Model inferensi Marco-o1 yang baru-baru ini dirilis oleh Tim AI Internasional Alibaba berfokus pada penyelesaian masalah terbuka, menerobos keterbatasan model tradisional yang terbatas pada bidang jawaban standar, dan menunjukkan potensinya dalam menangani tugas-tugas yang kompleks dan sulit diukur. . Editor Downcodes akan memberi Anda pemahaman mendalam tentang karakteristik, aplikasi dan penggunaan model ini, serta inovasi yang dibawanya ke bidang kecerdasan buatan.
Tim AI Internasional Alibaba baru-baru ini merilis model penalaran baru yang disebut Marco-o1, yang memberikan perhatian khusus pada solusi masalah terbuka dan tidak terbatas pada mata pelajaran dengan jawaban standar, seperti pemrograman dan matematika. Tim peneliti berkomitmen untuk mengeksplorasi apakah model-model tersebut dapat digeneralisasikan secara efektif ke bidang-bidang yang sulit diukur dan tidak memiliki manfaat yang jelas.
Karakteristik model Marco-o1 mencakup penggunaan data CoT yang sangat panjang untuk penyesuaian, penggunaan MCTS untuk memperluas ruang solusi, dan perluasan ruang solusi yang terperinci. Model ini menggunakan self-play+MCTS untuk menyusun kumpulan data CoT yang sangat panjang dengan kemampuan untuk merefleksikan dan mengoreksi, serta dilatih bersama dengan data sumber terbuka lainnya. Selain itu, tim peneliti juga mendefinisikan mini-Step untuk memperluas ruang solusi model dan memandu model untuk menghasilkan jawaban yang lebih baik.
Dalam tugas penerjemahan, model Marco-o1 menunjukkan kemampuannya dalam menangani terjemahan kalimat yang panjang dan sulit. Ini adalah pertama kalinya perpanjangan waktu inferensi diterapkan pada tugas terjemahan mesin. Tim peneliti telah melakukan open source terhadap beberapa data CoT dan model terbaik saat ini, dan berencana untuk melakukan open source lebih banyak data dan model di masa mendatang.
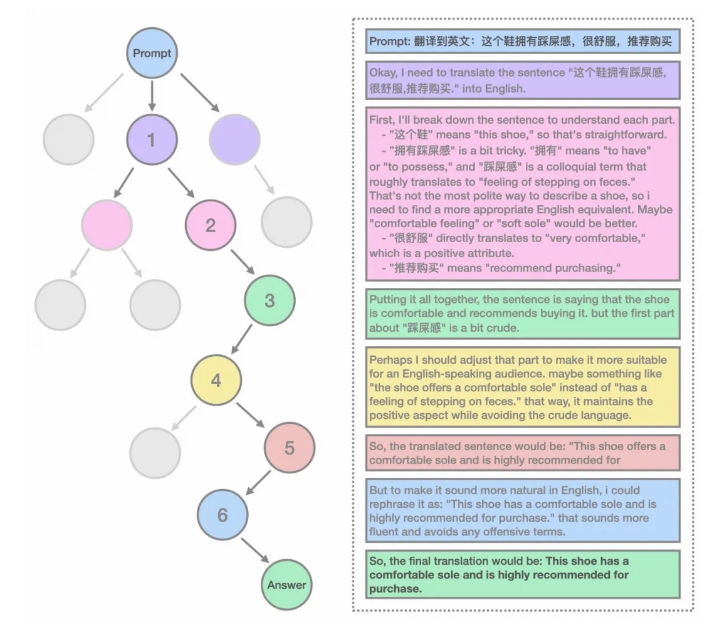
Model akan memikirkan respon secara mendalam ketika melakukan penalaran. Misalnya, ketika mengeluarkan angka 'r pada kata 'strawberry', model akan secara bertahap membongkar setiap huruf dalam kata tersebut dan membandingkannya, dan akhirnya mengeluarkan hasilnya dengan benar. Di bidang terjemahan mesin, model ini dengan tepat mengidentifikasi titik-titik sulit melalui tautan inferensi dan menerjemahkannya kata demi kata, sehingga meningkatkan akurasi terjemahan secara keseluruhan.
Tim peneliti juga telah mencobanya di bidang lain, membuktikan kemampuan model untuk memecahkan masalah umum dunia nyata lainnya. Struktur keseluruhan Marco-o1 menggunakan self-play+MCTS untuk membangun kumpulan data CoT yang sangat panjang dengan kemampuan untuk merefleksikan dan mengoreksi, serta melatihnya bersama dengan data sumber terbuka lainnya. Tim peneliti juga memasukkan beberapa kumpulan data kepatuhan instruksi dari keluarga MarcoPolo untuk meningkatkan kemampuan kepatuhan instruksi model.
Dalam hal penggunaan, tim peneliti menyediakan kode inferensi dan kode penyesuaian. Pengguna dapat dengan mudah memuat model dan tokenizer dan mulai mengobrol atau menyempurnakan model. Selain itu, model juga dapat dijalankan langsung pada versi GGUF di ModelScope, sehingga memberikan cara yang lebih cepat untuk merasakannya.
Peluncuran model Marco-o1 menandai langkah penting yang diambil oleh tim AI internasional Alibaba di bidang model inferensi, memberikan ide dan alat baru untuk memecahkan masalah terbuka.
Lingkup Model:
https://modelscope.cn/models/AIDC-AI/Marco-o1
Arxiv:
https://arxiv.org/abs/2411.14405
Github:
https://github.com/AIDC-AI/Marco-o1
Memeluk Wajah:
https://huggingface.co/AIDC-AI/Marco-o1
Model Marco-o1 yang bersifat open source menyediakan sumber daya berharga bagi para peneliti dan pengembang. Di masa depan, diyakini bahwa lebih banyak aplikasi inovatif berdasarkan model ini akan mendorong pengembangan berkelanjutan dari teknologi kecerdasan buatan. Menantikan lebih banyak kasus aplikasi dan hasil penelitian tentang Marco-o1!