Editor Downcodes mengetahui bahwa tim peneliti Tiongkok berhasil membuat kumpulan data AI multi-modal publik terbesar "Infinity-MM" dan melatih model kecil Aquila-VL-2B dengan kinerja luar biasa berdasarkan kumpulan data ini. Model ini mencapai hasil luar biasa dalam beberapa pengujian benchmark, menunjukkan potensi besar data sintetis dalam meningkatkan performa model AI. Kumpulan data Infinity-MM berisi berbagai jenis data seperti deskripsi gambar dan data instruksi visual. Proses pembuatannya menggunakan model AI sumber terbuka seperti RAM++ dan MiniCPM-V, dan menjalani pemrosesan multi-level untuk memastikan kualitas dan keragaman data. Model Aquila-VL-2B didasarkan pada arsitektur LLaVA-OneVision dan menggunakan Qwen-2.5 sebagai model bahasa.
Baru-baru ini, tim peneliti dari berbagai institusi Tiongkok berhasil membuat kumpulan data "Infinity-MM", yang saat ini merupakan salah satu kumpulan data AI multi-modal publik terbesar, dan melatih model kecil baru dengan kinerja luar biasa - —Aquila-VL-2B .
Kumpulan data ini terutama berisi empat kategori utama data: 10 juta deskripsi gambar, 24,4 juta data instruksi visual umum, 6 juta data instruksi berkualitas tinggi pilihan, dan 3 juta data yang dihasilkan oleh GPT-4 dan model AI lainnya.
Di sisi generasi, tim peneliti memanfaatkan model AI open source yang ada. Pertama, model RAM++ menganalisis gambar dan mengekstrak informasi penting, kemudian menghasilkan pertanyaan dan jawaban yang relevan. Selain itu, tim membangun sistem klasifikasi khusus untuk menjamin kualitas dan keragaman data yang dihasilkan.
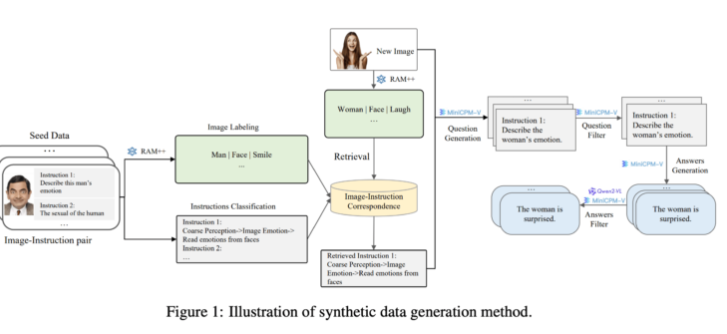
Metode pembuatan data sintetis ini menggunakan metode pemrosesan multi-level, menggabungkan model RAM++ dan MiniCPM-V untuk menyediakan data pelatihan yang akurat untuk sistem AI melalui pengenalan gambar, klasifikasi instruksi, dan pembuatan respons.
Model Aquila-VL-2B didasarkan pada arsitektur LLaVA-OneVision, menggunakan Qwen-2.5 sebagai model bahasa, dan menggunakan SigLIP untuk pemrosesan gambar. Pelatihan model dibagi menjadi empat tahap, secara bertahap meningkatkan kompleksitasnya. Pada tahap pertama, model mempelajari asosiasi dasar gambar-teks; tahap selanjutnya mencakup tugas visi umum, pelaksanaan instruksi spesifik, dan terakhir integrasi data yang dihasilkan secara sintesis. Resolusi gambar juga ditingkatkan secara bertahap selama pelatihan.
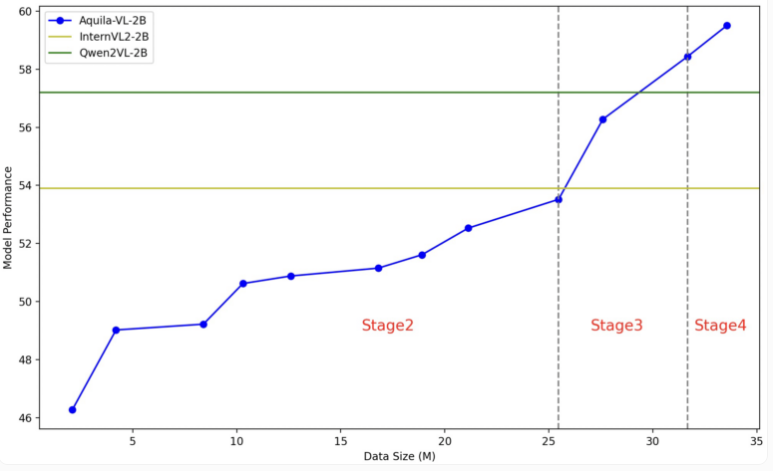
Dalam pengujian tersebut, Aquila-VL-2B meraih hasil terbaik pada pengujian multimodal berbasis MMStar dengan skor 54,9%, dengan volume hanya 2 miliar parameter. Selain itu, model ini memiliki kinerja yang sangat baik dalam tugas-tugas matematika, dengan skor 59% dalam tes MathVista, jauh melebihi sistem serupa.
Pada tes pemahaman gambar secara umum, Aquila-VL-2B juga menunjukkan hasil yang baik, dengan skor HallusionBench sebesar 43% dan skor MMBench sebesar 75,2%. Para peneliti mengatakan bahwa penambahan data yang dihasilkan secara sintetis meningkatkan performa model secara signifikan. Tanpa penggunaan data tambahan ini, performa rata-rata model akan turun sebesar 2,4%.
Kali ini tim peneliti memutuskan untuk membuka kumpulan data dan model kepada komunitas riset. Proses pelatihannya sebagian besar menggunakan Nvidia A100GPU dan chip lokal Tiongkok. Keberhasilan peluncuran Aquila-VL-2B menandai bahwa model sumber terbuka secara bertahap mengikuti tren sistem sumber tertutup tradisional dalam penelitian AI, terutama menunjukkan prospek yang baik dalam memanfaatkan data pelatihan sintetis.
Pintu masuk kertas Infinity-MM: https://arxiv.org/abs/2410.18558
Pintu masuk proyek Aquila-VL-2B: https://huggingface.co/BAAI/Aquila-VL-2B-llava-qwen
Keberhasilan Aquila-VL-2B tidak hanya membuktikan kekuatan teknis Tiongkok di bidang AI, namun juga menyediakan sumber daya berharga bagi komunitas open source. Kinerjanya yang efisien dan strategi terbukanya akan mendorong pengembangan teknologi AI multi-modal, dan penerapannya di masa depan di lebih banyak bidang patut dinantikan.