Pemahaman video yang sangat panjang selalu menjadi masalah yang sulit bagi model bahasa besar multi-modal (MLLM). Model yang ada sulit memproses data video yang melebihi panjang konteks maksimum, dan redaman informasi serta biaya komputasi yang tinggi juga merupakan tantangan utama. Editor Downcodes mengetahui bahwa Zhiyuan Research Institute dan beberapa universitas telah mengusulkan model bahasa visual ultra-panjang yang disebut Video-XL, yang dirancang untuk menangani masalah pemahaman video tingkat jam secara efisien. Teknologi inti dari model ini adalah "ringkasan laten konteks visual", yang secara cerdik memanfaatkan kemampuan pemodelan konteks LLM untuk mengompresi representasi visual yang panjang menjadi bentuk yang lebih ringkas, mirip dengan memadatkan sapi utuh ke dalam semangkuk sari daging sapi, membuat model tersebut lebih efisien. Menyerap informasi penting.
Saat ini, model bahasa besar multimodal (MLLM) telah mengalami kemajuan signifikan dalam bidang pemahaman video, namun pemrosesan video yang sangat panjang masih menjadi tantangan. Hal ini karena MLLM biasanya kesulitan menangani ribuan token visual yang melebihi panjang konteks maksimum dan mengalami pembusukan informasi yang disebabkan oleh agregasi token. Pada saat yang sama, sejumlah besar tag video juga akan menimbulkan biaya komputasi yang tinggi.
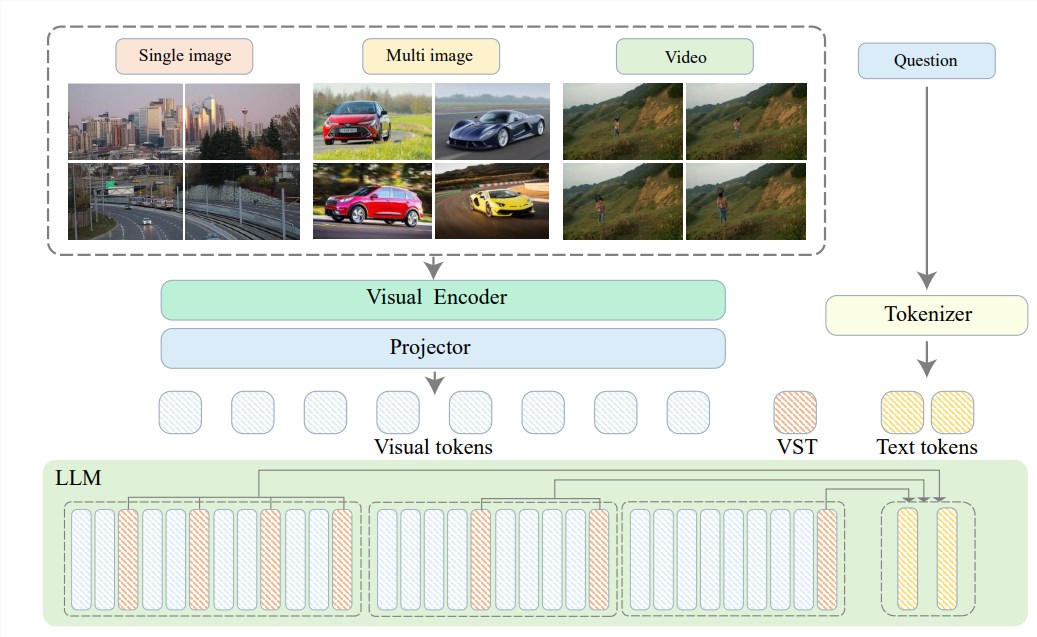
Untuk mengatasi masalah ini, Zhiyuan Research Institute bekerja sama dengan Universitas Shanghai Jiao Tong, Universitas Renmin Tiongkok, Universitas Peking, Universitas Pos dan Telekomunikasi Beijing, dan universitas lain untuk mengusulkan Video-XL, sistem definisi ultra-tinggi yang dirancang untuk pemahaman video tingkat jam yang efisien. Model bahasa visual yang panjang. Inti dari Video-XL terletak pada teknologi "peringkasan laten konteks visual", yang memanfaatkan kemampuan pemodelan konteks yang melekat pada LLM untuk secara efektif memampatkan representasi visual yang panjang ke dalam bentuk yang lebih ringkas.
Sederhananya, konten video dikompres menjadi bentuk yang lebih ramping, seperti memadatkan sapi utuh ke dalam semangkuk sari daging sapi, sehingga lebih mudah dicerna dan diserap oleh model.
Teknologi kompresi ini tidak hanya meningkatkan efisiensi, namun juga secara efektif menyimpan informasi penting dalam video. Tahukah Anda, video berdurasi panjang seringkali berisi banyak informasi yang mubazir, seperti alas kaki wanita tua, panjang dan bau. Video-XL dapat secara akurat menghilangkan informasi yang tidak berguna ini dan hanya menyimpan bagian-bagian penting, yang memastikan bahwa model tidak akan tersesat saat memahami konten video berdurasi panjang.
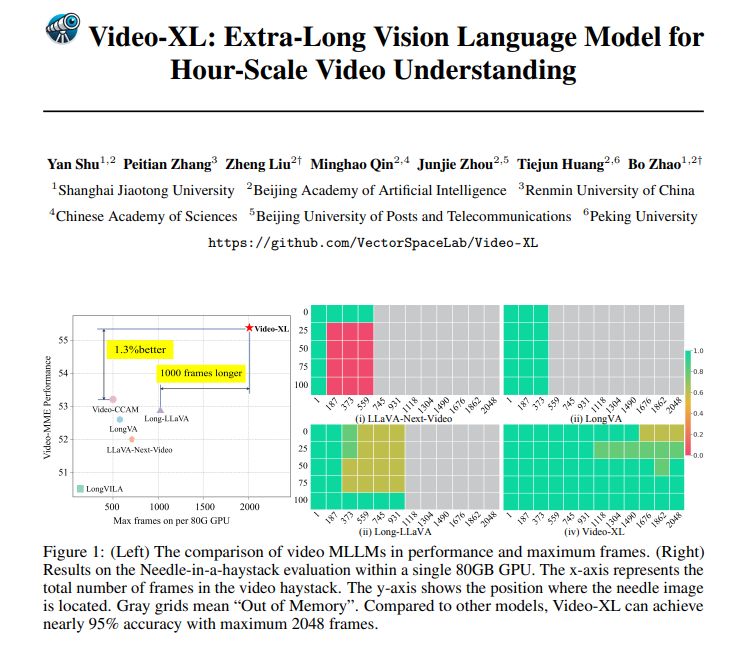
Video-XL tidak hanya hebat secara teori, tetapi juga cukup mumpuni dalam praktiknya. Video-XL telah mencapai hasil terdepan dalam berbagai tolok ukur pemahaman video panjang, terutama dalam pengujian VNBench, yang akurasinya hampir 10% lebih tinggi dibandingkan metode terbaik yang ada.
Yang lebih mengesankan lagi, Video-XL memberikan keseimbangan luar biasa antara efisiensi dan efektivitas, mampu memproses 2048 frame video pada satu GPU 80GB sambil tetap mempertahankan akurasi hampir 95% dalam tingkat evaluasi "jarum di tumpukan jerami".
Video-XL juga memiliki prospek penerapan yang luas. Selain mampu memahami video panjang secara umum, ia juga mampu melakukan tugas-tugas khusus seperti ringkasan film, deteksi anomali pengawasan, dan pengenalan penempatan iklan.
Ini berarti Anda tidak lagi harus menanggung plot yang panjang saat menonton film di masa mendatang. Anda dapat langsung menggunakan Video-XL untuk menghasilkan ringkasan yang efisien, menghemat waktu dan tenaga; atau Anda dapat menggunakannya untuk memantau rekaman pengawasan dan secara otomatis mengidentifikasi kejadian tidak normal , yang jauh lebih efisien daripada pelacakan manual.
Alamat proyek: https://github.com/VectorSpaceLab/Video-XL
Makalah: https://arxiv.org/pdf/2409.14485
Video-XL telah membuat kemajuan terobosan di bidang pemahaman video ultra-panjang. Kombinasi sempurna antara efisiensi dan akurasi memberikan solusi baru untuk pemrosesan video panjang. Video-XL memiliki prospek penerapan yang luas di masa depan dan layak untuk dinantikan!