Dalam beberapa tahun terakhir, model multimodal besar telah berkembang pesat, dan banyak model unggulan telah bermunculan. Namun, sebagian besar model yang ada mengandalkan encoder visual, yang mengalami masalah bias induksi visual yang disebabkan oleh pemisahan pelatihan, sehingga membatasi efisiensi dan kinerja. Editor Downcodes menghadirkan kepada Anda model bahasa visual baru EVE yang diluncurkan oleh Zhiyuan Research Institute bersama dengan universitas. Model ini mengadopsi arsitektur tanpa kode dan telah mencapai hasil luar biasa dalam berbagai pengujian benchmark, memberikan peluang baru untuk pengembangan model multi-modal. .ide.
Baru-baru ini, kemajuan signifikan telah dicapai dalam penelitian dan penerapan model multimoda besar. Perusahaan asing seperti OpenAI, Google, Microsoft, dll. telah meluncurkan serangkaian model canggih, dan institusi dalam negeri seperti Zhipu AI dan Step Star telah membuat terobosan di bidang ini. Model ini biasanya mengandalkan encoder visual untuk mengekstrak fitur visual dan menggabungkannya dengan model bahasa besar, namun terdapat masalah bias induksi visual yang disebabkan oleh pemisahan pelatihan, yang membatasi efisiensi penerapan dan performa model multi-modal besar.
Untuk mengatasi masalah ini, Zhiyuan Research Institute, bersama dengan Universitas Teknologi Dalian, Universitas Peking, dan universitas lain, meluncurkan generasi baru model bahasa visual bebas kode EVE. EVE mengintegrasikan representasi, penyelarasan, dan inferensi visual-linguistik ke dalam arsitektur dekoder murni terpadu melalui strategi pelatihan yang disempurnakan dan pengawasan visual tambahan. Dengan menggunakan data publik, EVE berkinerja baik pada berbagai tolok ukur visual-linguistik, mendekati atau bahkan mengungguli metode multi-modal berbasis encoder arus utama.
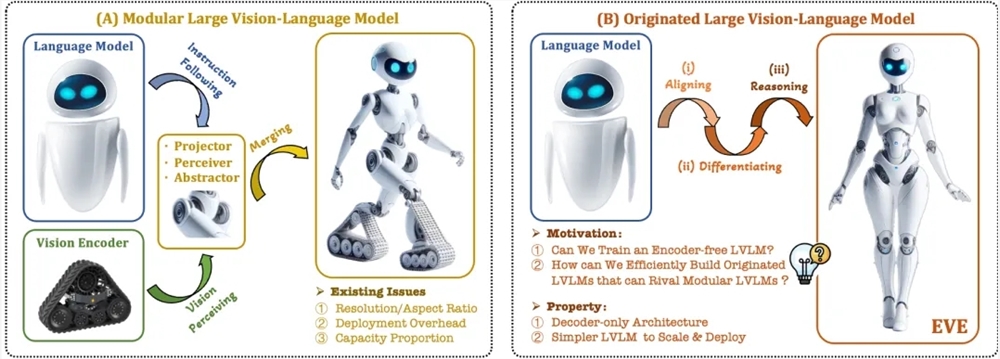
Fitur utama EVE meliputi:
Model bahasa visual asli: menghilangkan encoder visual dan menangani rasio aspek gambar apa pun, yang jauh lebih baik daripada model Fuyu-8B jenis yang sama.
Biaya data dan pelatihan rendah: Pra-pelatihan menggunakan data publik seperti OpenImages, SAM, dan LAION, dan waktu pelatihannya singkat.
Eksplorasi yang transparan dan efisien: Menyediakan jalur pengembangan yang efisien dan transparan untuk arsitektur multi-modal asli decoder murni.
Struktur model:
Lapisan Penyematan Patch: Dapatkan peta fitur 2D gambar melalui lapisan konvolusi tunggal dan lapisan pengumpulan rata-rata untuk menyempurnakan fitur lokal dan informasi global.
Patch Aligning Layer: Mengintegrasikan fitur visual jaringan multi-layer untuk mencapai keselarasan halus dengan output encoder visual.
Strategi pelatihan:
Tahap pra-pelatihan dipandu oleh model bahasa besar: membangun hubungan awal antara visi dan bahasa.
Tahap pra-pelatihan generatif: Meningkatkan kemampuan model dalam memahami konten visual-linguistik.
Fase penyesuaian yang diawasi: mengatur kemampuan model untuk mengikuti instruksi bahasa dan mempelajari pola percakapan.
Analisis kuantitatif: EVE berkinerja baik dalam berbagai tolok ukur bahasa visual dan sebanding dengan berbagai model bahasa visual berbasis encoder arus utama. Meskipun ada tantangan dalam merespons instruksi spesifik secara akurat, melalui strategi pelatihan yang efisien, EVE mencapai kinerja yang sebanding dengan model bahasa visual dengan basis encoder.
EVE telah menunjukkan potensi model bahasa visual asli tanpa encoder. Di masa depan, EVE dapat terus mendorong pengembangan model multi-modal melalui peningkatan kinerja lebih lanjut, optimalisasi arsitektur tanpa encoder, dan konstruksi multi-modal asli. model.
Alamat makalah: https://arxiv.org/abs/2406.11832
Kode proyek: https://github.com/baaivision/EVE
Alamat model: https://huggingface.co/BAAI/EVE-7B-HD-v1.0
Secara keseluruhan, kemunculan model EVE memberikan arah dan kemungkinan baru untuk pengembangan model multimodal besar. Strategi pelatihan yang efisien dan kinerja luar biasa patut mendapat perhatian. Kami menantikan model EVE masa depan yang mampu menunjukkan kemampuannya yang kuat di lebih banyak bidang.