Editor Downcodes mengetahui bahwa Meta baru-baru ini merilis perintah dialog multi-putaran multi-bahasa baru setelah tes tolok ukur penilaian kemampuan Multi-IF. Tolok ukur tersebut mencakup delapan bahasa dan berisi 4501 tugas dialog tiga putaran, yang bertujuan untuk mengevaluasi skala besar secara lebih komprehensif model bahasa. (LLM) kinerja dalam aplikasi praktis. Tidak seperti standar evaluasi yang ada yang terutama berfokus pada dialog satu putaran dan tugas satu bahasa, Multi-IF berfokus pada pemeriksaan kemampuan model dalam skenario multi-putaran dan multi-bahasa yang kompleks, sehingga memberikan arah yang lebih jelas untuk peningkatan LLM.
Meta baru-baru ini merilis tes benchmark baru yang disebut Multi-IF, yang dirancang untuk mengevaluasi instruksi berikut kemampuan model bahasa besar (LLM) dalam percakapan multi-turn dan lingkungan multi-bahasa. Tolok ukur ini mencakup delapan bahasa dan berisi 4501 tugas dialog tiga putaran, dengan fokus pada performa model saat ini dalam skenario multi-putaran dan multi-bahasa yang kompleks.
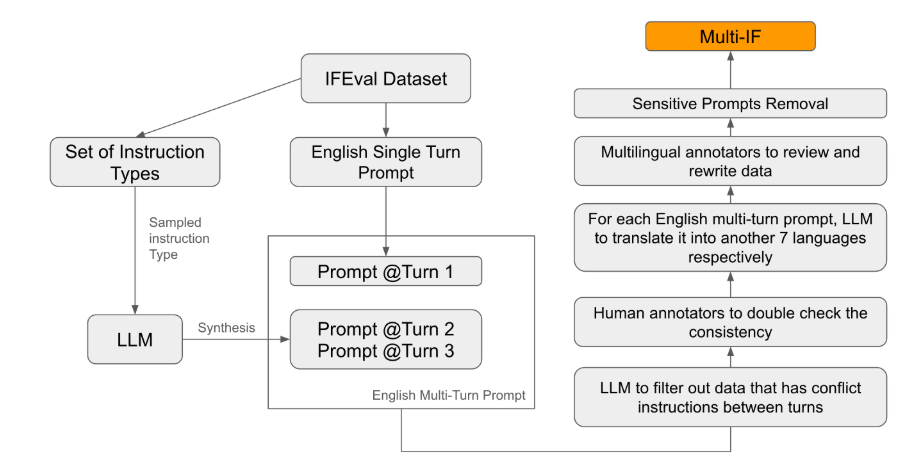
Di antara standar evaluasi yang ada, sebagian besar berfokus pada dialog satu putaran dan tugas satu bahasa, yang sulit untuk sepenuhnya mencerminkan kinerja model dalam aplikasi praktis. Peluncuran Multi-IF bertujuan untuk mengisi kesenjangan ini. Tim peneliti menghasilkan skenario dialog yang kompleks dengan memperluas satu putaran instruksi menjadi beberapa putaran instruksi, dan memastikan bahwa setiap putaran instruksi koheren dan progresif. Selain itu, kumpulan data juga mencapai dukungan multi-bahasa melalui langkah-langkah seperti terjemahan otomatis dan pengoreksian manual.
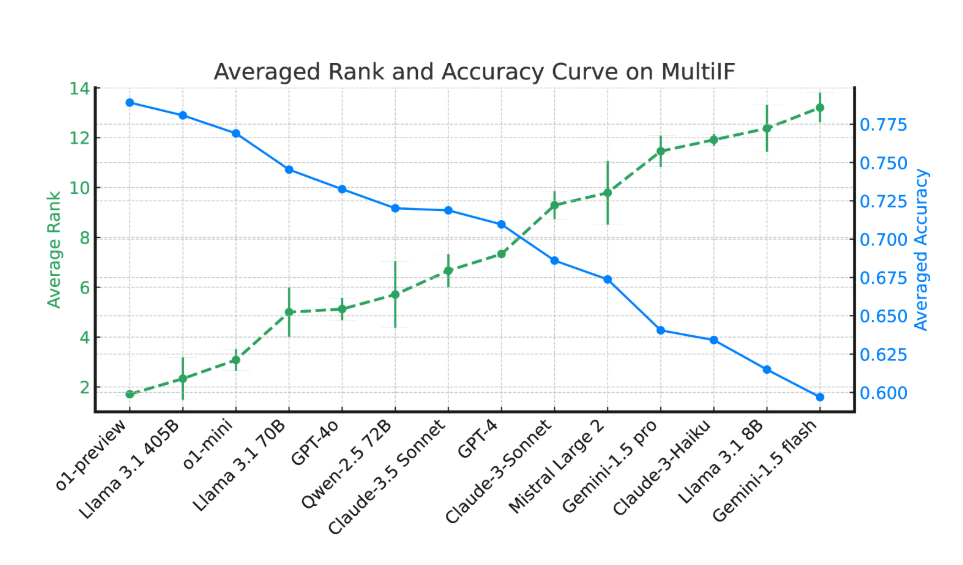
Hasil percobaan menunjukkan bahwa kinerja sebagian besar LLM turun secara signifikan selama beberapa putaran dialog. Mengambil model pratinjau o1 sebagai contoh, akurasi rata-ratanya pada putaran pertama adalah 87,7%, namun turun menjadi 70,7% pada putaran ketiga. Khususnya dalam bahasa dengan skrip non-Latin, seperti Hindi, Rusia, dan China, performa model umumnya lebih rendah dibandingkan bahasa Inggris, sehingga menunjukkan keterbatasan dalam tugas multibahasa.
Dalam evaluasi 14 model bahasa mutakhir, o1-preview dan Llama3.1405B memiliki kinerja terbaik, dengan tingkat akurasi rata-rata masing-masing 78,9% dan 78,1% dalam tiga putaran instruksi. Namun, dalam beberapa putaran dialog, semua model menunjukkan penurunan umum dalam kemampuan mereka untuk mengikuti instruksi, yang mencerminkan tantangan yang dihadapi oleh model dalam tugas-tugas kompleks. Tim peneliti juga memperkenalkan "Instruction Forgetting Rate" (IFR) untuk mengukur fenomena lupa instruksi model dalam beberapa putaran dialog. Hasilnya menunjukkan bahwa model berkinerja tinggi memiliki kinerja yang relatif baik dalam hal ini.
Peluncuran Multi-IF memberikan para peneliti tolok ukur yang menantang dan mendorong pengembangan LLM dalam globalisasi dan aplikasi multibahasa. Peluncuran benchmark ini tidak hanya mengungkap kekurangan model saat ini dalam tugas multi-putaran dan multi-bahasa, namun juga memberikan arah yang jelas untuk perbaikan di masa depan.
Makalah: https://arxiv.org/html/2410.15553v2
Peluncuran tes benchmark Multi-IF memberikan referensi penting untuk penelitian model bahasa besar dalam dialog multi-putaran dan pemrosesan multi-bahasa, dan juga menunjukkan jalan untuk perbaikan model di masa depan. Diharapkan LLM yang lebih kuat akan muncul di masa depan untuk mengatasi tantangan tugas-tugas multi-bahasa yang kompleks dengan lebih baik.