OpenAI telah merilis model baru gpt-4o-audio-preview yang menarik, yang telah membuat terobosan signifikan dalam bidang pembuatan dan analisis ucapan, memberikan pengalaman interaksi suara yang lebih alami dan cerdas kepada pengguna. Editor Downcodes akan membawa Anda untuk memiliki pemahaman mendalam tentang fungsi inti, skenario aplikasi, dan strategi penetapan harga model ini, serta menganalisis potensi dampaknya terhadap berbagai industri.
OpenAI sekali lagi memimpin tren teknologi kecerdasan buatan dan meluncurkan model pratinjau audio gpt-4o baru. Model ini tidak hanya menunjukkan kemampuan luar biasa dalam menghasilkan dan menganalisis ucapan, namun juga membuka kemungkinan baru untuk interaksi manusia-komputer. Mari kita lihat lebih dekat fitur model inovatif ini dan potensi penerapannya.
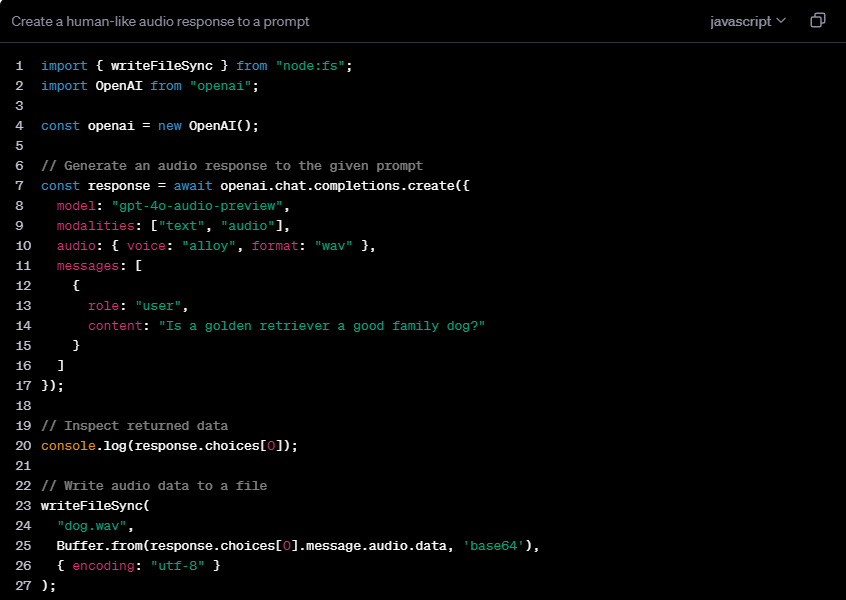
Fungsi inti gpt-4o-audio-preview mencakup tiga aspek utama: Pertama, dapat menghasilkan respons suara yang alami dan halus berdasarkan teks, memberikan dukungan kuat untuk aplikasi seperti asisten suara dan layanan pelanggan virtual. Kedua, model ini memiliki kemampuan menganalisis emosi, intonasi, dan nada masukan audio, yang memiliki prospek penerapan luas di bidang komputasi afektif dan analisis pengalaman pengguna. Terakhir, ia mendukung interaksi suara-ke-suara, di mana audio dapat digunakan sebagai input dan output, sehingga meletakkan dasar bagi berbagai sistem interaksi suara.
Dibandingkan dengan Realtime API OpenAI yang sudah ada, gpt-4o-audio-preview lebih berfokus pada detail pemrosesan ucapan. Ia unggul dalam pembuatan ucapan, analisis sentimen, dan interaksi ucapan, dengan fokus khusus pada pemrosesan fitur halus seperti intonasi dan emosi. Sebaliknya, Realtime API lebih berfokus pada pemrosesan data real-time dan cocok untuk skenario yang memerlukan umpan balik segera, seperti terjemahan ucapan-ke-teks secara real-time atau terjemahan real-time dan aplikasi interaktif berkelanjutan lainnya.
Fleksibilitas gpt-4o-audio-preview tercermin dalam dukungannya untuk kombinasi beberapa mode. Pengguna dapat memilih input teks untuk menghasilkan output teks dan audio, atau menggunakan input audio untuk mendapatkan output teks dan ucapan. Selain itu, ia juga mendukung konversi audio-ke-teks dan mode input campuran, memberikan pengembang pilihan yang kaya.
Dalam hal harga, OpenAI mengadopsi model penagihan berbasis token. Harga untuk input teks relatif rendah sekitar $5 per juta token. Output teks sedikit lebih tinggi sekitar $15 per juta token. Biaya pemrosesan audio relatif tinggi, dengan biaya input $100 per juta token (kira-kira $0,06 per menit), sedangkan output audio mencapai $200 per juta token (kira-kira $0,24 per menit). Strategi penetapan harga ini mencerminkan kompleksitas dan kebutuhan sumber daya komputasi pemrosesan audio.
Peluncuran gpt-4o-audio-preview tidak diragukan lagi akan memberikan dampak transformatif pada banyak industri. Di bidang layanan pelanggan dapat memberikan pengalaman interaksi suara yang lebih natural dan emosional. Dalam industri pendidikan, teknologi ini dapat digunakan untuk mengembangkan asisten pembelajaran bahasa yang cerdas untuk membantu siswa meningkatkan pengucapan dan intonasi mereka. Dalam industri hiburan, hal ini diharapkan dapat mendorong sintesis ucapan dan interaksi karakter virtual yang lebih realistis. Selain itu, dalam hal teknologi bantu, gpt-4o-audio-preview dapat memberikan layanan ucapan-ke-teks yang lebih akurat bagi tuna rungu, atau memberikan deskripsi suara yang lebih kaya bagi tunanetra.
Detailnya: https://platform.openai.com/docs/guides/audio/quickstart
Secara keseluruhan, kemunculan model pratinjau audio gpt-4o menandai babak baru dalam teknologi kecerdasan buatan suara. Fungsinya yang kuat dan prospek penerapannya yang luas akan membawa perubahan revolusioner pada metode interaksi manusia-komputer di masa depan. Editor Downcodes berharap dapat melihat lebih banyak aplikasi inovatif berdasarkan model ini.