Editor Downcodes akan mengajak Anda mempelajari hasil penelitian terbaru dari Institut Teknologi Federal Swiss di Lausanne (EPFL)! Studi ini memberikan perbandingan mendalam antara dua metode pelatihan adaptif utama untuk model bahasa besar (LLM): pembelajaran kontekstual (ICL) dan penyempurnaan instruksi (IFT), dan menggunakan tolok ukur MT-Bench untuk mengevaluasi kemampuan model dalam mengikuti instruksi. Hasil penelitian menunjukkan bahwa kedua metode tersebut memiliki kelebihannya masing-masing dalam skenario yang berbeda, memberikan referensi berharga untuk pemilihan metode pelatihan LLM.
Sebuah studi baru-baru ini dari Ecole Polytechnique Fédérale de Lausanne (EPFL) di Swiss membandingkan dua metode pelatihan adaptif utama untuk model bahasa besar (LLM): pembelajaran kontekstual (ICL) dan penyempurnaan instruksi (IFT). Para peneliti menggunakan benchmark MT-Bench untuk mengevaluasi kemampuan model dalam mengikuti instruksi dan menemukan bahwa kedua metode memiliki kinerja lebih baik dan lebih buruk dalam kondisi tertentu.
Penelitian telah menemukan bahwa ketika jumlah sampel pelatihan yang tersedia sedikit (misalnya, tidak lebih dari 50), pengaruh ICL dan IFT sangat mirip. Hal ini menunjukkan bahwa ICL dapat menjadi alternatif bagi IFT ketika data terbatas.
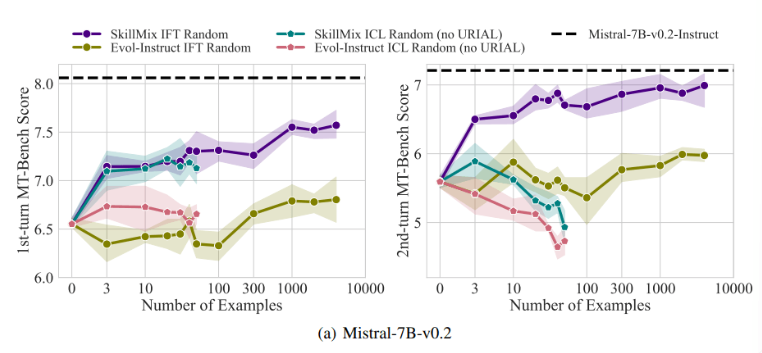
Namun, seiring dengan meningkatnya kompleksitas tugas, misalnya dalam skenario dialog multi-turn, manfaat IFT menjadi jelas. Para peneliti percaya bahwa model ICL cenderung mengalami overfitting dengan gaya sampel tunggal, sehingga menghasilkan performa yang buruk saat menangani percakapan yang kompleks, atau bahkan lebih buruk daripada model dasar.
Studi ini juga menguji metode URIAL, yang hanya menggunakan tiga sampel dan instruksi untuk mengikuti aturan guna melatih model bahasa dasar. Meskipun URIAL telah mencapai hasil tertentu, namun masih terdapat gap dibandingkan dengan model yang dilatih oleh IFT. Peneliti EPFL meningkatkan kinerja URIAL dengan meningkatkan strategi pemilihan sampel, sehingga mendekati model penyempurnaan. Hal ini menyoroti pentingnya data pelatihan berkualitas tinggi untuk ICL, IFT, dan pelatihan model dasar.
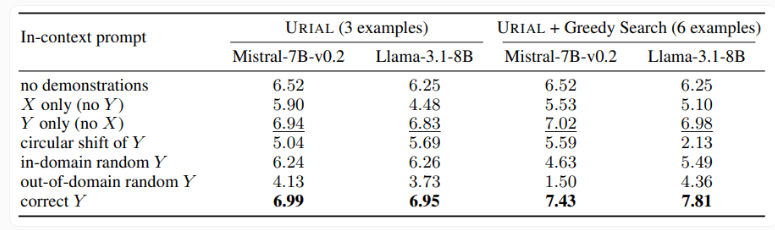
Selain itu, penelitian ini juga menemukan bahwa parameter decoding memiliki dampak signifikan terhadap performa model. Parameter ini menentukan cara model menghasilkan teks dan sangat penting baik untuk LLM dasar maupun model yang dilatih dengan URIAL.
Para peneliti mencatat bahwa bahkan model dasar dapat mengikuti instruksi sampai batas tertentu dengan memberikan parameter decoding yang sesuai.
Pentingnya penelitian ini adalah mengungkapkan bahwa pembelajaran kontekstual dapat menyesuaikan model bahasa dengan cepat dan efisien, terutama ketika sampel pelatihan terbatas. Namun untuk tugas kompleks seperti percakapan multi-turn, penyesuaian perintah masih merupakan pilihan yang lebih baik.
Seiring bertambahnya ukuran kumpulan data, performa IFT akan terus meningkat, sedangkan performa ICL akan stabil setelah mencapai jumlah sampel tertentu. Para peneliti menekankan bahwa pilihan antara ICL dan IFT bergantung pada berbagai faktor, seperti sumber daya yang tersedia, volume data, dan persyaratan aplikasi spesifik. Metode apa pun yang Anda pilih, data pelatihan berkualitas tinggi sangatlah penting.
Secara keseluruhan, studi EPFL ini memberikan wawasan baru mengenai pemilihan metode pelatihan untuk model bahasa besar dan menunjukkan arah penelitian di masa depan. Memilih ICL atau IFT memerlukan pertimbangan pro dan kontra berdasarkan situasi spesifik, dan data berkualitas tinggi selalu menjadi kuncinya. Kami berharap penelitian ini dapat membantu semua orang lebih memahami dan menerapkan model bahasa besar.