Penasaran dengan teknologi di balik produk AI seperti ChatGPT dan Wenxinyiyan? Semuanya mengandalkan model bahasa besar (LLM). Editor Downcodes akan membawa Anda memahami prinsip pengoperasian LLM dengan cara yang sederhana dan mudah dipahami Bahkan jika Anda hanya memiliki level matematika kelas dua, Anda dapat dengan mudah memahaminya! Kami akan mulai dari konsep dasar jaringan saraf dan secara bertahap menjelaskan pelatihan model, teknik lanjutan, dan teknologi inti seperti arsitektur GPT dan Transformer, sehingga Anda memiliki pemahaman yang jelas tentang LLM.
Pernahkah Anda mendengar tentang AI tingkat lanjut seperti ChatGPT dan Wen Xinyiyan? Teknologi inti di baliknya adalah "model bahasa besar" (LLM). Apakah Anda merasa rumit dan sulit untuk memahaminya? Jangan khawatir, meskipun Anda hanya memiliki tingkat matematika kelas dua, Anda dapat dengan mudah memahami prinsip pengoperasian LLM setelah membaca artikel ini!
Jaringan Neural: Keajaiban Angka
Pertama, perlu kita ketahui bahwa jaringan saraf itu seperti superkomputer, hanya dapat memproses angka. Input dan output harus berupa angka. Jadi bagaimana kita membuatnya memahami teks?
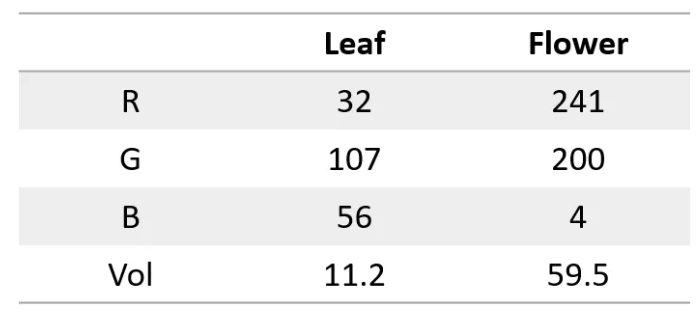
Rahasianya adalah mengubah kata menjadi angka! Misalnya, kita bisa merepresentasikan setiap huruf dengan angka, seperti a=1, b=2, dan seterusnya. Dengan cara ini, jaringan saraf dapat “membaca” teks.
Melatih model: Biarkan jaringan “belajar” bahasa
Dengan teks digital, langkah berikutnya adalah melatih model dan membiarkan jaringan saraf “mempelajari” aturan bahasa.
Proses latihannya seperti bermain tebak-tebakan. Kami menunjukkan kepada jaringan beberapa teks, seperti "Humpty Dumpty," dan memintanya menebak huruf apa berikutnya. Jika tebakannya benar, kami beri hadiah; jika tebakannya salah, kami beri penalti. Dengan terus-menerus menebak dan menyesuaikan, jaringan dapat memprediksi huruf berikutnya dengan semakin akurat, yang pada akhirnya menghasilkan kalimat lengkap seperti "Humpty Dumpty duduk di dinding".
Teknik lanjutan: Jadikan model lebih "pintar"
Untuk membuat model lebih “pintar”, para peneliti telah menemukan banyak teknik canggih, seperti:
Penyematan kata: Daripada menggunakan angka sederhana untuk mewakili huruf, kami menggunakan sekumpulan angka (vektor) untuk mewakili setiap kata, yang dapat mendeskripsikan arti kata secara lebih lengkap.
Segmenter subkata: Membagi kata menjadi unit yang lebih kecil (subkata), seperti membagi "kucing" menjadi "kucing" dan "s", yang dapat mengurangi kosa kata dan meningkatkan efisiensi.
Mekanisme perhatian diri: Saat model memprediksi kata berikutnya, model akan menyesuaikan bobot prediksi berdasarkan semua kata dalam konteksnya, sama seperti kita memahami arti kata berdasarkan konteks saat membaca.
Koneksi sisa: Untuk menghindari kesulitan pelatihan yang disebabkan oleh terlalu banyak lapisan jaringan, peneliti menemukan koneksi sisa untuk membuat jaringan lebih mudah dipelajari.
Mekanisme perhatian multi-kepala: Dengan menjalankan beberapa mekanisme perhatian secara paralel, model dapat memahami konteks dari perspektif berbeda dan meningkatkan akurasi prediksi.
Pengkodean posisi: Agar model dapat memahami urutan kata, peneliti akan menambahkan informasi posisi ke penyematan kata, sama seperti kita memperhatikan urutan kata saat membaca.
Arsitektur GPT: “cetak biru” untuk model bahasa berskala besar
Arsitektur GPT adalah salah satu arsitektur model bahasa berskala besar yang paling populer saat ini. Ini seperti "cetak biru" yang memandu desain dan pelatihan model. Arsitektur GPT secara cerdik menggabungkan teknik-teknik canggih yang disebutkan di atas untuk memungkinkan model mempelajari dan menghasilkan bahasa secara efisien.
Arsitektur Transformer: “Revolusi” model bahasa
Arsitektur Transformer merupakan terobosan besar dalam bidang model bahasa dalam beberapa tahun terakhir. Arsitektur Transformer tidak hanya meningkatkan keakuratan prediksi, namun juga mengurangi kesulitan pelatihan, meletakkan dasar bagi pengembangan model bahasa skala besar. Arsitektur GPT juga berkembang berdasarkan arsitektur Transformer.
Referensi: https://towardsdatascience.com/understanding-llms-from-scratch-using-middle-school-math-e602d27ec876
Saya harap penjelasan editor Downcodes dapat membantu Anda memahami prinsip pengoperasian model bahasa besar. Tentu saja teknologi LLM masih berkembang. Artikel ini hanyalah puncak gunung es. Konten yang semakin mendalam mengharuskan Anda untuk terus belajar dan menjelajah!