Editor Downcodes mengetahui bahwa Institut Penelitian Kecerdasan Buatan Zhiyuan Beijing telah bekerja sama dengan sejumlah universitas untuk meluncurkan model besar untuk pemahaman video ultra-panjang yang disebut Video-XL. Model ini berkinerja baik dalam memproses video berdurasi lebih dari sepuluh menit, mencapai posisi terdepan dalam berbagai tolok ukur, menunjukkan kemampuan generalisasi yang kuat dan efisiensi pemrosesan. Video-XL menggunakan model bahasa untuk mengompresi rangkaian visual yang panjang dan mencapai akurasi hampir 95% dalam tugas-tugas seperti "menemukan jarum di tumpukan jerami". Video-XL hanya memerlukan kartu grafis dengan memori video 80G untuk memproses 2048 frame masukan. Model open source ini akan mendorong kerja sama dan pengembangan komunitas riset pemahaman video multi-modal global.
Institut Penelitian Kecerdasan Buatan Zhiyuan Beijing telah bekerja sama dengan universitas-universitas seperti Universitas Shanghai Jiao Tong, Universitas Renmin Tiongkok, Universitas Peking, dan Universitas Pos dan Telekomunikasi Beijing untuk meluncurkan model pemahaman video ultra-panjang berukuran besar yang disebut Video-XL. Model ini merupakan demonstrasi penting dari kemampuan inti model multi-modal besar dan merupakan langkah penting menuju kecerdasan buatan umum (AGI). Dibandingkan dengan model besar multi-modal yang ada, Video-XL menunjukkan kinerja dan efisiensi yang lebih baik saat memproses video berdurasi lebih dari 10 menit.

Video-XL memanfaatkan kemampuan asli model bahasa (LLM) untuk mengompresi rangkaian visual yang panjang, mempertahankan kemampuan untuk memahami video pendek, dan menunjukkan kemampuan generalisasi yang sangat baik dalam pemahaman video panjang. Model ini menempati peringkat pertama dalam berbagai tugas pada berbagai tolok ukur pemahaman video panjang arus utama. Video-XL mencapai keseimbangan yang baik antara efisiensi dan kinerja. Ia hanya memerlukan kartu grafis dengan memori video 80G untuk memproses input bingkai 2048, mengambil sampel video berdurasi satu jam, dan mencapai hampir 95% dalam tugas video "jarum di tumpukan jerami". % akurasi.
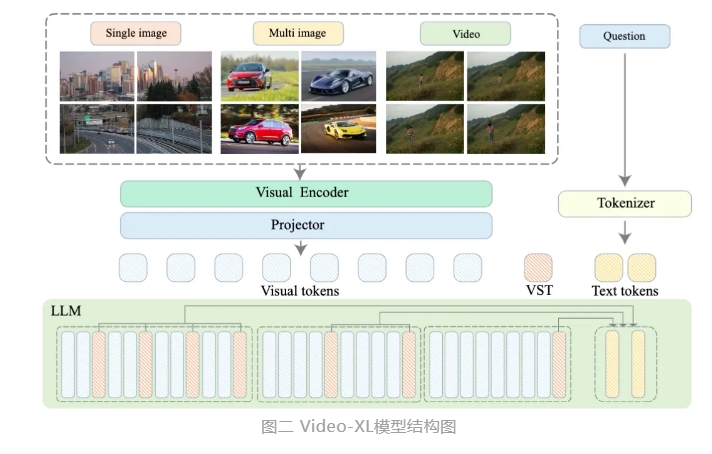
Video-XL diharapkan menunjukkan nilai aplikasi yang luas dalam skenario aplikasi seperti ringkasan film, deteksi anomali video, dan deteksi penempatan iklan, serta menjadi asisten yang ampuh untuk pemahaman video berdurasi panjang. Peluncuran model ini menandai langkah penting dalam efisiensi dan keakuratan teknologi pemahaman video panjang, dan memberikan dukungan teknis yang kuat untuk pemrosesan otomatis dan analisis konten video panjang di masa depan.
Saat ini, kode model Video-XL telah bersumber terbuka untuk mempromosikan kerja sama dan berbagi teknologi dalam komunitas riset pemahaman video multi-modal global.
Judul makalah: Video-XL: Model Bahasa Penglihatan Ekstra Panjang untuk Pemahaman Video Skala Jam
Tautan makalah: https://arxiv.org/abs/2409.14485
Tautan model: https://huggingface.co/sy1998/Video_XL
Tautan proyek: https://github.com/VectorSpaceLab/Video-XL
Video-XL yang bersumber terbuka menghadirkan kemungkinan-kemungkinan baru dalam penelitian dan penerapan di bidang pemahaman video panjang. Efisiensi dan akurasinya akan mendorong pengembangan lebih lanjut teknologi terkait dan memberikan dukungan teknis untuk lebih banyak skenario penerapan di masa depan. Kami berharap dapat melihat lebih banyak aplikasi inovatif berdasarkan Video-XL di masa depan.