Editor Downcodes akan memperkenalkan Anda pada penelitian terbaru dari Universitas Teknik Darmstadt di Jerman. Penelitian ini menggunakan masalah Bongard sebagai alat pengujian untuk mengevaluasi kinerja model gambar AI canggih saat ini dalam tugas penalaran visual sederhana. Hasil penelitian ini mengejutkan. Bahkan keakuratan model multi-modal teratas seperti GPT-4o jauh lebih rendah dari yang diharapkan, sehingga memicu refleksi mendalam terhadap standar evaluasi kemampuan visual AI yang ada.
Penelitian terbaru dari Technical University of Darmstadt di Jerman mengungkap fenomena yang menggugah pikiran: bahkan model gambar AI paling canggih pun bisa membuat kesalahan signifikan saat dihadapkan pada tugas penalaran visual sederhana. Hasil penelitian ini mengedepankan pemikiran baru mengenai standar evaluasi kemampuan visual AI.
Tim peneliti menggunakan masalah Bongard yang dirancang oleh ilmuwan Rusia Michail Bongard sebagai alat pengujian. Teka-teki visual jenis ini terdiri dari 12 gambar sederhana yang dibagi menjadi dua kelompok dan memerlukan identifikasi aturan yang membedakan kedua kelompok tersebut. Tugas penalaran abstrak ini tidak sulit bagi kebanyakan orang, tetapi performa model AI sangat mengejutkan.
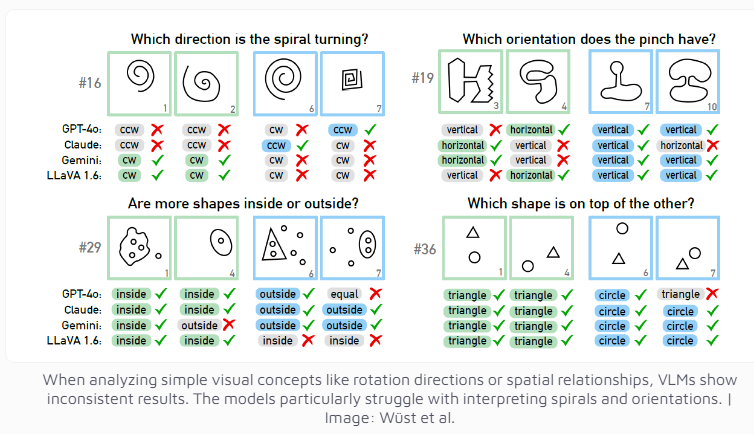
Bahkan model multi-modal GPT-4o, yang saat ini dianggap paling canggih, hanya berhasil memecahkan 21 dari 100 teka-teki visual. Performa model AI ternama lainnya seperti Claude, Gemini, dan LLaVA pun kurang memuaskan. Model-model ini menunjukkan kesulitan yang signifikan dalam mengidentifikasi konsep visual dasar seperti garis vertikal dan horizontal, atau menilai arah spiral.
Para peneliti menemukan bahwa meskipun pilihan ganda diberikan, kinerja model AI hanya meningkat sedikit. Hanya di bawah pembatasan ketat pada jumlah kemungkinan jawaban, GPT-4 dan Claude meningkatkan tingkat keberhasilan masing-masing menjadi 68 dan 69 teka-teki. Melalui analisis mendalam terhadap empat kasus spesifik, tim peneliti menemukan bahwa sistem AI terkadang mengalami masalah pada tingkat persepsi visual dasar sebelum mencapai tahap berpikir dan bernalar, namun alasan spesifiknya masih sulit ditentukan.
Penelitian ini juga memicu refleksi pada kriteria evaluasi sistem AI. Tim peneliti menunjukkan: Mengapa model bahasa visual berkinerja baik pada tolok ukur yang sudah ada, tetapi kesulitan mengatasi masalah Bongard yang tampaknya sederhana? Seberapa berartikah tolok ukur ini dalam menilai kemampuan penalaran dunia nyata? mungkin perlu didesain ulang agar dapat mengukur kemampuan penalaran visual AI secara lebih akurat.
Penelitian ini tidak hanya menunjukkan keterbatasan teknologi AI saat ini, namun juga menunjukkan jalan bagi pengembangan kemampuan visual AI di masa depan. Hal ini mengingatkan kita bahwa meskipun kita mendukung kemajuan pesat AI, kita juga harus menyadari dengan jelas bahwa masih ada ruang untuk peningkatan kemampuan kognitif dasar AI.
Penelitian ini dengan jelas menunjukkan bahwa model AI masih memiliki banyak ruang untuk perbaikan dalam penalaran visual, dan diperlukan metode evaluasi yang lebih efektif serta terobosan teknologi di masa depan untuk meningkatkan kemampuan kognitif AI. Editor Downcodes akan terus memperhatikan kemajuan mutakhir di bidang AI dan memberikan Anda laporan yang lebih menarik.