Editor Downcodes akan mengajak Anda mempelajari tentang Emu3, model dunia multi-modal terbaru yang dirilis oleh Zhiyuan Research Institute! Emu3 mengandalkan kemampuan unik "prediksi token berikutnya" untuk mencapai pemahaman terobosan dan kemampuan pembangkitan dalam tiga modalitas: teks, gambar, dan video. Ia tidak hanya dapat menghasilkan gambar berkualitas tinggi dan video yang halus dan alami, tetapi juga melakukan pemahaman gambar dan prediksi video yang akurat, kinerjanya melebihi banyak model sumber terbuka yang terkenal. Sifat open source Emu3 juga memberikan vitalitas baru ke dalam pengembangan AI multi-modal. Mari kita jelajahi inovasi teknologi dan potensi masa depan di baliknya.
Zhiyuan Research Institute secara resmi merilis model dunia multi-modal generasi baru Emu3. Sorotan terbesar dari model ini adalah model ini dapat memprediksi token berikutnya dalam tiga mode berbeda: teks, gambar, dan video.

Dalam hal pembuatan gambar, Emu3 mampu menghasilkan gambar berkualitas tinggi berdasarkan prediksi token visual. Ini berarti pengguna dapat mengharapkan resolusi yang fleksibel dan gaya yang beragam.

Dalam hal pembuatan video, Emu3 bekerja dengan cara yang benar-benar baru. Tidak seperti model lain yang menghasilkan video melalui noise, Emu3 secara langsung menghasilkan video melalui prediksi berurutan. Kemajuan teknologi ini membuat pembuatan video menjadi lebih lancar dan alami.

Pada tugas-tugas seperti pembuatan gambar, pembuatan video, dan pemahaman bahasa visual, kinerja Emu3 melebihi banyak model sumber terbuka terkenal, seperti SDXL, LLaVA, dan OpenSora. Di belakangnya terdapat tokenizer visual yang kuat yang dapat mengubah video dan gambar menjadi token terpisah. Desain ini memberikan ide-ide baru untuk pemrosesan teks, gambar, dan video yang terpadu.
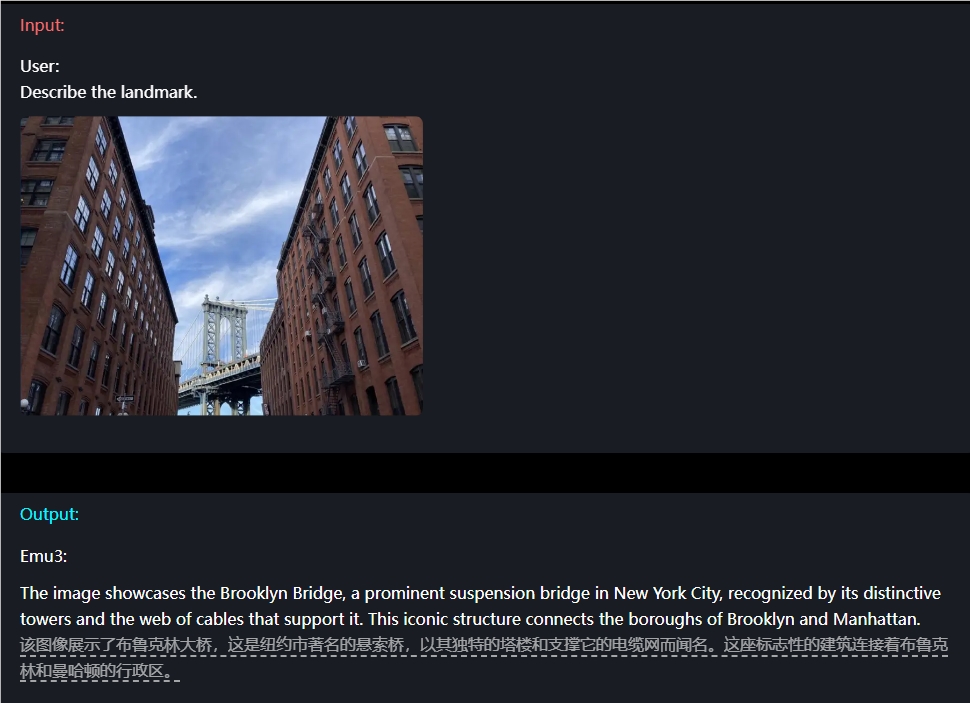
Misalnya saja dalam hal pemahaman gambar, pengguna hanya perlu memasukkan pertanyaan saja, dan Emu3 dapat mendeskripsikan konten gambar secara akurat.
Emu3 juga memiliki kemampuan prediksi video. Ketika diberikan sebuah video, Emu3 dapat memprediksi apa yang akan terjadi selanjutnya berdasarkan konten yang ada. Hal ini memungkinkannya untuk menunjukkan kemampuan yang kuat dalam mensimulasikan lingkungan, perilaku manusia dan hewan, memungkinkan pengguna merasakan pengalaman interaktif yang lebih realistis.

Selain itu, fleksibilitas desain Emu3 menyegarkan. Dapat dioptimasi langsung dengan preferensi manusia sehingga konten yang dihasilkan lebih sesuai dengan ekspektasi pengguna. Selain itu, Emu3, sebagai model sumber terbuka, telah menarik diskusi hangat di komunitas teknis. Banyak orang percaya bahwa pencapaian ini akan sepenuhnya mengubah pola pengembangan AI multi-modal.
URL Proyek: https://emu.baai.ac.cn/about
Makalah: https://arxiv.org/pdf/2409.18869
Menyorot:
Emu3 mewujudkan pemahaman multi-modal dan pembuatan teks, gambar, dan video melalui prediksi token berikutnya.
Dalam berbagai tugas, kinerja Emu3 melampaui banyak model open source terkenal, menunjukkan kemampuannya yang kuat.
Desain fleksibel dan fitur sumber terbuka Emu3 memberikan peluang baru bagi pengembang dan diharapkan dapat mendorong inovasi dan pengembangan AI multi-modal.
Kemunculan Emu3 menandai tonggak baru dalam bidang AI multi-modal. Performanya yang kuat, desain yang fleksibel, dan fitur-fitur open source tidak diragukan lagi akan berdampak besar pada pengembangan AI di masa depan. Kami menantikan Emu3 digunakan di lebih banyak bidang dan menghadirkan lebih banyak kemudahan dan kejutan bagi umat manusia!