Editor Downcodes membawakan Anda berita besar! Ada anggota baru di bidang kecerdasan buatan - Zyphra secara resmi merilis model bahasa kecilnya Zamba2-7B! Model dengan 7 miliar parameter ini telah mencapai terobosan dalam kinerja, terutama dalam hal efisiensi dan kemampuan beradaptasi, serta menunjukkan keunggulan yang mengesankan. Ini tidak hanya cocok untuk lingkungan komputasi berkinerja tinggi, namun yang lebih penting, Zamba2-7B juga dapat berjalan pada GPU tingkat konsumen, memungkinkan lebih banyak pengguna untuk dengan mudah merasakan pesona teknologi AI yang canggih. Artikel ini akan mempelajari inovasi Zamba2-7B dan dampaknya terhadap bidang pemrosesan bahasa alami.
Baru-baru ini Zyphra secara resmi meluncurkan Zamba2-7B, model bahasa kecil dengan kinerja yang belum pernah terjadi sebelumnya, dengan jumlah parameter mencapai 7B.
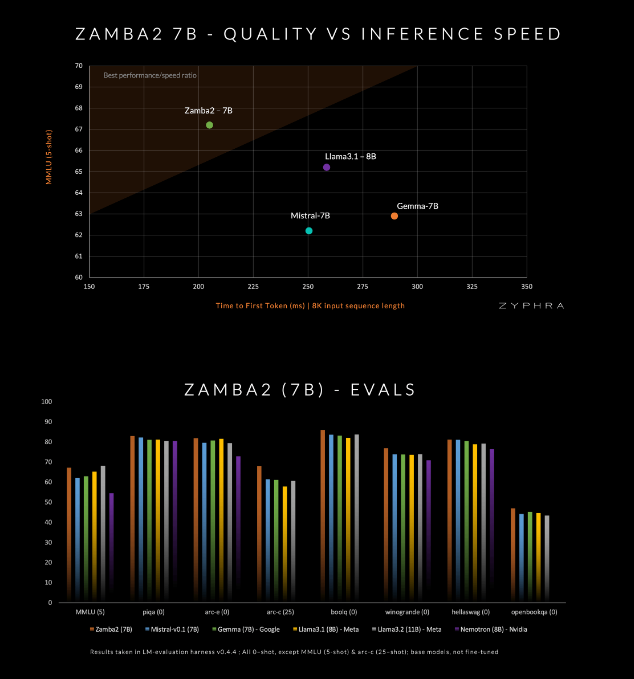
Model ini mengklaim mengungguli pesaing saat ini dalam kualitas dan kecepatan, termasuk Mistral-7B, Gemma-7B Google, dan Llama3-8B Meta.
Zamba2-7B dirancang untuk memenuhi kebutuhan lingkungan yang memerlukan kemampuan pemrosesan bahasa yang kuat namun dibatasi oleh kondisi perangkat keras, seperti pemrosesan pada perangkat atau menggunakan GPU tingkat konsumen. Dengan meningkatkan efisiensi tanpa mengorbankan kualitas, Zyphra berharap dapat memungkinkan lebih banyak pengguna, baik perusahaan maupun pengembang individu, untuk menikmati kenyamanan AI yang canggih.
Zamba2-7B telah membuat banyak inovasi dalam arsitekturnya untuk meningkatkan efisiensi dan kemampuan ekspresi model. Berbeda dari model Zamba1 generasi sebelumnya, Zamba2-7B menggunakan dua blok perhatian bersama. Desain ini dapat menangani ketergantungan antara aliran informasi dan urutan dengan lebih baik.
Blok Mamba2 membentuk inti dari keseluruhan arsitektur, yang membuat pemanfaatan parameter model lebih tinggi dibandingkan model konverter tradisional. Selain itu, Zyphra juga menggunakan proyeksi adaptasi peringkat rendah (LoRA) pada blok MLP bersama, yang selanjutnya meningkatkan kemampuan adaptasi setiap lapisan sekaligus menjaga kekompakan model. Berkat inovasi ini, waktu respons pertama Zamba2-7B telah berkurang sebesar 25%, dan jumlah token yang diproses per detik meningkat sebesar 20%.
Efisiensi dan kemampuan beradaptasi Zamba2-7B telah diverifikasi melalui pengujian yang ketat. Model ini telah dilatih sebelumnya pada kumpulan data besar yang berisi tiga triliun token, yang merupakan data terbuka berkualitas tinggi dan disaring secara ketat.
Selain itu, Zyphra juga memperkenalkan tahap pra-pelatihan "anil" yang dengan cepat mengurangi kecepatan pembelajaran untuk memproses token berkualitas tinggi dengan lebih efisien. Strategi ini memungkinkan Zamba2-7B berkinerja baik dalam benchmark, mengungguli pesaing dalam kecepatan dan kualitas inferensi, dan cocok untuk tugas-tugas seperti pemahaman dan pembuatan bahasa alami tanpa memerlukan sumber daya komputasi besar-besaran yang dibutuhkan oleh model tradisional berkualitas tinggi.
amba2-7B mewakili kemajuan besar dalam model bahasa kecil, mempertahankan kualitas dan kinerja tinggi sambil memberikan perhatian khusus pada aksesibilitas. Melalui desain arsitektur inovatif dan teknologi pelatihan yang efisien, Zyphra berhasil menciptakan model yang tidak hanya mudah digunakan, tetapi juga dapat memenuhi berbagai kebutuhan pemrosesan bahasa alami. Rilis open source Zamba2-7B mengundang para peneliti, pengembang, dan bisnis untuk mengeksplorasi potensinya dan diharapkan dapat memajukan pengembangan pemrosesan bahasa alami tingkat lanjut dalam komunitas yang lebih luas.
Pintu masuk proyek: https://www.zyphra.com/post/zamba2-7b
https://github.com/Zyphra/transformers_zamba2
Rilis open source Zamba2-7B telah membawa vitalitas baru ke bidang pemrosesan bahasa alami dan memberikan lebih banyak kemungkinan bagi pengembang. Kami berharap Zamba2-7B dapat digunakan secara lebih luas di masa depan dan mendorong kemajuan teknologi kecerdasan buatan yang berkelanjutan!