Pelatihan model besar memakan waktu dan tenaga. Bagaimana meningkatkan efisiensi dan mengurangi konsumsi energi telah menjadi isu utama di bidang AI. AdamW, sebagai pengoptimal default untuk pra-pelatihan Transformer, secara bertahap tidak mampu mengatasi model yang semakin besar. Editor Downcodes akan mengajak Anda mempelajari tentang pengoptimal baru yang dikembangkan oleh tim Tiongkok - C-AdamW. Dengan strategi "hati-hati", ini sangat mengurangi konsumsi energi sekaligus memastikan kecepatan dan stabilitas pelatihan, dan memberikan manfaat besar pada pelatihan model besar. . untuk merevolusi perubahan.
Dalam dunia AI, bekerja keras untuk mencapai keajaiban tampaknya menjadi aturan utama. Semakin besar modelnya, semakin banyak datanya, dan semakin kuat daya komputasinya, tampaknya semakin dekat model tersebut dengan Cawan Suci kecerdasan. Namun, di balik perkembangan pesat tersebut, terdapat juga tekanan besar pada biaya dan konsumsi energi.
Untuk membuat pelatihan AI lebih efisien, para ilmuwan telah mencari pengoptimal yang lebih canggih, seperti pelatih, untuk memandu parameter model agar terus dioptimalkan dan pada akhirnya mencapai kondisi terbaik. AdamW, sebagai pengoptimal default untuk pra-pelatihan Transformer, telah menjadi tolok ukur industri selama bertahun-tahun. Namun, dalam menghadapi skala model yang semakin besar, AdamW juga mulai terlihat tidak mampu mengatasi kemampuannya.
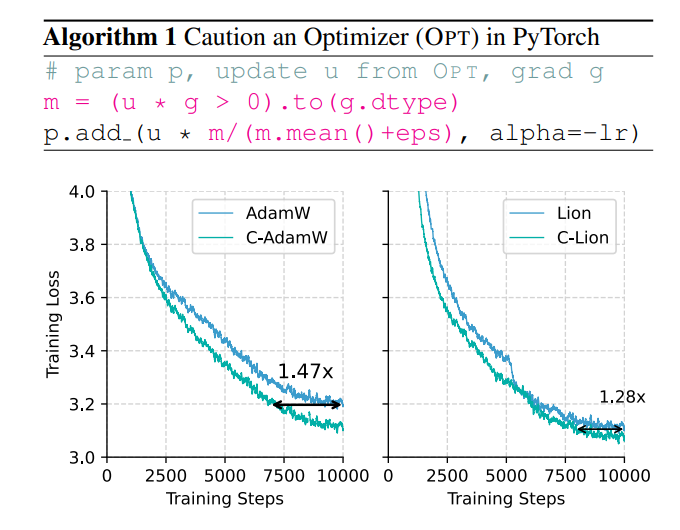
Adakah cara untuk meningkatkan kecepatan latihan sekaligus mengurangi konsumsi energi? Jangan khawatir, tim yang seluruhnya berasal dari Tiongkok hadir dengan senjata rahasia mereka C-AdamW!
Nama lengkap C-AdamW adalah Cautious AdamW, dan nama Cinanya adalah Cautious AdamW. Bukankah kedengarannya sangat Budha? Ya, ide inti dari C-AdamW adalah berpikir dua kali sebelum bertindak.

Bayangkan parameter modelnya seperti sekelompok anak energik yang selalu ingin berlarian. AdamW seperti seorang guru yang berdedikasi, mencoba membimbing mereka ke arah yang benar. Namun terkadang, anak terlalu bersemangat dan berlari ke arah yang salah sehingga membuang-buang waktu dan tenaga.
Saat ini, C-AdamW ibarat seorang tetua bijak dengan sepasang mata tajam, mampu mengidentifikasi secara akurat apakah arah pembaruan sudah benar. Jika arahnya salah, C-AdamW dengan tegas akan berhenti untuk mencegah model tersebut melaju lebih jauh ke jalan yang salah.
Strategi hati-hati ini memastikan bahwa setiap pembaruan dapat secara efektif mengurangi fungsi kerugian, sehingga mempercepat konvergensi model. Hasil eksperimen menunjukkan bahwa C-AdamW meningkatkan kecepatan latihan menjadi 1,47 kali lipat pada pra-latihan Llama dan MAE!
Lebih penting lagi, C-AdamW hampir tidak memerlukan overhead komputasi tambahan dan dapat diimplementasikan dengan modifikasi satu baris sederhana dari kode yang ada. Ini berarti pengembang dapat dengan mudah menerapkan C-AdamW ke berbagai pelatihan model dan menikmati kecepatan dan semangat!
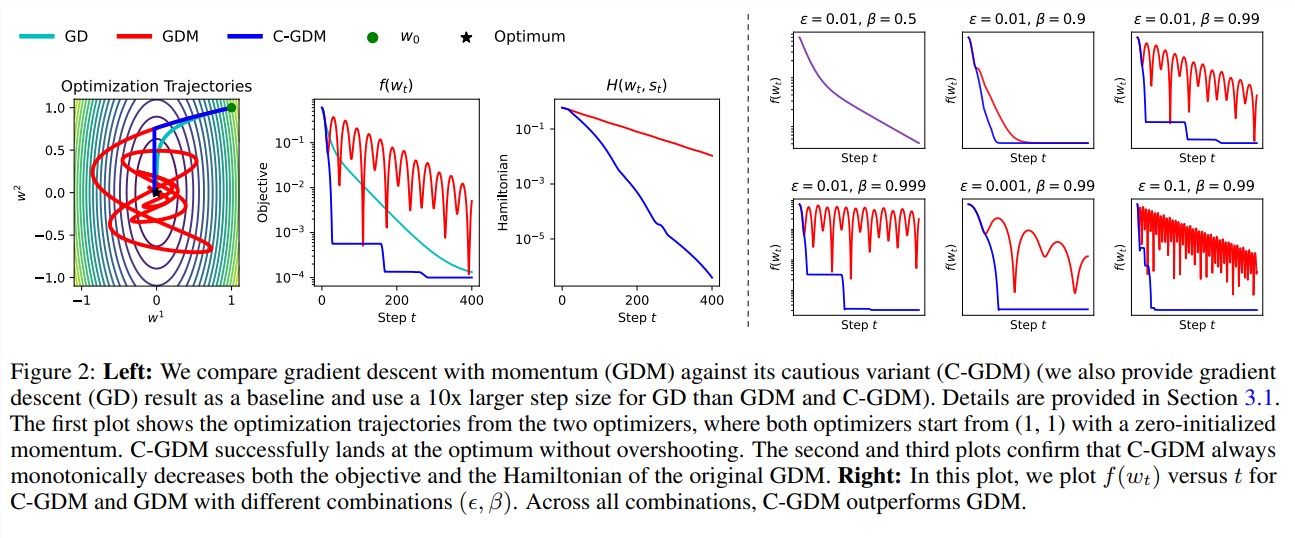
Hal hebat tentang C-AdamW adalah ia mempertahankan fungsi Hamiltonian Adam dan tidak merusak jaminan konvergensi berdasarkan analisis Lyapunov. Artinya C-AdamW tidak hanya lebih cepat, tetapi kestabilannya juga terjamin, dan tidak akan ada masalah seperti training crash.
Tentu saja, menjadi seorang Buddhis bukan berarti Anda tidak giat. Tim peneliti menyatakan bahwa mereka akan terus mengeksplorasi fungsi ϕ yang lebih kaya dan menerapkan masker di ruang fitur daripada ruang parameter untuk lebih meningkatkan kinerja C-AdamW.
Dapat diperkirakan bahwa C-AdamW akan menjadi favorit baru di bidang pembelajaran mendalam, membawa perubahan revolusioner pada pelatihan model besar!
Alamat makalah: https://arxiv.org/abs/2411.16085
GitHub:
https://github.com/kyleliang919/C-Optim
Kemunculan C-AdamW memberikan ide-ide baru untuk memecahkan masalah efisiensi pelatihan model besar dan konsumsi energi. Efisiensi tinggi, stabilitas, dan karakteristiknya yang mudah digunakan membuatnya sangat menjanjikan untuk diterapkan. Diharapkan C-AdamW dapat diterapkan di lebih banyak bidang di masa depan dan mendorong pengembangan teknologi AI secara berkelanjutan. Editor Downcodes akan terus memperhatikan kemajuan teknologi yang relevan, jadi pantau terus!