Editor Downcodes mengetahui bahwa Alibaba Damo Academy dan Renmin University of China bersama-sama melakukan open source model pemrosesan dokumen yang disebut mPLUG-DocOwl1.5. Model ini dapat memahami konten dokumen tanpa pengenalan OCR dan berkinerja baik dalam beberapa pengujian benchmark. Intinya terletak pada metode "pembelajaran struktur terpadu", yang meningkatkan pemahaman struktural model bahasa besar multi-modal (MLLM) terhadap gambar teks kaya. . Model ini telah merilis kode, model, dan kumpulan data secara publik di GitHub, sehingga menyediakan sumber daya berharga untuk penelitian di bidang terkait.
Alibaba Damo Academy dan Renmin University of China baru-baru ini bersama-sama melakukan open source model pemrosesan dokumen yang disebut mPLUG-DocOwl1.5. Model ini berfokus pada pemahaman konten dokumen tanpa pengenalan OCR, dan telah mencapai hasil dalam beberapa tes tolok ukur pemahaman dokumen visual yang unggul.
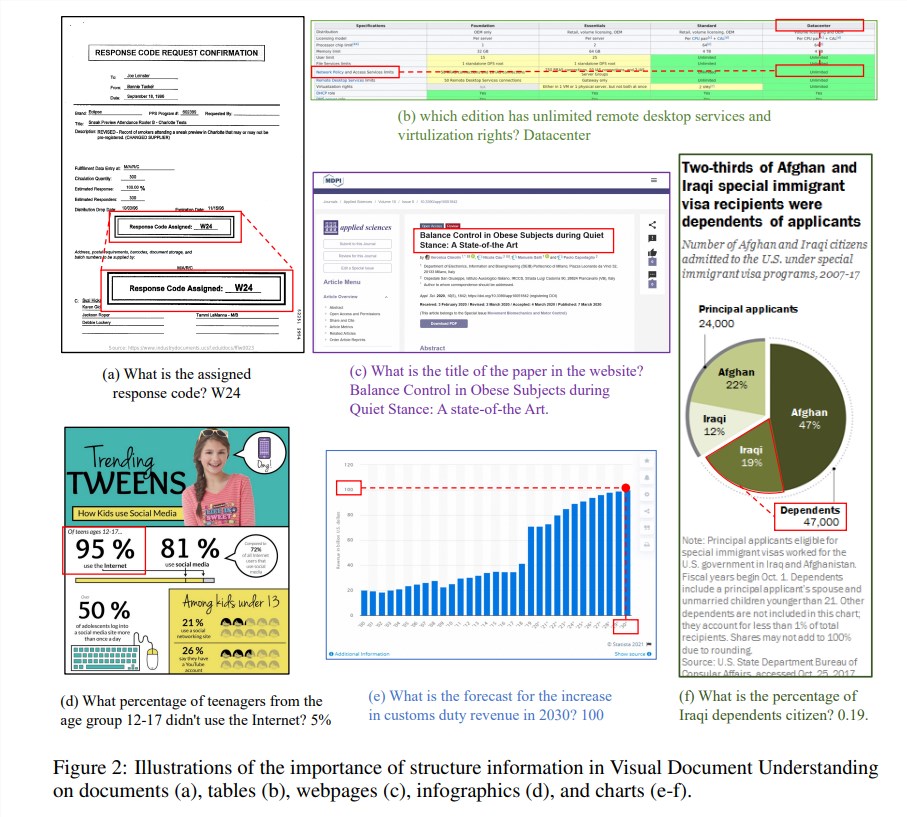
Informasi struktural sangat penting untuk memahami semantik gambar kaya teks seperti dokumen, tabel, dan bagan. Meskipun model bahasa besar multimodal (MLLM) yang ada memiliki kemampuan pengenalan teks, model tersebut tidak memiliki kemampuan untuk memahami struktur umum gambar dokumen teks kaya. Untuk mengatasi masalah ini, mPLUG-DocOwl1.5 menekankan pentingnya informasi struktural dalam pemahaman dokumen visual, dan mengusulkan "pembelajaran struktur terpadu" untuk meningkatkan kinerja MLLM.
"Pembelajaran struktur terpadu" model ini mencakup 5 area: dokumen, halaman web, tabel, bagan, dan gambar alami, termasuk tugas penguraian sadar struktur dan tugas pemosisian teks multi-perincian. Untuk menyandikan informasi struktural dengan lebih baik, para peneliti merancang modul visual-ke-teks yang sederhana dan efektif H-Reducer, yang tidak hanya menyimpan informasi tata letak, namun juga mengurangi panjang fitur visual dengan menggabungkan patch gambar yang berdekatan secara horizontal melalui konvolusi, Aktifkan model bahasa besar untuk memahami gambar resolusi tinggi dengan lebih efisien.
Selain itu, untuk mendukung pembelajaran struktur, tim peneliti membangun DocStruct4M, satu set pelatihan komprehensif yang berisi 4 juta sampel berdasarkan kumpulan data yang tersedia untuk umum, yang berisi urutan teks sadar struktur dan pasangan kotak pembatas teks multi-perincian. Untuk lebih merangsang kemampuan penalaran MLLM di bidang dokumen, mereka juga membuat kumpulan data penyempurnaan penalaran DocReason25K yang berisi 25.000 sampel berkualitas tinggi.
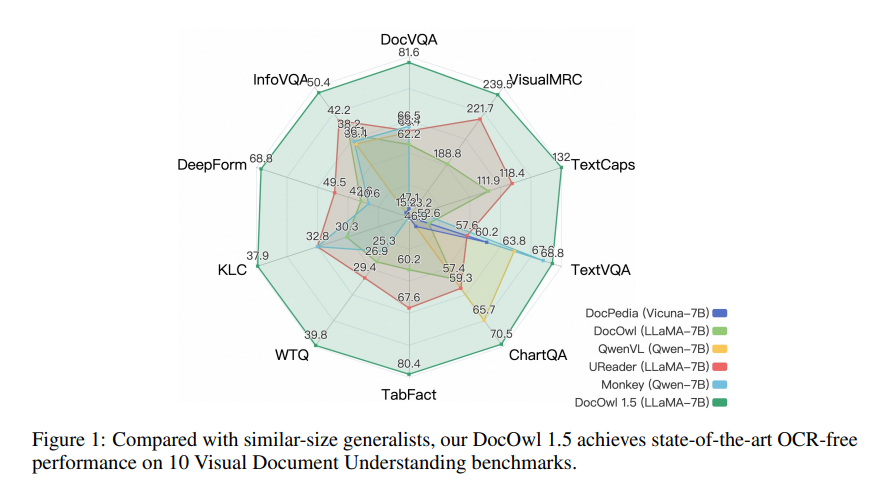
mPLUG-DocOwl1.5 mengadopsi kerangka pelatihan dua tahap, yang pertama melakukan pembelajaran struktur terpadu dan kemudian melakukan penyesuaian multi-tugas di beberapa tugas hilir. Melalui metode pelatihan ini, mPLUG-DocOwl1.5 mencapai kinerja canggih dalam 10 tolok ukur pemahaman dokumen visual, meningkatkan kinerja SOTA 7B LLM lebih dari 10 poin persentase dalam 5 tolok ukur.
Saat ini, kode, model, dan kumpulan data mPLUG-DocOwl1.5 telah dirilis ke publik di GitHub.
Alamat proyek: https://github.com/X-PLUG/mPLUG-DocOwl/tree/main/DocOwl1.5
Alamat makalah: https://arxiv.org/pdf/2403.12895
Sumber terbuka mPLUG-DocOwl1.5 menghadirkan kemungkinan baru pada penelitian dan penerapan di bidang pemahaman dokumen visual. Kinerjanya yang efisien dan metode akses yang mudah patut mendapat perhatian dan penggunaan pengembang. Diharapkan model ini dapat digunakan dalam skenario yang lebih praktis di masa depan.