Editor Downcodes mengetahui bahwa para ilmuwan dari Meta, Universitas California, Berkeley, dan Universitas New York bersama-sama mengembangkan teknologi baru yang disebut "Thinking Preference Optimization" (TPO), yang bertujuan untuk meningkatkan kinerja model bahasa besar (LLM). Teknologi ini meningkatkan kemampuan "berpikir" AI dengan memungkinkan model menghasilkan serangkaian langkah berpikir sebelum menjawab pertanyaan, dan menggunakan model evaluasi untuk mengoptimalkan kualitas jawaban akhir, sehingga memungkinkannya bekerja lebih baik dalam berbagai tugas. Berbeda dari teknologi "pemikiran berantai" tradisional, TPO memiliki penerapan yang lebih luas, terutama menunjukkan keunggulan signifikan dalam penulisan kreatif, penalaran akal sehat, dll.
Baru-baru ini, ilmuwan dari Meta, University of California, Berkeley, dan New York University berkolaborasi mengembangkan teknologi baru yang disebut Thought Preference Optimization (TPO). Tujuan dari teknologi ini adalah untuk meningkatkan kinerja model bahasa besar (LLM) ketika melakukan berbagai tugas, sehingga memungkinkan AI untuk mempertimbangkan tanggapannya dengan lebih hati-hati sebelum menjawab.
Para peneliti mengatakan Berpikir harus mempunyai kegunaan yang luas. Misalnya, dalam tugas menulis kreatif, AI dapat menggunakan proses berpikir internal untuk merencanakan keseluruhan struktur dan pengembangan karakter. Metode ini sangat berbeda dengan teknologi penggerak “Chain-of-Thought” (CoT) sebelumnya. Yang terakhir ini terutama digunakan dalam tugas matematika dan logika, sedangkan TPO memiliki cakupan aplikasi yang lebih luas. Para peneliti menyebutkan model o1 baru OpenAI dan percaya bahwa proses berpikir juga berguna untuk berbagai tugas.
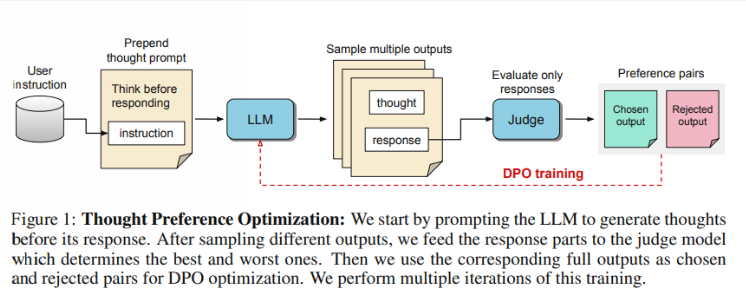
Jadi, bagaimana cara kerja TPO? Pertama, model menghasilkan serangkaian langkah pemikiran sebelum menjawab pertanyaan. Selanjutnya menciptakan banyak keluaran, yang kemudian dievaluasi oleh model evaluasi hanya pada jawaban akhir, bukan langkah pemikiran itu sendiri. Terakhir, model dilatih melalui optimalisasi preferensi hasil evaluasi ini. Peneliti berharap peningkatan kualitas jawaban dapat dicapai melalui perbaikan proses berpikir, sehingga model dapat memperoleh kemampuan penalaran yang lebih efektif dalam pembelajaran implisit.
Dalam pengujian, model Llama38B yang menggunakan TPO memiliki performa lebih baik pada instruksi umum yang mengikuti benchmark dibandingkan versi tanpa inferensi eksplisit. Dalam benchmark AlpacaEval dan Arena-Hard, tingkat kemenangan TPO masing-masing mencapai 52,5% dan 37,3%. Yang lebih menarik lagi adalah TPO juga mengalami kemajuan di bidang-bidang yang biasanya tidak memerlukan pemikiran eksplisit, seperti akal sehat, pemasaran, dan kesehatan.
Namun, tim peneliti mencatat bahwa pengaturan saat ini tidak cocok untuk masalah matematika, karena kinerja TPO sebenarnya lebih buruk daripada model dasar dalam tugas-tugas ini. Hal ini menunjukkan bahwa pendekatan yang berbeda mungkin diperlukan untuk tugas-tugas yang sangat terspesialisasi. Penelitian di masa depan mungkin berfokus pada aspek-aspek seperti pengendalian panjang proses berpikir dan dampak berpikir pada model yang lebih besar.
Menyorot:
Tim peneliti meluncurkan “Thinking Preference Optimization” (TPO) yang bertujuan untuk meningkatkan kemampuan berpikir AI dalam pelaksanaan tugas.
? TPO menggunakan model penilaian untuk mengoptimalkan kualitas jawaban dengan membiarkan model tersebut menghasilkan langkah-langkah pemikiran sebelum menjawab.
Pengujian telah menunjukkan bahwa TPO berkinerja baik di berbagai bidang seperti pengetahuan umum dan pemasaran, tetapi kurang baik dalam tugas matematika.
Secara keseluruhan, teknologi TPO memberikan arah baru untuk peningkatan model bahasa besar, dan potensinya dalam meningkatkan kemampuan berpikir AI patut untuk dinantikan. Namun, teknologi ini juga memiliki keterbatasan, dan penelitian di masa depan perlu lebih meningkatkan dan memperluas cakupan penerapannya. Editor Downcodes akan terus memperhatikan perkembangan terkini di bidang ini dan memberikan laporan yang lebih menarik kepada pembaca.