Editor Downcodes akan membawa Anda mempelajari tentang teknologi inovatif yang meningkatkan efisiensi model bahasa besar (LLM) - Q-Sparse. Kemampuan pemrosesan bahasa alami yang kuat dari LLM telah menarik banyak perhatian, namun biaya komputasi dan jejak memori yang tinggi selalu menjadi hambatan dalam aplikasi praktis. Q-Sparse menggunakan metode sparsifikasi yang cerdas untuk meningkatkan efisiensi inferensi secara signifikan sekaligus memastikan performa model, membuka jalan bagi penerapan LLM secara luas. Artikel ini akan mengeksplorasi secara mendalam teknologi inti, keunggulan, dan hasil verifikasi eksperimental Q-Sparse, yang menunjukkan potensi besarnya dalam meningkatkan efisiensi LLM.
Dalam dunia kecerdasan buatan, model bahasa besar (LLM) dikenal karena kemampuan pemrosesan bahasa alaminya yang unggul. Namun, penerapan model ini dalam aplikasi praktis menghadapi tantangan besar, terutama karena tingginya biaya komputasi dan jejak memori selama tahap inferensi. Untuk mengatasi masalah ini, para peneliti telah mengeksplorasi bagaimana meningkatkan efisiensi LLM. Baru-baru ini, metode yang disebut Q-Sparse telah menarik perhatian luas.
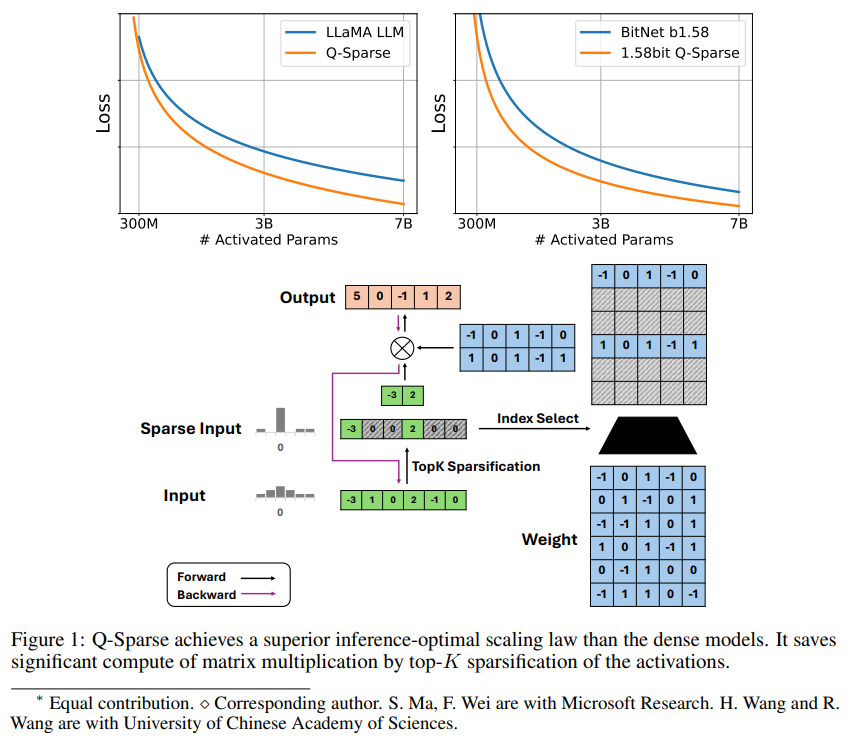
Q-Sparse adalah metode sederhana namun efektif yang mencapai aktivasi LLM yang sepenuhnya jarang dengan menerapkan sparsifikasi top-K dalam aktivasi dan estimator pass-through dalam pelatihan. Ini berarti peningkatan efisiensi yang signifikan saat mengambil kesimpulan. Hasil penelitian utama meliputi:
Q-Sparse mencapai efisiensi inferensi yang lebih tinggi sambil mempertahankan hasil yang sebanding dengan LLM dasar.
Aturan ekspansi optimal inferensial yang cocok untuk LLM aktivasi jarang diusulkan.
Q-Sparse bekerja dalam pengaturan yang berbeda, termasuk pelatihan dari awal, pelatihan lanjutan LLM siap pakai, dan penyesuaian.
Q-Sparse bekerja dengan presisi penuh dan LLM 1-bit (misalnya BitNet b1.58).
Keuntungan dari aktivasi yang jarang
Ketersebaran meningkatkan efisiensi LLM dalam dua cara: pertama, ketersebaran dapat mengurangi jumlah perhitungan perkalian matriks, karena elemen nol tidak akan dihitung, kedua, ketersebaran dapat mengurangi jumlah transmisi input/output (I/O); Ini adalah hambatan utama dalam fase inferensi LLM.
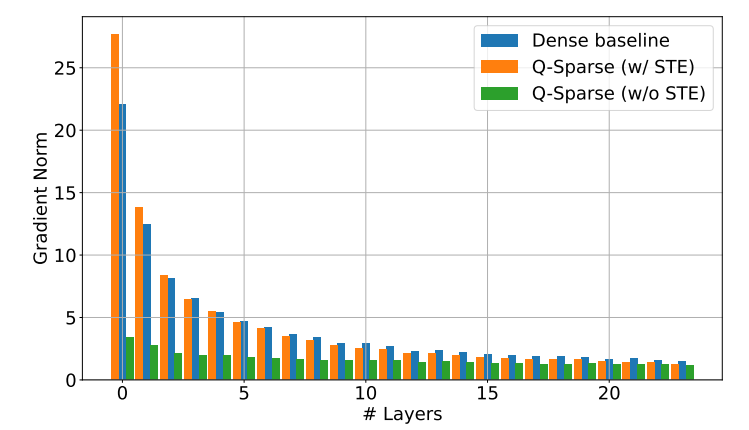
Q-Sparse mencapai ketersebaran aktivasi penuh dengan menerapkan fungsi sparsifikasi top-K di setiap proyeksi linier. Untuk propagasi mundur, gradien aktivasi dihitung menggunakan penaksir pass-through. Selain itu, fungsi ReLU kuadrat diperkenalkan untuk lebih meningkatkan ketersebaran aktivasi.
Verifikasi eksperimental
Para peneliti mempelajari hukum ekspansi LLM yang jarang diaktifkan melalui serangkaian eksperimen ekspansi dan sampai pada beberapa temuan menarik:
Performa model aktivasi renggang meningkat seiring dengan peningkatan ukuran model dan rasio ketersebaran.
Mengingat rasio ketersebaran tetap S, kinerja model aktivasi renggang berskala dengan ukuran model N dengan cara hukum pangkat.
Dengan adanya parameter tetap N, kinerja model aktivasi renggang berskala eksponensial dengan rasio ketersebaran S.
Q-Sparse dapat digunakan tidak hanya untuk pelatihan dari awal, tetapi juga untuk pelatihan lanjutan dan penyempurnaan LLM siap pakai. Dalam pengaturan pelatihan lanjutan dan penyesuaian, para peneliti menggunakan arsitektur dan proses pelatihan yang sama dengan pelatihan dari awal, satu-satunya perbedaan adalah menginisialisasi model dengan bobot yang telah dilatih sebelumnya dan mengaktifkan fungsi renggang untuk melanjutkan pelatihan.
Para peneliti sedang menjajaki penggunaan Q-Sparse dengan LLM 1-bit (seperti BitNet b1.58) dan pakar campuran (MoE) untuk lebih meningkatkan efisiensi LLM. Selain itu, mereka berupaya membuat Q-Sparse kompatibel dengan mode batch, yang akan memberikan lebih banyak fleksibilitas untuk pelatihan dan inferensi LLM.
Munculnya teknologi Q-Sparse memberikan ide-ide baru untuk memecahkan masalah efisiensi LLM. Teknologi ini memiliki potensi besar dalam mengurangi biaya komputasi dan penggunaan memori, dan diharapkan dapat mendorong penerapan LLM di lebih banyak bidang. Dipercaya bahwa lebih banyak hasil penelitian berdasarkan Q-Sparse akan muncul di masa depan untuk lebih meningkatkan kinerja dan efisiensi LLM.