Editor Downcodes mengetahui bahwa Universitas Peking dan tim peneliti ilmiah lainnya telah merilis LLaVA-o1, model sumber terbuka multimodal yang terkenal. Model ini mengungguli pesaing seperti Gemini, GPT-4o-mini, dan Llama dalam beberapa pengujian benchmark, dan mekanisme penalaran "berpikir lambat" memungkinkannya melakukan penalaran yang lebih kompleks, sebanding dengan GPT-o1. Sumber terbuka LLaVA-o1 akan membawa vitalitas baru pada penelitian dan penerapan di bidang AI multi-modal.
Baru-baru ini, Universitas Peking dan tim peneliti ilmiah lainnya mengumumkan peluncuran model sumber terbuka multi-modal yang disebut LLaVA-o1, yang dikatakan sebagai model bahasa visual pertama yang mampu melakukan penalaran spontan dan sistematis, sebanding dengan GPT-o1.
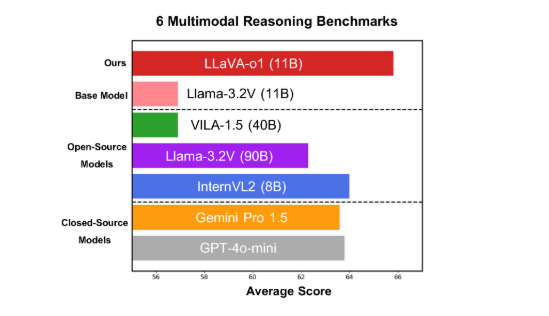
Model ini berkinerja baik pada enam tolok ukur multimodal yang menantang, dengan versi parameter 11B mengungguli pesaing lain seperti Gemini-1.5-pro, GPT-4o-mini, dan Llama-3.2-90B-Vision- Instruct.
LLaVA-o1 didasarkan pada model Llama-3.2-Vision dan mengadopsi mekanisme penalaran "berpikir lambat", yang dapat secara mandiri melakukan proses penalaran yang lebih kompleks, melampaui metode cepat rantai pemikiran tradisional.
Pada tolok ukur inferensi multimodal, LLaVA-o1 mengungguli model dasarnya sebesar 8,9%. Model ini unik karena proses penalarannya dibagi menjadi empat tahap: ringkasan, penjelasan visual, penalaran logis, dan pembuatan kesimpulan. Dalam model tradisional, proses penalaran seringkali relatif sederhana dan dapat dengan mudah menghasilkan jawaban yang salah, sementara LLaVA-o1 memastikan keluaran yang lebih akurat melalui penalaran multi-langkah yang terstruktur.
Misalnya, saat menyelesaikan soal "Berapa banyak benda yang tersisa setelah mengurangkan semua bola kecil terang dan benda ungu?", LLaVA-o1 pertama-tama akan merangkum soal, lalu mengekstrak informasi dari gambar, lalu melakukan penalaran langkah demi langkah , dan akhirnya memberikan Jawaban. Pendekatan bertahap ini meningkatkan kemampuan penalaran sistematis model, sehingga lebih efisien dalam menangani masalah yang kompleks.

Perlu disebutkan bahwa LLaVA-o1 memperkenalkan metode pencarian berkas tingkat tahapan dalam proses inferensi. Pendekatan ini memungkinkan model untuk menghasilkan beberapa kandidat jawaban pada setiap tahap inferensi dan memilih jawaban terbaik untuk melanjutkan ke tahap inferensi berikutnya, sehingga secara signifikan meningkatkan kualitas inferensi secara keseluruhan. Dengan penyesuaian yang diawasi dan data pelatihan yang masuk akal, LLaVA-o1 berkinerja baik dibandingkan dengan model yang lebih besar atau sumber tertutup.
Hasil penelitian tim Universitas Peking tidak hanya mendorong pengembangan AI multi-modal, tetapi juga memberikan ide dan metode baru untuk model pemahaman bahasa visual di masa depan. Tim menyatakan bahwa kode, bobot pra-pelatihan, dan kumpulan data LLaVA-o1 akan sepenuhnya open source, dan mereka berharap lebih banyak peneliti dan pengembang bersama-sama mengeksplorasi dan menerapkan model inovatif ini.
Makalah: https://arxiv.org/abs/2411.10440
GitHub: https://github.com/PKU-YuanGroup/LLaVA-o1
Sumber terbuka LLaVA-o1 tidak diragukan lagi akan mendorong pengembangan teknologi dan inovasi aplikasi di bidang AI multi-modal. Mekanisme inferensi yang efisien dan kinerja yang sangat baik menjadikannya referensi penting untuk penelitian model bahasa visual di masa depan dan layak untuk diperhatikan dan diantisipasi. Kami menantikan lebih banyak pengembang yang berpartisipasi dan bersama-sama mempromosikan kemajuan teknologi kecerdasan buatan.