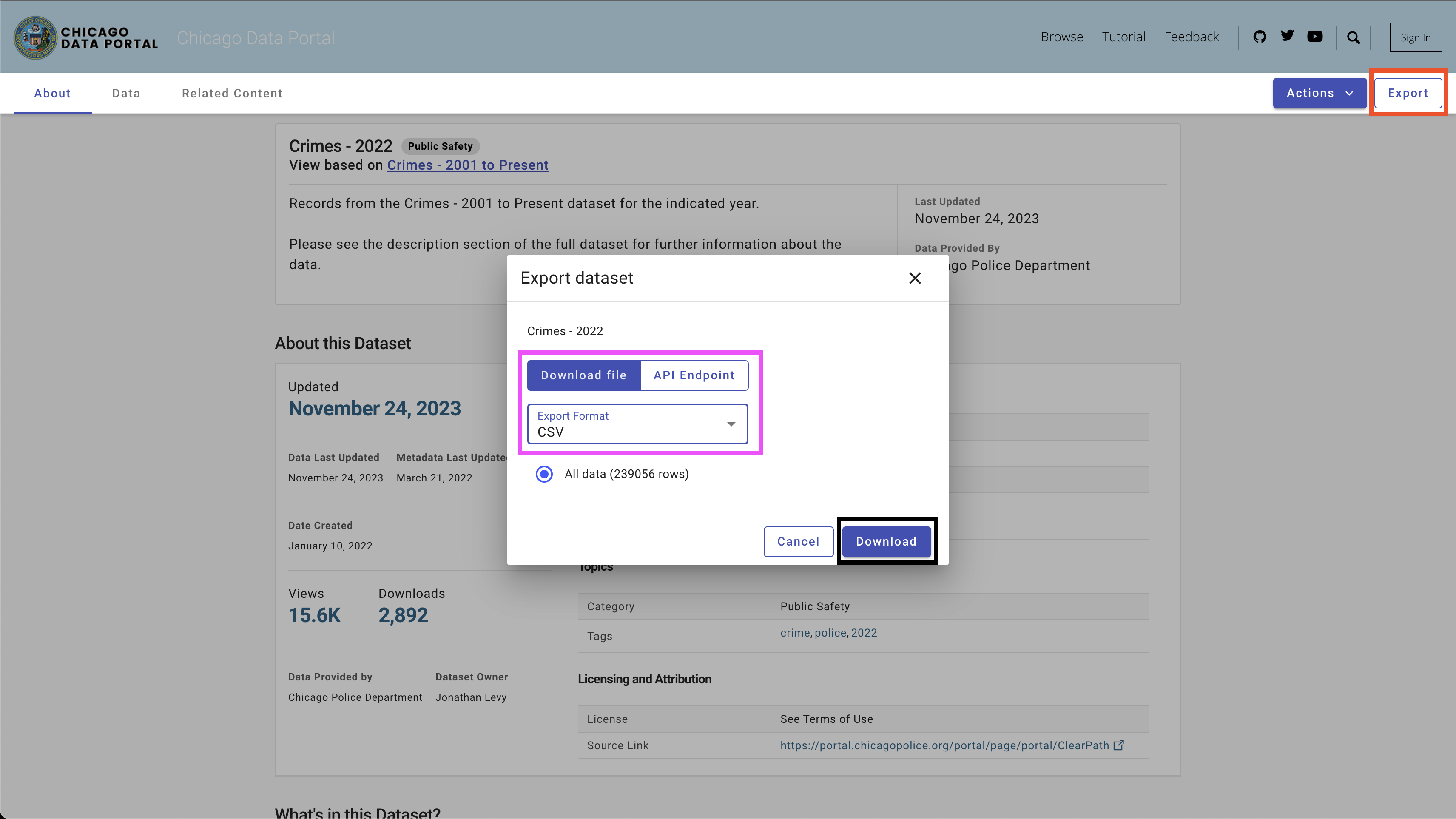
Untuk mengunduh data, gunakan tombol Export di sisi kanan atas, pilih opsi CSV , dan klik tombol Download , seperti yang terlihat pada Gambar 4.
Saya menggunakan konvensi penamaan berikut - chicago_crime_year.csv dan menyimpan file di folder data . Setiap ukuran file mendekati 50 MB. Oleh karena itu, saya menambahkannya ke file abaikan git di bawah folder data , dan mereka tidak tersedia di repo ini. Setelah mengunduh file dan mengatur nama mereka, Anda harus memiliki file berikut di folder:
| ── data
├── chicago_crime_2021.csv
├── chicago_crime_2022.csv
└── chicago_crime_2023.csv
Catatan: Pada saat membuat tutorial ini, data untuk 2023 masih diperbarui. Oleh karena itu, Anda mungkin menerima hasil yang sedikit berbeda ketika menjalankan beberapa kueri di bagian berikut.
Mari kita beralih ke bagian yang menarik, yang menyiapkan generator kode SQL. Di bagian ini, kami akan membuat fungsi Python yang mengambil pertanyaan pengguna, tabel SQL terkait, dan kunci API OpenAI dan menghasilkan kueri SQL yang menjawab pertanyaan pengguna.
Mari kita mulai dengan memuat dataset kejahatan Chicago dan perpustakaan Python yang diperlukan.
Hal pertama yang pertama - mari kita muat perpustakaan Python yang diperlukan:
import pandas as pd
import duckdb
import openai
import time
import osKami akan menggunakan pustaka OS dan waktu untuk memuat file CSV dan memformat ulang bidang tertentu. Data akan diproses menggunakan pustaka PANDAS , dan kami akan mensimulasikan perintah SQL dengan perpustakaan DuckDB . Terakhir, kami akan membuat koneksi ke API OpenAI menggunakan Perpustakaan OpenAI .
Selanjutnya, kami akan memuat file CSV dari folder data. The code below reads all the CSV files available in the data folder:
path = "./data"
files = [ x for x in os . listdir ( path = path ) if ".csv" in x ]Jika Anda mengunduh file yang sesuai untuk tahun 2021 hingga 2023 dan menggunakan konvensi penamaan yang sama, Anda harus mengharapkan output berikut:
print ( files )
[ 'chicago_crime_2022.csv' , 'chicago_crime_2023.csv' , 'chicago_crime_2021.csv' ]Selanjutnya, kami akan membaca dan memuat semua file dan menambahkannya ke dalam bingkai data PANDAS:
chicago_crime = pd . concat (( pd . read_csv ( path + "/" + f ) for f in files ), ignore_index = True )
chicago_crime . headJika Anda memuat file dengan benar, Anda harus mengharapkan output berikut:
< bound method NDFrame . head of ID Case Number Date Block
0 12589893 JF109865 01 / 11 / 2022 03 : 00 : 00 PM 087 XX S KINGSTON AVE
1 12592454 JF113025 01 / 14 / 2022 03 : 55 : 00 PM 067 XX S MORGAN ST
2 12601676 JF124024 01 / 13 / 2022 04 : 00 : 00 PM 031 XX W AUGUSTA BLVD
3 12785595 JF346553 08 / 05 / 2022 09 : 00 : 00 PM 072 XX S UNIVERSITY AVE
4 12808281 JF373517 08 / 14 / 2022 02 : 00 : 00 PM 055 XX W ARDMORE AVE
... ... ... ... ...
648826 26461 JE455267 11 / 24 / 2021 12 : 51 : 00 AM 107 XX S LANGLEY AVE
648827 26041 JE281927 06 / 28 / 2021 01 : 12 : 00 AM 117 XX S LAFLIN ST
648828 26238 JE353715 08 / 29 / 2021 03 : 07 : 00 AM 010 XX N LAWNDALE AVE
648829 26479 JE465230 12 / 03 / 2021 08 : 37 : 00 PM 000 XX W 78 TH PL
648830 11138622 JA495186 05 / 21 / 2021 12 : 01 : 00 AM 019 XX N PULASKI RD
IUCR Primary Type
0 1565 SEX OFFENSE
1 2826 OTHER OFFENSE
2 1752 OFFENSE INVOLVING CHILDREN
3 1544 SEX OFFENSE
4 1562 SEX OFFENSE
... ... ...
648826 0110 HOMICIDE
648827 0110 HOMICIDE
648828 0110 HOMICIDE
648829 0110 HOMICIDE
648830 1752 OFFENSE INVOLVING CHILDREN
...
648828 41.899709 - 87.718893 ( 41.899709327 , - 87.718893208 )
648829 41.751832 - 87.626374 ( 41.751831742 , - 87.626373808 )
648830 41.915798 - 87.726524 ( 41.915798196 , - 87.726524412 ) Catatan: Saat membuat tutorial ini, data parsial untuk 2023 tersedia. Menambahkan tiga file akan menghasilkan lebih banyak baris daripada yang ditunjukkan (648830 baris).
Sebelum kita masuk ke kode Python, mari kita berhenti dan meninjau cara kerja rekayasa yang cepat dan bagaimana kita dapat membantu chatgpt (dan umumnya setiap llm) menghasilkan hasil terbaik. Kami akan menggunakan di bagian ini antarmuka web chatgpt.
Salah satu faktor utama dalam model statistik dan pembelajaran mesin adalah bahwa kualitas output tergantung pada kualitas input. Seperti kata frasa terkenal- sampah, sampah . Demikian pula, kualitas output LLM tergantung pada kualitas prompt.
Misalnya, mari kita asumsikan kita ingin menghitung jumlah kasus yang berakhir dengan penangkapan.
Jika kami menggunakan prompt berikut:
Create an SQL query that counts the number of records that ended up with an arrest.
Ini output dari chatgpt:
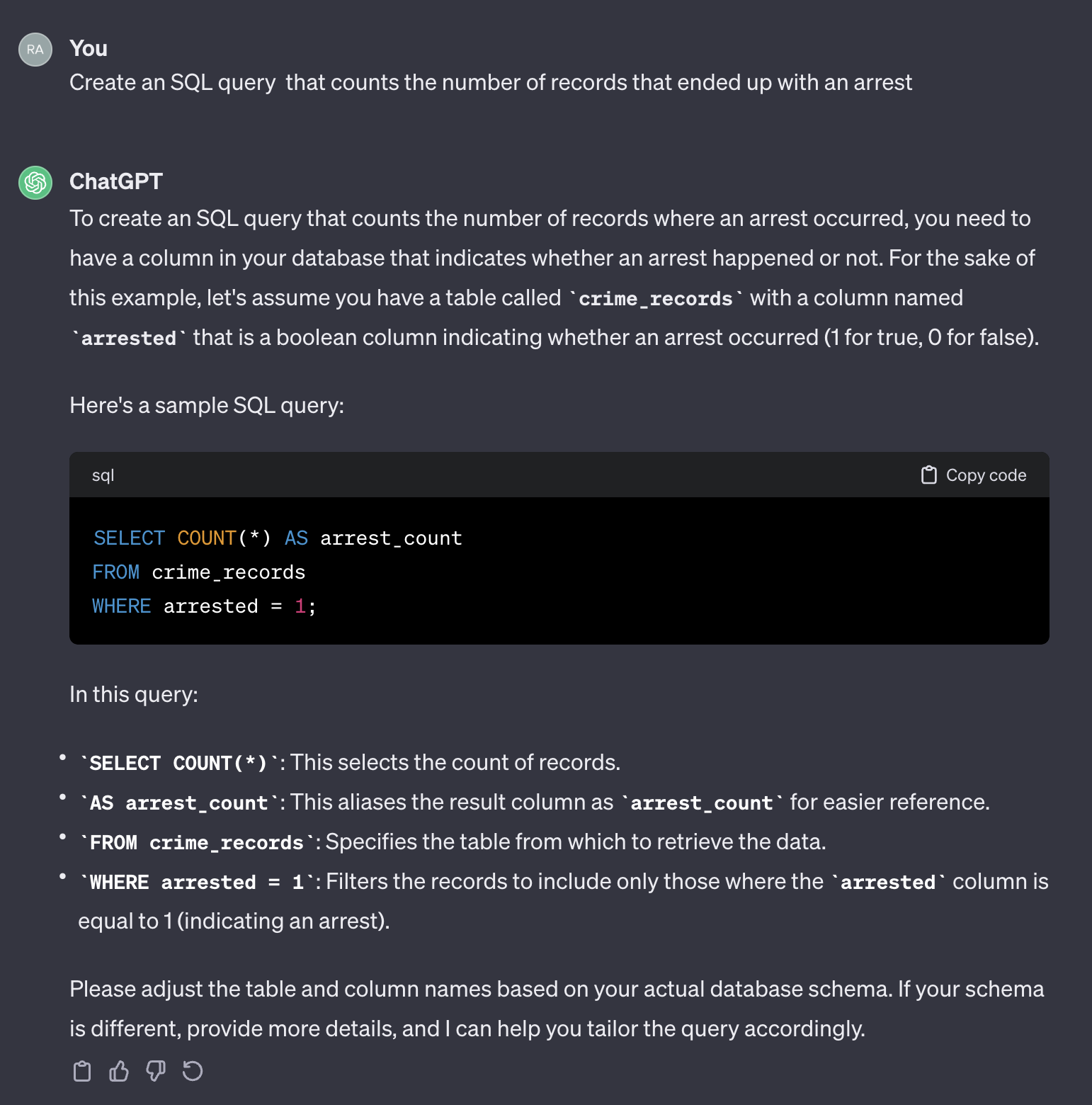
Perlu dicatat bahwa chatgpt memberikan respons umum. Meskipun umumnya benar, mungkin tidak praktis untuk digunakan dalam proses otomatis. Pertama, nama bidang dalam respons tidak cocok dengan yang ada di tabel aktual yang perlu kita minta. Kedua, bidang yang mewakili hasil penangkapan adalah boolean ( true atau false ) alih -alih bilangan bulat ( 0 atau 1 ).
Chatgpt, dalam hal itu, bertindak seperti manusia. Tidak mungkin Anda akan menerima jawaban yang lebih akurat dari manusia dengan memposting pertanyaan yang sama pada bentuk pengkodean seperti Stack Overflow atau platform serupa lainnya. Mengingat bahwa kami tidak memberikan konteks atau informasi tambahan apa pun tentang karakteristik tabel, mengharapkan chatgpt untuk menebak nama lapangan dan nilai -nilainya akan tidak masuk akal. Konteksnya adalah faktor penting dalam prompt apa pun. Untuk mengilustrasikan poin ini, mari kita lihat bagaimana chatgpt menangani prompt berikut:
I have a table named chicago_crime with the crime records in Chicago City since 2021. The Arrest field defines if the case ended up with arrest or not, and it is a boolean (true or false).
I want to create an SQL query that counts the number of records that ended up with an arrest.
Ini output dari chatgpt:
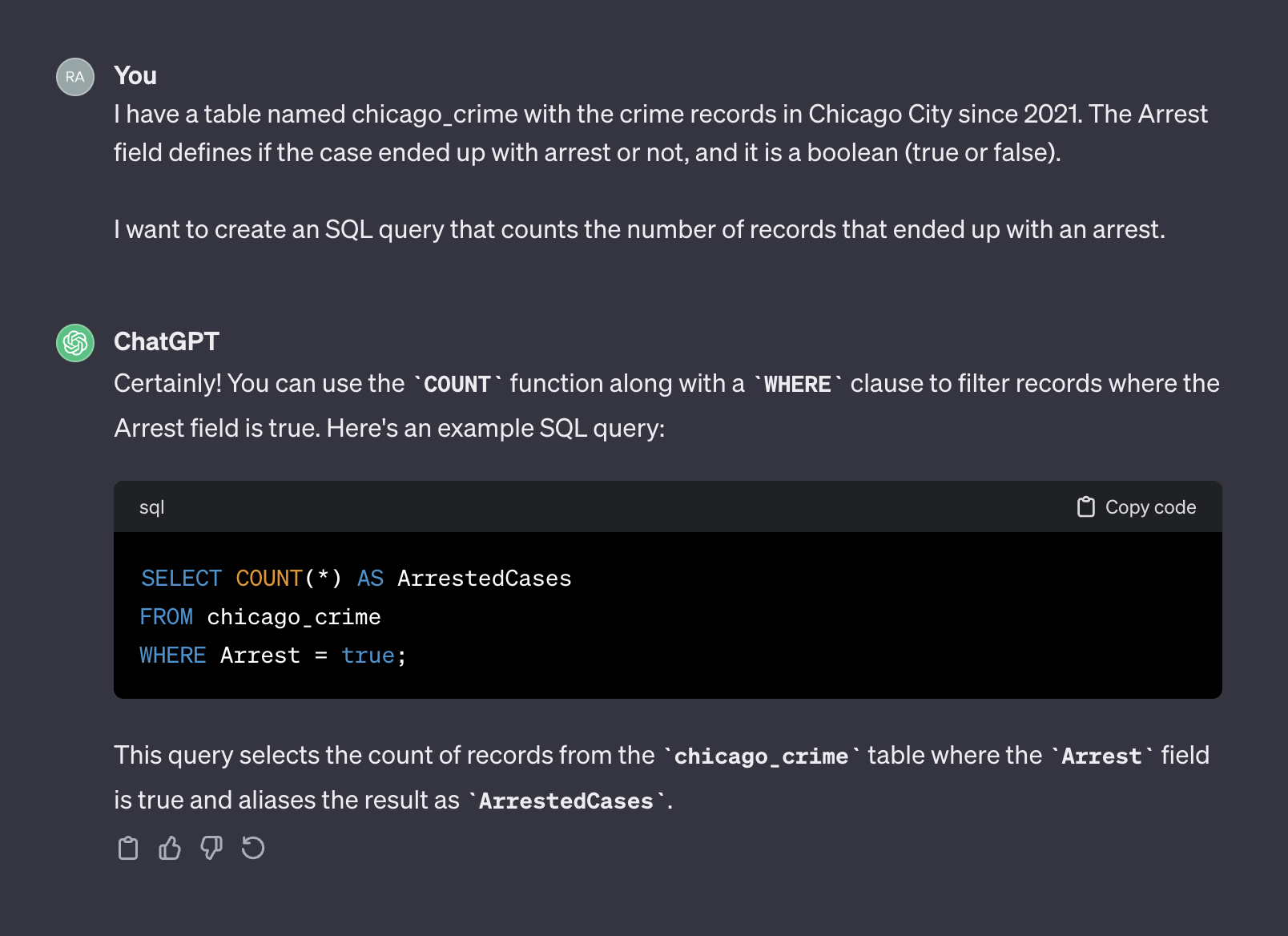
Kali ini, setelah menambahkan konteks, chatgpt mengembalikan kueri yang benar yang dapat kita gunakan apa adanya. Secara umum, ketika bekerja dengan generator teks, prompt harus mencakup dua komponen - konteks dan permintaan. Pada prompt di atas, paragraf pertama mewakili konteks prompt:
I have a table named chicago_crime with the crime records in Chicago City since 2021. The Arrest field defines if the case ended up with arrest or not, and it is a boolean (true or false).
Di mana paragraf kedua, mewakili permintaan:
I want to create an SQL query that counts the number of records that ended up with an arrest.
API OpenAI menyebut konteks sebagai system dan meminta sebagai user .
Dokumentasi API OpenAI memberikan rekomendasi untuk cara mengatur system dan komponen user dalam prompt saat meminta untuk menghasilkan kode SQL:
System
Given the following SQL tables, your job is to write queries given a user’s request.
CREATE TABLE Orders (
OrderID int,
CustomerID int,
OrderDate datetime,
OrderTime varchar(8),
PRIMARY KEY (OrderID)
);
CREATE TABLE OrderDetails (
OrderDetailID int,
OrderID int,
ProductID int,
Quantity int,
PRIMARY KEY (OrderDetailID)
);
CREATE TABLE Products (
ProductID int,
ProductName varchar(50),
Category varchar(50),
UnitPrice decimal(10, 2),
Stock int,
PRIMARY KEY (ProductID)
);
CREATE TABLE Customers (
CustomerID int,
FirstName varchar(50),
LastName varchar(50),
Email varchar(100),
Phone varchar(20),
PRIMARY KEY (CustomerID)
);
User
Write a SQL query which computes the average total order value for all orders on 2023-04-01.
Pada bagian selanjutnya, kami akan menggunakan contoh OpenAI di atas dan menggeneralisasikannya ke dalam templat tujuan umum.
Pada bagian sebelumnya, kami membahas pentingnya rekayasa cepat dan bagaimana memberikan konteks yang baik dapat meningkatkan akurasi respons LLM. Selain itu, kami melihat struktur prompt yang direkomendasikan OpenAi untuk pembuatan kode SQL. Di bagian ini, kami akan fokus pada generalisasi proses pembuatan petunjuk untuk generasi SQL berdasarkan prinsip -prinsip tersebut. Tujuannya adalah untuk membangun fungsi Python yang menerima nama tabel dan pertanyaan pengguna dan membuat prompt sesuai. Misalnya, untuk tabel tabel chicago_crime yang kami muat sebelumnya dan pertanyaan yang kami tanyakan di bagian sebelumnya, fungsi harus membuat prompt di bawah ini:
Given the following SQL table, your job is to write queries given a user’s request.
CREATE TABLE chicago_crime (ID BIGINT, Case Number VARCHAR, Date VARCHAR, Block VARCHAR, IUCR VARCHAR, Primary Type VARCHAR, Description VARCHAR, Location Description VARCHAR, Arrest BOOLEAN, Domestic BOOLEAN, Beat BIGINT, District BIGINT, Ward DOUBLE, Community Area BIGINT, FBI Code VARCHAR, X Coordinate DOUBLE, Y Coordinate DOUBLE, Year BIGINT, Updated On VARCHAR, Latitude DOUBLE, Longitude DOUBLE, Location VARCHAR)
Write a SQL query that returns - How many cases ended up with arrest?
Mari kita mulai dengan struktur cepat. Kami akan mengadopsi format openai dan menggunakan templat berikut:
system_template = """
Given the following SQL table, your job is to write queries given a user’s request. n
CREATE TABLE {} ({}) n
"""
user_template = "Write a SQL query that returns - {}" Di mana system_template menerima dua elemen:
Untuk tutorial ini, kami akan menggunakan perpustakaan DuckDB untuk menangani bingkai data panda karena merupakan tabel SQL dan mengekstrak nama dan atribut lapangan tabel menggunakan fungsi duckdb.sql . Misalnya, mari kita gunakan Perintah DESCRIBE SQL untuk mengekstrak Informasi Bidang Tabel chicago_crime :
duckdb . sql ( "DESCRIBE SELECT * FROM chicago_crime;" )Yang seharusnya mengembalikan tabel di bawah ini:
┌──────────────────────┬─────────────┬─────────┬─────────┬─────────┬─────────┐
│ column_name │ column_type │ null │ key │ default │ extra │
│ varchar │ varchar │ varchar │ varchar │ varchar │ varchar │
├──────────────────────┼─────────────┼─────────┼─────────┼─────────┼─────────┤
│ ID │ BIGINT │ YES │ NULL │ NULL │ NULL │
│ Case Number │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ Date │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ Block │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ IUCR │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ Primary Type │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ Description │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ Location Description │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ Arrest │ BOOLEAN │ YES │ NULL │ NULL │ NULL │
│ Domestic │ BOOLEAN │ YES │ NULL │ NULL │ NULL │
│ Beat │ BIGINT │ YES │ NULL │ NULL │ NULL │
│ District │ BIGINT │ YES │ NULL │ NULL │ NULL │
│ Ward │ DOUBLE │ YES │ NULL │ NULL │ NULL │
│ Community Area │ BIGINT │ YES │ NULL │ NULL │ NULL │
│ FBI Code │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ X Coordinate │ DOUBLE │ YES │ NULL │ NULL │ NULL │
│ Y Coordinate │ DOUBLE │ YES │ NULL │ NULL │ NULL │
│ Year │ BIGINT │ YES │ NULL │ NULL │ NULL │
│ Updated On │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ Latitude │ DOUBLE │ YES │ NULL │ NULL │ NULL │
│ Longitude │ DOUBLE │ YES │ NULL │ NULL │ NULL │
│ Location │ VARCHAR │ YES │ NULL │ NULL │ NULL │
├──────────────────────┴─────────────┴─────────┴─────────┴─────────┴─────────┤
│ 22 rows 6 columns │
└────────────────────────────────────────────────────────────────────────────┘Catatan: Informasi yang kami butuhkan - nama kolom dan atributnya tersedia di dua kolom pertama. Oleh karena itu, kita perlu menguraikan kolom -kolom itu dan menggabungkannya bersama -sama ke format berikut:
Column_Name Column_Attribute
Misalnya, kolom Case Number harus ditransfer ke dalam format berikut:
Case Number VARCHAR
Fungsi create_message di bawah ini mengatur proses mengambil nama tabel dan pertanyaan dan menghasilkan prompt menggunakan logika di atas:
def create_message ( table_name , query ):
class message :
def __init__ ( message , system , user , column_names , column_attr ):
message . system = system
message . user = user
message . column_names = column_names
message . column_attr = column_attr
system_template = """
Given the following SQL table, your job is to write queries given a user’s request. n
CREATE TABLE {} ({}) n
"""
user_template = "Write a SQL query that returns - {}"
tbl_describe = duckdb . sql ( "DESCRIBE SELECT * FROM " + table_name + ";" )
col_attr = tbl_describe . df ()[[ "column_name" , "column_type" ]]
col_attr [ "column_joint" ] = col_attr [ "column_name" ] + " " + col_attr [ "column_type" ]
col_names = str ( list ( col_attr [ "column_joint" ]. values )). replace ( '[' , '' ). replace ( ']' , '' ). replace ( ' ' ' , '' )
system = system_template . format ( table_name , col_names )
user = user_template . format ( query )
m = message ( system = system , user = user , column_names = col_attr [ "column_name" ], column_attr = col_attr [ "column_type" ])
return m Fungsi membuat templat prompt dan mengembalikan system prompt dan komponen user dan nama dan atribut kolom. Misalnya, mari kita jalankan jumlah pertanyaan penangkapan:
query = "How many cases ended up with arrest?"
msg = create_message ( table_name = "chicago_crime" , query = query )Ini akan kembali:
print ( msg . system )
Given the following SQL table , your job is to write queries given a user ’ s request .
CREATE TABLE chicago_crime ( ID BIGINT , Case Number VARCHAR , Date VARCHAR , Block VARCHAR , IUCR VARCHAR , Primary Type VARCHAR , Description VARCHAR , Location Description VARCHAR , Arrest BOOLEAN , Domestic BOOLEAN , Beat BIGINT , District BIGINT , Ward DOUBLE , Community Area BIGINT , FBI Code VARCHAR , X Coordinate DOUBLE , Y Coordinate DOUBLE , Year BIGINT , Updated On VARCHAR , Latitude DOUBLE , Longitude DOUBLE , Location VARCHAR )
print ( msg . user )
Write a SQL query that returns - How many cases ended up with arrest ?
print ( msg . column_names )
0 ID
1 Case Number
2 Date
3 Block
4 IUCR
5 Primary Type
6 Description
7 Location Description
8 Arrest
9 Domestic
10 Beat
11 District
12 Ward
13 Community Area
14 FBI Code
15 X Coordinate
16 Y Coordinate
17 Year
18 Updated On
19 Latitude
20 Longitude
21 Location
Name : column_name , dtype : object
print ( msg . column_attr )
0 BIGINT
1 VARCHAR
2 VARCHAR
3 VARCHAR
4 VARCHAR
5 VARCHAR
6 VARCHAR
7 VARCHAR
8 BOOLEAN
9 BOOLEAN
10 BIGINT
11 BIGINT
12 DOUBLE
13 BIGINT
14 VARCHAR
15 DOUBLE
16 DOUBLE
17 BIGINT
18 VARCHAR
19 DOUBLE
20 DOUBLE
21 VARCHAR
Name : column_type , dtype : object Output dari fungsi create_message dirancang agar sesuai dengan argumen fungsi ChatCompletion.create API.
Bagian ini berfokus pada fungsionalitas Perpustakaan Python Openai. Perpustakaan OpenAI memungkinkan akses mulus ke API Openai REST. We will use the library to connect to the API and send GET requests with our prompt.
Mari kita mulai dengan menghubungkan ke API dengan memberi makan API kami ke fungsi openai.api_key :
openai . api_key = os . getenv ( 'OPENAI_KEY' ) CATATAN: Kami menggunakan fungsi getenv dari pustaka os untuk memuat variabel lingkungan openai_key. Atau, Anda dapat memberi makan langsung kunci API Anda:
openai . api_key = "YOUR_OPENAI_API_KEY"API OpenAI menyediakan akses ke berbagai LLM dengan fungsi yang berbeda. Anda dapat menggunakan fungsi openai.model.list untuk mendapatkan daftar model yang tersedia:
openai . Model . list () Untuk mengubahnya menjadi format yang bagus, Anda dapat membungkusnya dalam bingkai data pandas :
openai_api_models = pd . DataFrame ( openai . Model . list ()[ "data" ])
openai_api_models . headDan harus mengharapkan output berikut:
<bound method NDFrame.head of id object created owned_by
0 text-search-babbage-doc-001 model 1651172509 openai-dev
1 gpt-4 model 1687882411 openai
2 curie-search-query model 1651172509 openai-dev
3 text-davinci-003 model 1669599635 openai-internal
4 text-search-babbage-query-001 model 1651172509 openai-dev
.. ... ... ... ...
65 gpt-3.5-turbo-instruct-0914 model 1694122472 system
66 dall-e-2 model 1698798177 system
67 tts-1-1106 model 1699053241 system
68 tts-1-hd-1106 model 1699053533 system
69 gpt-3.5-turbo-16k model 1683758102 openai-internal
[70 rows x 4 columns]>
Untuk kasus penggunaan kami, pembuatan teks, kami akan menggunakan model gpt-3.5-turbo , yang merupakan peningkatan model GPT3. Model gpt-3.5-turbo mewakili serangkaian model yang terus diperbarui, dan secara default, jika versi model tidak ditentukan, API akan menunjukkan rilis stabil terbaru. Saat membuat tutorial ini, model 3.5 default adalah gpt-3.5-turbo-0613 , menggunakan 4.096 token, dan dilatih dengan data hingga September 2021.
Untuk mengirim permintaan GET dengan prompt kami, kami akan menggunakan fungsi ChatCompletion.create . Fungsi ini memiliki banyak argumen, dan kami akan menggunakan yang berikut:
model - ID Model untuk digunakan, daftar lengkap yang tersedia di sinimessages - daftar pesan yang terdiri dari percakapan sejauh ini (misalnya prompt)temperature - Kelola keacakan atau determinisme output proses dengan mengatur level suhu pengambilan sampel. Tingkat suhu menerima nilai antara 0 dan 2. Ketika nilai argumen lebih tinggi, output menjadi lebih acak. Sebaliknya, ketika nilai argumen lebih dekat ke 0, output menjadi lebih deterministik (dapat direproduksi)max_tokens - Jumlah maksimum token untuk menghasilkan dalam penyelesaianDaftar lengkap argumen fungsi yang tersedia di API Documentaiton.
Dalam contoh di bawah ini, kami akan menggunakan prompt yang sama dengan yang digunakan pada antarmuka web chatgpt (yaitu, Gambar 5), kali ini menggunakan API. Kami akan menghasilkan prompt dengan fungsi create_message :
query = "How many cases ended up with arrest?"
prompt = create_message ( table_name = "chicago_crime" , query = query ) Mari kita ubah prompt di atas ke dalam struktur ChatCompletion.create Buat argumen messages fungsi:
message = [
{
"role" : "system" ,
"content" : prompt . system
},
{
"role" : "user" ,
"content" : prompt . user
}
] Selanjutnya, kami akan mengirim prompt (yaitu, objek message ) ke API menggunakan fungsi ChatCompletion.create :
response = openai . ChatCompletion . create (
model = "gpt-3.5-turbo" ,
messages = message ,
temperature = 0 ,
max_tokens = 256 ) Kami akan mengatur argumen temperature ke 0 untuk memastikan reproduktifitas tinggi dan membatasi jumlah token dalam penyelesaian teks menjadi 256. Fungsi mengembalikan objek JSON dengan penyelesaian teks, metadata, dan informasi lainnya:
print ( response )
< OpenAIObject chat . completion id = chatcmpl - 8 PzomlbLrTOTx1uOZm4WQnGr4JwU7 at 0xffff4b0dcb80 > JSON : {
"id" : "chatcmpl-8PzomlbLrTOTx1uOZm4WQnGr4JwU7" ,
"object" : "chat.completion" ,
"created" : 1701206520 ,
"model" : "gpt-3.5-turbo-0613" ,
"choices" : [
{
"index" : 0 ,
"message" : {
"role" : "assistant" ,
"content" : "SELECT COUNT(*) FROM chicago_crime WHERE Arrest = true;"
},
"finish_reason" : "stop"
}
],
"usage" : {
"prompt_tokens" : 137 ,
"completion_tokens" : 12 ,
"total_tokens" : 149
}
}Menggunakan Hindia Respons, kami dapat mengekstrak kueri SQL:
sql = response [ "choices" ][ 0 ][ "message" ][ "content" ]
print ( sql ) ' SELECT COUNT(*) FROM chicago_crime WHERE Arrest = true; ' Menggunakan fungsi duckdb.sql untuk menjalankan kode SQL:
duckdb . sql ( sql ). show ()
┌──────────────┐
│ count_star () │
│ int64 │
├──────────────┤
│ 77635 │
└──────────────┘Di bagian selanjutnya, kami akan menggeneralisasi dan memfungsikan semua langkah.
Pada bagian sebelumnya, kami memperkenalkan format prompt, mengatur fungsi create_message , dan meninjau fungsionalitas fungsi ChatCompletion.create . Di bagian ini kami menjahit semuanya.
Satu hal yang perlu diperhatikan tentang kode SQL yang dikembalikan dari fungsi ChatCompletion.create adalah bahwa variabel tidak kembali dengan kutipan. Itu mungkin menjadi masalah ketika nama variabel dalam kueri menggabungkan dua atau lebih kata. Misalnya, menggunakan variabel seperti Case Number atau Primary Type dari chicago_crime di dalam kueri tanpa menggunakan kutipan akan menghasilkan kesalahan.
Kami akan menggunakan fungsi helper di bawah ini untuk menambahkan kutipan ke variabel dalam kueri jika kueri yang dikembalikan tidak memilikinya:
def add_quotes ( query , col_names ):
for i in col_names :
if i in query :
l = query . find ( i )
if query [ l - 1 ] != "'" and query [ l - 1 ] != '"' :
query = str ( query ). replace ( i , '"' + i + '"' )
return ( query ) Input fungsi adalah kueri dan nama kolom tabel yang sesuai. Ini mengulangi nama kolom dan menambahkan kutipan jika menemukan kecocokan dalam kueri. Misalnya, kami dapat menjalankannya dengan kueri SQL yang kami pural dari ChatCompletion.create output fungsi:
add_quotes ( query = sql , col_names = prompt . column_names )
'SELECT COUNT(*) FROM chicago_crime WHERE "Arrest" = true;' Anda dapat melihat bahwa itu menambahkan kutipan ke variabel Arrest .
Kami sekarang dapat memperkenalkan fungsi lang2sql yang memanfaatkan tiga fungsi yang kami perkenalkan sejauh ini - create_message , ChatCompletion.create , dan add_quotes untuk menerjemahkan pertanyaan pengguna ke kode SQL:
def lang2sql ( api_key , table_name , query , model = "gpt-3.5-turbo" , temperature = 0 , max_tokens = 256 , frequency_penalty = 0 , presence_penalty = 0 ):
class response :
def __init__ ( output , message , response , sql ):
output . message = message
output . response = response
output . sql = sql
openai . api_key = api_key
m = create_message ( table_name = table_name , query = query )
message = [
{
"role" : "system" ,
"content" : m . system
},
{
"role" : "user" ,
"content" : m . user
}
]
openai_response = openai . ChatCompletion . create (
model = model ,
messages = message ,
temperature = temperature ,
max_tokens = max_tokens ,
frequency_penalty = frequency_penalty ,
presence_penalty = presence_penalty )
sql_query = add_quotes ( query = openai_response [ "choices" ][ 0 ][ "message" ][ "content" ], col_names = m . column_names )
output = response ( message = m , response = openai_response , sql = sql_query )
return output Fungsi menerima, sebagai input, kunci API OpenAI, nama tabel, dan parameter inti dari fungsi ChatCompletion.create dan mengembalikan objek dengan prompt, respons API, dan kueri yang diuraikan. Misalnya, mari kita coba untuk menjalankan kembali kueri yang sama yang kami gunakan di bagian sebelumnya dengan fungsi lang2sql :
query = "How many cases ended up with arrest?"
response = lang2sql ( api_key = api_key , table_name = "chicago_crime" , query = query )Kita dapat mengekstrak kueri SQL dari objek output:
print ( response . sql ) SELECT COUNT ( * ) FROM chicago_crime WHERE " Arrest " = true;Kami dapat menguji output sehubungan dengan hasil yang kami terima di bagian sebelumnya:
duckdb . sql ( response . sql ). show ()
┌──────────────┐
│ count_star () │
│ int64 │
├──────────────┤
│ 77635 │
└──────────────┘Sekarang mari kita tambahkan kompleksitas tambahan untuk pertanyaan dan tanyakan kasus yang berakhir dengan penangkapan selama 2022:
query = "How many cases ended up with arrest during 2022"
response = lang2sql ( api_key = api_key , table_name = "chicago_crime" , query = query ) Seperti yang Anda lihat, model mengidentifikasi dengan benar bidang yang relevan sebagai Year dan menghasilkan kueri yang benar:
print ( response . sql )Kode SQL:
SELECT COUNT ( * ) FROM chicago_crime WHERE " Arrest " = TRUE AND " Year " = 2022 ;Menguji kueri di tabel:
duckdb . sql ( response . sql ). show ()
┌──────────────┐
│ count_star () │
│ int64 │
├──────────────┤
│ 27805 │
└──────────────┘Berikut adalah contoh pertanyaan sederhana yang membutuhkan pengelompokan dengan variabel tertentu:
query = "Summarize the cases by primary type"
response = lang2sql ( api_key = api_key , table_name = "chicago_crime" , query = query )
print ( response . sql )Anda dapat melihat dari output respons bahwa kode SQL dalam kasus ini benar:
SELECT " Primary Type " , COUNT ( * ) as TotalCases
FROM chicago_crime
GROUP BY " Primary Type "Ini adalah output dari kueri:
duckdb . sql ( response . sql ). show ()
┌───────────────────────────────────┬────────────┐
│ Primary Type │ TotalCases │
│ varchar │ int64 │
├───────────────────────────────────┼────────────┤
│ MOTOR VEHICLE THEFT │ 54934 │
│ ROBBERY │ 25082 │
│ WEAPONS VIOLATION │ 24672 │
│ INTERFERENCE WITH PUBLIC OFFICER │ 1161 │
│ OBSCENITY │ 127 │
│ STALKING │ 1206 │
│ BATTERY │ 115760 │
│ OFFENSE INVOLVING CHILDREN │ 5177 │
│ CRIMINAL TRESPASS │ 11255 │
│ PUBLIC PEACE VIOLATION │ 1980 │
│ · │ · │
│ · │ · │
│ · │ · │
│ ASSAULT │ 58685 │
│ CRIMINAL DAMAGE │ 75611 │
│ DECEPTIVE PRACTICE │ 46377 │
│ NARCOTICS │ 13931 │
│ BURGLARY │ 19898 │
...
├───────────────────────────────────┴────────────┤
│ 31 rows ( 20 shown ) 2 columns │
└────────────────────────────────────────────────┘Terakhir namun tidak kalah pentingnya, LLM dapat mengidentifikasi konteks (misalnya, variabel mana) bahkan ketika kami memberikan nama variabel parsial:
query = "How many cases is the type of robbery?"
response = lang2sql ( api_key = api_key , table_name = "chicago_crime" , query = query )
print ( response . sql )Ini mengembalikan kode SQL di bawah ini:
SELECT COUNT ( * ) FROM chicago_crime WHERE " Primary Type " = ' ROBBERY ' ;Ini adalah output dari kueri:
duckdb . sql ( response . sql ). show ()
┌──────────────┐
│ count_star () │
│ int64 │
├──────────────┤
│ 25082 │
└──────────────┘Dalam tutorial ini, kami telah menunjukkan cara membangun generator kode SQL dengan beberapa baris kode Python dan memanfaatkan API OpenAI. Kami telah melihat bahwa kualitas prompt sangat penting untuk keberhasilan kode SQL yang dihasilkan. Selain konteks yang disediakan oleh prompt, nama bidang juga harus memberikan informasi tentang karakteristik lapangan untuk membantu LLM mengidentifikasi relevansi bidang dengan pertanyaan pengguna.
Meskipun tutorial ini terbatas untuk bekerja dengan satu tabel (misalnya, tidak ada gabungan antar tabel), beberapa LLM, seperti yang tersedia di OpenAi, dapat menangani kasus yang lebih kompleks, termasuk bekerja dengan beberapa tabel dan mengidentifikasi operasi gabungan yang benar. Menyesuaikan fungsi Lang2SQL untuk menangani beberapa tabel bisa menjadi langkah berikutnya yang bagus.
Tutorial ini dilisensikan di bawah lisensi internasional Atribut-Nonkomersial-Sharealike 4.0 Creative Commons.


