Dalam beberapa tahun terakhir, kecerdasan buatan telah mencapai kemajuan yang signifikan di berbagai bidang, namun kemampuan penalaran matematisnya selalu menjadi hambatan. Saat ini, kemunculan tolok ukur baru yang disebut FrontierMath memberikan tolok ukur baru untuk mengevaluasi kemampuan matematis AI. Hal ini mendorong kemampuan penalaran matematis AI ke batas yang belum pernah terjadi sebelumnya dan menimbulkan tantangan berat terhadap model AI yang ada. Editor Downcodes akan membawa Anda untuk memiliki pemahaman mendalam tentang FrontierMath dan melihat bagaimana hal itu menumbangkan pemahaman kita tentang kemampuan matematika AI.
Di dunia kecerdasan buatan yang luas, matematika pernah dianggap sebagai benteng terakhir kecerdasan mesin. Saat ini, tes benchmark baru yang disebut FrontierMath telah muncul, yang mendorong kemampuan penalaran matematis AI ke batas yang belum pernah terjadi sebelumnya.
Epoch AI telah bekerja sama dengan lebih dari 60 pemikir terbaik di dunia matematika untuk bersama-sama menciptakan bidang tantangan AI yang dapat disebut Olimpiade Matematika. Ini bukan hanya ujian teknis, tetapi juga ujian akhir dari kebijaksanaan matematika kecerdasan buatan.
Bayangkan sebuah laboratorium yang dipenuhi ahli matematika terkemuka dunia, yang telah menciptakan ratusan teka-teki matematika yang melebihi imajinasi orang awam. Masalah-masalah ini mencakup bidang matematika paling mutakhir seperti teori bilangan, analisis real, geometri aljabar, dan teori kategori, dan memiliki kompleksitas yang mencengangkan. Bahkan seorang jenius matematika dengan medali emas Olimpiade Matematika Internasional membutuhkan waktu berjam-jam atau bahkan berhari-hari untuk menyelesaikan suatu masalah.
Yang mengejutkan, model AI tercanggih saat ini memiliki kinerja yang mengecewakan pada benchmark ini: tidak ada model yang mampu menyelesaikan lebih dari 2% masalah. Hasil ini seperti panggilan untuk membangunkan dan menampar wajah AI.
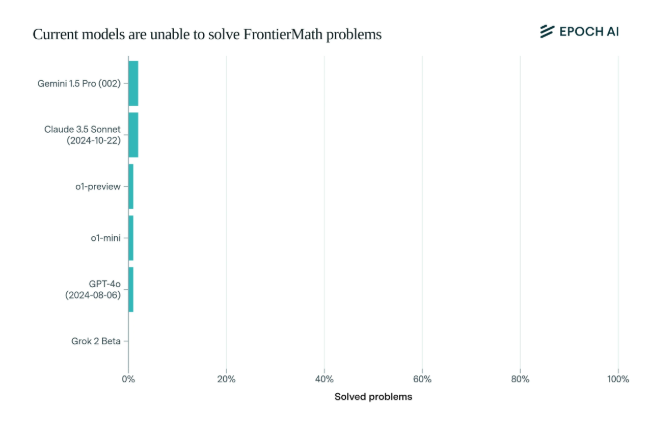
Apa yang membuat FrontierMath unik adalah mekanisme evaluasinya yang ketat. Tolok ukur tes matematika tradisional seperti MATH dan GSM8K telah dimaksimalkan oleh AI, dan tolok ukur baru ini menggunakan pertanyaan baru yang belum dipublikasikan serta sistem verifikasi otomatis untuk secara efektif menghindari polusi data dan benar-benar menguji kemampuan penalaran matematis AI.
Model andalan perusahaan AI terkemuka seperti OpenAI, Anthropic, dan Google DeepMind, yang telah menarik banyak perhatian, secara kolektif dibatalkan dalam pengujian ini. Hal ini mencerminkan filosofi teknis yang mendalam: Bagi komputer, permasalahan matematika yang tampaknya rumit mungkin mudah dilakukan, namun tugas yang dianggap sederhana oleh manusia dapat membuat AI tidak berdaya.
Seperti yang dikatakan Andrej Karpathy, hal ini menegaskan paradoks Moravec: kesulitan tugas cerdas antara manusia dan mesin seringkali berlawanan dengan intuisi. Uji benchmark ini tidak hanya merupakan pemeriksaan ketat terhadap kemampuan AI, namun juga merupakan katalis bagi evolusi AI ke dimensi yang lebih tinggi.
Bagi komunitas matematika dan peneliti AI, FrontierMath bagaikan Gunung Everest yang belum pernah ditaklukkan. Tidak hanya menguji pengetahuan dan keterampilan, tetapi juga menguji wawasan dan berpikir kreatif. Di masa depan, siapa pun yang mampu memimpin pendakian puncak kecerdasan ini akan tercatat dalam sejarah perkembangan kecerdasan buatan.
Munculnya tes benchmark FrontierMath tidak hanya merupakan ujian berat terhadap tingkat teknologi AI yang ada, tetapi juga menunjukkan arah pengembangan AI di masa depan. Hal ini menunjukkan bahwa jalan AI masih panjang di bidang penalaran matematika, dan hal ini juga merangsang penelitian. Para peneliti terus mengeksplorasi dan berinovasi untuk menerobos hambatan teknologi yang ada.