Dalam komunikasi suara real-time, mengubah timbre pembicara tanpa mempengaruhi semantik dan prosodi selalu menjadi masalah teknis. Editor Downcodes akan memperkenalkan teknologi terobosan hari ini - StreamVC, yang dapat mengubah timbre suara pembicara secara real time sambil mempertahankan konten dan ritme suara. Cocok untuk platform seluler dan menyediakan komunikasi real-time dan anonimisasi suara. Latensi rendah StreamVC, sintesis ucapan berkualitas tinggi, dan stabilitas nada memberikan keuntungan signifikan dalam bidang komunikasi waktu nyata.
Dalam dunia komunikasi real-time, baik itu panggilan telepon atau konferensi video, suara adalah alat penting bagi kita untuk mengekspresikan diri. Namun pernahkah Anda berpikir tentang apa yang akan terjadi jika kita dapat mengubah timbre suara pembicara secara real time tanpa mempengaruhi konten dan ritme bahasa? Kemunculan teknologi StreamVC memungkinkan kita melakukan hal ini.
StreamVC adalah solusi konversi suara inovatif yang mencocokkan timbre suara target dengan tetap mempertahankan konten dan prosodi suara sumber. Berbeda dengan metode tradisional, StreamVC menghasilkan bentuk gelombang dengan latensi rendah pada sinyal masukan, bahkan pada platform seluler, sehingga cocok untuk skenario komunikasi real-time seperti panggilan telepon dan konferensi video, serta anonimisasi suara dalam skenario ini.
Sorotan Teknis:
Waktu nyata: StreamVC mampu melakukan inferensi latensi rendah 70,8 milidetik pada perangkat seluler.
Sintesis ucapan berkualitas tinggi: Memanfaatkan arsitektur dan strategi pelatihan codec audio saraf SoundStream untuk mencapai sintesis ucapan yang ringan dan berkualitas tinggi.
Stabilitas nada: Dengan memperkenalkan informasi frekuensi dasar yang diputihkan (f0), konsistensi nada ditingkatkan tanpa membocorkan informasi timbre pembicara sumber.
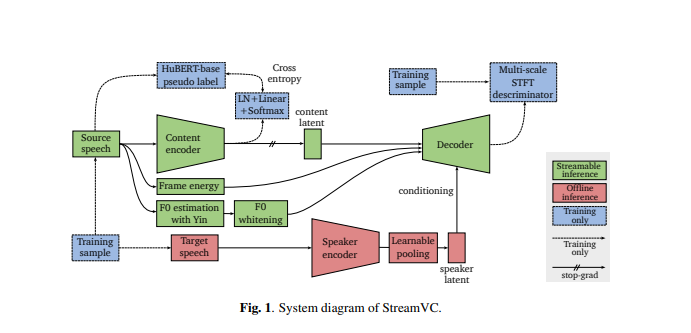
Desain StreamVC terinspirasi oleh Soft-VC dan SoundStream. Ia menggunakan unit ucapan terpisah yang diekstraksi oleh model HuBERT sebagai target prediksi untuk jaringan pembuat enkode konten. Arsitektur encoder dan decoder konten serta strategi pelatihan dirancang dari codec audio saraf SoundStream untuk mencapai sintesis audio kausal berkualitas tinggi.
StreamVC dibandingkan dengan teknologi yang ada berdasarkan berbagai tolok ukur, termasuk kealamian, pemahaman, kesamaan pembicara, dan konsistensi nada. Hasil eksperimen menunjukkan bahwa StreamVC berkinerja baik dalam mempertahankan nada bahasa sumber dan sebanding dengan model yang disempurnakan dalam hal kesamaan pembicara.
StreamVC membuktikan bahwa konversi suara yang efisien dengan latensi rendah pada perangkat seluler sepenuhnya dapat dilakukan. Unit ucapan lembut yang diturunkan dari HuBERT dapat dipelajari melalui arsitektur jaringan saraf konvolusional kausal yang dapat dialirkan, dan memasukkan informasi f0 yang telah diputihkan ke dalam dekoder sangat penting untuk menghasilkan keluaran berkualitas tinggi.
Alamat makalah: https://arxiv.org/pdf/2401.03078
Munculnya teknologi StreamVC telah membawa kemungkinan baru untuk komunikasi suara real-time. Kemampuan konversi suara berlatensi rendah dan berkualitas tinggi akan mendorong penerapan teknologi suara di lebih banyak bidang. Saya yakin di masa depan, StreamVC akan memainkan peran yang lebih besar dalam anonimisasi suara, efek khusus suara, dll. Menantikan aplikasi yang lebih inovatif berdasarkan StreamVC!